注意・免責事項
本記事は情報の提供のみを目的としています。
本記事の内容を実行・適用・運用したことで何が起きようとも、それは実行・適用・運用した人自身の責任であり、著者や関係者はいかなる責任も負いません。
また、本記事の誤りやご指摘がありましたら、コメントに投稿いただきますようお願いいたします。
概要
ユーザー企業がビジネスでChatGPT等の大規模言語モデルを使用する際に注意すべき点を知的財産および個人情報の観点でまとめました。
特に、大規模言語モデルへの入力および出力としての生成物に注目します。OpenAIに習って、ChatGPT等の大規模言語モデルに入力するデータおよび出力されるデータを「コンテンツ」と呼ぶことにします。
本記事では主にユーザー企業が社内でChatGPT等の大規模言語モデルを利用する際の知的財産および個人情報に注目します。システム開発ではセキュリティやSLA等検討すべき観点が他にもありますが、これらについては述べません。
| 観点 | 概要 |
|---|---|
| 入力の知的財産 | ・入力コンテンツは学習されるのか ・第三者の知的財産を入力可能か |
| 出力の知的財産 | ・第三者の知的財産の2次創作になっていないか ・第三者の知的財産でないか |
| 入力の個人情報 | ・サービスの規約として個人情報を入力可能か ・本人から個人情報利用の許諾を受けているか |
| 社内のセキュリティ | ・入出力コンテンツのアクセス権限は適切か |
| 社外サービスのセキュリティ | ・外部サービスのセキュリティは信頼できるか ・インシデント発生時に即応性があるか |
| システムの管理 | ・誰に利用権を付与するか ・情報システム部門との責任分界点をどうするか ・業務部門へのSLAはどうするか |
| 教育 | ・不正利用防止 ・個人で取得したアカウントの禁止 |
| 社外データ利用のポリシーの策定 | ・社外関係者への通知義務 ・社内への通知 |
| 社外への説明 | ・取引先への説明資料の共通化 ・レピュテーションリスクの対応 |
| 料金 | ・API等の利用料金 |
なお、筆者は法律の専門家ではありません。本記事はChatGPT等の大規模言語モデル運用検討のたたき台となる情報の提供を目指すものです。
知的財産権には下図のような種類がありますが、本記事では特に著作権、商標権について述べます。また、個人情報についても注意点を述べたいと思います。

引用元: 特許庁, "知的財産権について", URL
用語
本記事では用語を次のとおり規定します。
| # | 用語 | 説明 |
|---|---|---|
| 1 | ChatGPT | WebブラウザからOpenAIのサイトにアクセスして使用するChatGPTのWebアプリケーションのことを指します。 |
| 2 | (OpenAIが提供する)API以外のサービス | #1およびDALL・E2のWebアプリケーションのことを指します。 |
| 3 | OpenAI API | OpenAIが提供するWeb APIのことで、'23/4/10現在はGPT-3.5やGPT-4等が提供されています。 |
| 4 | Azure OpenAI Service | Microsoft Azureが提供するGPTのWeb APIサービス等を指します。 |
OpenAI利用規約
まず、OpenAIが提供するサービス(ChatGPTおよびOpenAI API)の利用規約を確認します。
3. Content
(a) Your Content. You may provide input to the Services (“Input”), and receive output generated and returned by the Services based on the Input (“Output”). Input and Output are collectively “Content.” As between the parties and to the extent permitted by applicable law, you own all Input. Subject to your compliance with these Terms, OpenAI hereby assigns to you all its right, title and interest in and to Output. This means you can use Content for any purpose, including commercial purposes such as sale or publication, if you comply with these Terms. OpenAI may use Content to provide and maintain the Services, comply with applicable law, and enforce our policies. You are responsible for Content, including for ensuring that it does not violate any applicable law or these Terms.
・・・(中略)・・・
(c) Use of Content to Improve Services. We do not use Content that you provide to or receive from our API (“API Content”) to develop or improve our Services. We may use Content from Services other than our API (“Non-API Content”) to help develop and improve our Services. You can read more here about how Non-API Content may be used to improve model performance. If you do not want your Non-API Content used to improve Services, you can opt out by filling out this form. Please note that in some cases this may limit the ability of our Services to better address your specific use case.引用元: OpenAI, "Terms of use", URL, (閲覧日: 2023/4/3)
重要な要素は次のとおりです。
- 出力に関するすべての権利、所有権、および利益は利用者に譲渡されます。
- APIを経由して送受信するコンテンツはサービスの開発または改善に利用されません。
- API以外のサービス(原文:"Non-API Content", '23/4/10現在はChatGPTおよびDALL·E2のWebアプリケーション)で送受信するコンテンツはサービスの開発または改善に利用されます(つまりデフォルトでオプトイン)。API以外のサービスで入力したデータをサービス改善に利用されたくない場合はオプトアウトを申請できます。
個人情報については次の記載があります。
(c) Processing of Personal Data. If you use the Services to process personal data, you must provide legally adequate privacy notices and obtain necessary consents for the processing of such data, and you represent to us that you are processing such data in accordance with applicable law. If you will be using the OpenAI API for the processing of “personal data” as defined in the GDPR or “Personal Information” as defined in CCPA, please fill out this form to request to execute our Data Processing Addendum.
引用元: OpenAI, "Terms of use", URL, (閲覧日: 2023/4/3)
重要な要素は次のとおりです。
- 個人情報を処理する場合は、法令に従ってプライバシー通知を行い、同意を得る必要があります。また、適用している法令に従って個人情報を処理していることをOpenAI社に表明する必要があります。
プライバシーポリシーも確認しましょう。
1. Personal information we collect
We collect information that alone or in combination with other information in our possession could be used to identify you (“Personal Information”) as follows:Personal Information You Provide: We may collect Personal Information if you create an account to use our Services or communicate with us as follows:
- Account Information: When you create an account with us, we will collect information associated with your account, including your name, contact information, account credentials, payment card information, and transaction history, (collectively, “Account Information”).
- User Content: When you use our Services, we may collect Personal Information that is included in the input, file uploads, or feedback that you provide to our Services (“Content”).
- Communication Information: If you communicate with us, we may collect your name, contact information, and the contents of any messages you send (“Communication Information”).
- Social Media Information: We have pages on social media sites like Instagram, Facebook, Medium, Twitter, YouTube and LinkedIn. When you interact with our social media pages, we will collect Personal Information that you elect to provide to us, such as your contact details (collectively, “Social Information”). In addition, the companies that host our social media pages may provide us with aggregate information and analytics about our social media activity.
引用元: OpenAI, "Privacy policy", URL, (閲覧日: 2023/4/3)
重要な要素は次のとおりです。
- OpenAI社のプライバシーポリシーによると、コンテンツ内に含まれる個人情報も収集されます。
- 個人情報の利用目的には、新しいプログラムやサービスを開発することも含まれています。
- プライバシーポリシーはOpenAI APIを利用した場合には適用されません。詳しくは引用元をご確認ください。
ここで、'23/3/1に追加されたAPIのデータ使用ポリシーについても確認しておきます。
Starting on March 1, 2023, we are making two changes to our data usage and retention policies:
OpenAI will not use data submitted by customers via our API to train or improve our models, unless you explicitly decide to share your data with us for this purpose. You can opt-in to share data.
Any data sent through the API will be retained for abuse and misuse monitoring purposes for a maximum of 30 days, after which it will be deleted (unless otherwise required by law).
(中略)
OpenAI retains API data for 30 days for abuse and misuse monitoring purposes. A limited number of authorized OpenAI employees, as well as specialized third-party contractors that are subject to confidentiality and security obligations, can access this data solely to investigate and verify suspected abuse. OpenAI may still have content classifiers flag when data is suspected to contain platform abuse. Data submitted by the user through the Files endpoint, for instance to fine-tune a model, is retained until the user deletes the file.引用元: OpenAI, "API data usage policies", URL, (閲覧日: 2023/4/11).
重要な要素は次のとおりです。
- APIを通じて送信コンテンツは、不正使用および悪用監視の目的で最大30日間保持され、その後削除されます。
- OpenAIの限られた権限のある従業員、および機密保持とセキュリティの義務を負う専門の第三者の請負業者(これをサブプロセッサと呼ぶ)は、不正使用の疑いを調査および検証するためだけにこのデータにアクセスできます。OpenAI APIを利用する場合、コンテンツはAIの学習には使用されず、OpenAIのサービスの改善のためにも使用されませんが、コンテンツは保存されています。不正利用の可能性があった場合、コンテンツにOpanAIの社員以外の第三者の請負業者もアクセスする場合があることも留意しておきましょう。

引用元: OpenAI, "OpenAI Subprocessor List", URL, (閲覧日: 2023/4/11).
データの保存場所についてはQ&Aに下記の記載があります。
Where is API data stored?
Content is stored on OpenAI systems and our sub-processors’ systems. We may also send select portions of de-identified content to third-party contractors (subject to confidentiality and security obligations) safety purposes. Our 30-day data retention policy also applies to our sub-processors and contractors. You can view our list of sub-processors and their locations for details.
(中略)
Do you have a European data center?
All customer data is processed and stored in the US. We do not currently store data in Europe or in other countries.引用元: OpenAI, "API data usage policies", URL, (閲覧日: 2023/4/11).
重要な要素は次のとおりです。
- コンテンツはOpenAIのシステムおよびサブプロセッサのシステムに保存されます。
- 全ての顧客情報は米国のデータセンターに保存されます。
- 以上2点から、基本的にデータは米国に保存され、不正利用の可能性があった場合にはサブプロセッサのシステムに保存されるようです。サブプロセッサのデータセンターがどこにあるかは不明です。また、「顧客情報」の用語の定義がないため、コンテンツを含むかは不明です。
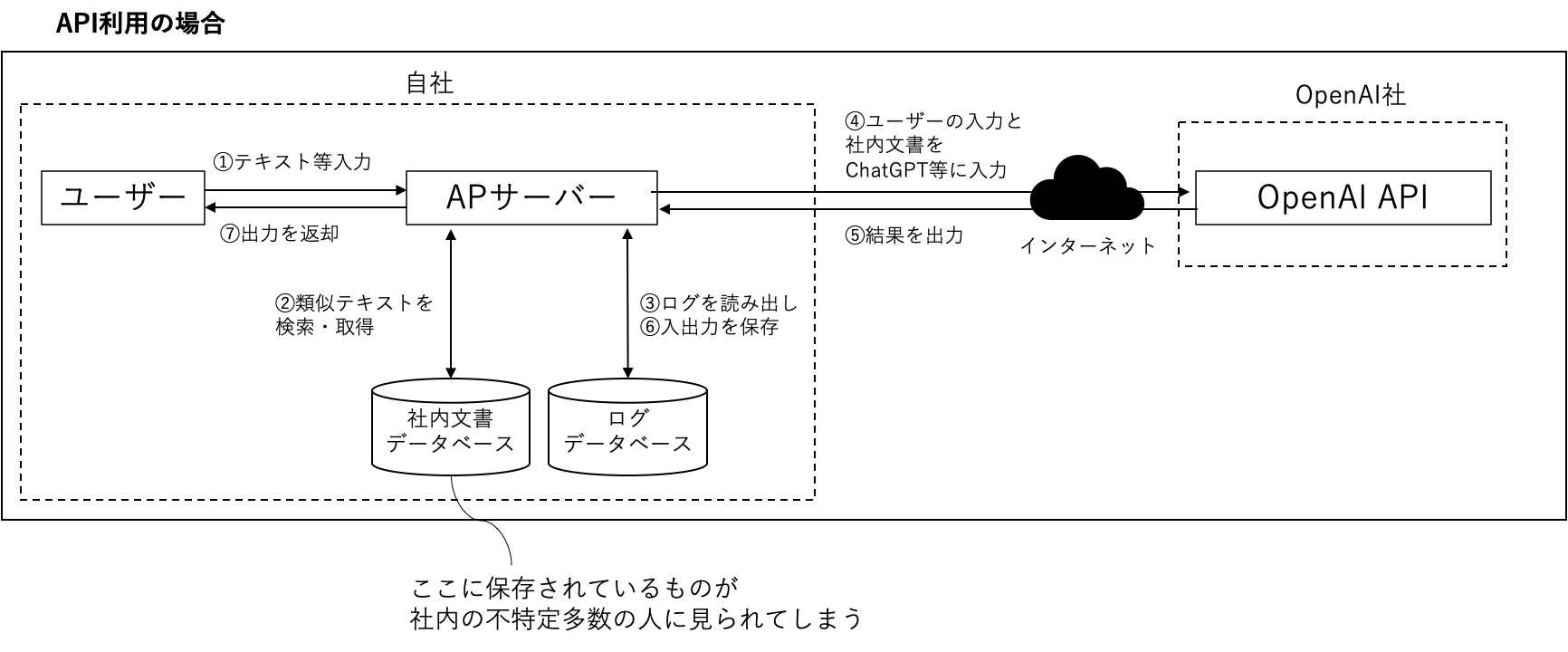
大規模言語モデルサービスを活用した典型的なシステム例を下図に示します。ChatGPTを利用する場合は、ユーザーの過去の入出力がOpenAI社で保存されており、サービスの開発または改善に使用されます。OpenAI APIを利用する場合は、APIがステートレスのため、自社でアプリケーション・サーバー等を用意し、ユーザーの過去の入出力を保存したり、検索したい社内文書データベースと連携させたりします。

以上の利用規約を踏まえ、ChatGPT等の大規模言語モデルをビジネスで使うときの注意点を検討します。
知的財産に関する注意点
著作権・商標権に関する注意点
入力に関する注意点
第三者の著作物の入力

第三者の著作物をChatGPTに入力してしまうと、OpenAI社のサーバーに記録されるため、これは著作物の複製に該当します。しかし、適法利用の範囲であれば電子計算機における著作物の利用に伴う複製(著作権法第四十七条の四)とみなされて適法になるようです。
では、適法利用の範囲とはなんでしょうか?例えば、機械学習関連で話題になる著作権法第三十条の四を確認してみます。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合引用元: 著作権法(明治三十二年法律第三十九号), URL, (閲覧日: 2023/4/2).
機械学習を行う際のデータの取り扱いでよく参照される条文です。ChatGPTをあくまで情報解析に利用すると考えれば、著作者の許諾を得ずに著作物を利用できそうに思えます。
私見ですが、プロンプトエンジニアリングを行って入力テキストを整形したり、要素を抽出したり、分類したりする分には情報解析に思えます。一方で、入力テキストを改変して新たな文を作成し、要約を公開したり書籍を販売したりすると、情報解析でなく2次創作のように思えます。
また、API以外のサービスを利用する場合に著作物を入力してしまうとOpenAI社のAIの学習に利用されてしまいます。すると、第三者が著作物を閲覧できる可能性があるため、公衆送信権を侵害してしまうのではないでしょうか?
ChatGPT等の大規模言語モデルへの入力に関する議論はまだ進んでいないように思われます。利用の際は十分注意が必要です。
第三者の著作物の社内共有
現在のChatGPTやOpenAI APIでは一回の通信で入力可能なデータ量に制限があります。そこで、社内に別途サーバーを構築してデータベース化し、データベース内の検索と組み合わせることが考えられます。このデータベースに第三者の著作物を複製してしまう可能性があります。誰かが購入した著作物をデータベースに保存して、社内の他の人が見られるような状態になっていると、譲渡権や複製権を侵害する可能性があります(参考URL)。
出力に関する注意点
第三者の著作物を要約・翻訳
第三者の著作物を翻訳・編曲・変形・脚色・映画化等し、二次的著作物を創作する行為は、著作者の了解を得なければなりません。これを怠ると翻訳権、翻案権等の侵害になります。
自然言語系AIサービスの著作権については次の記事が詳しいです。
記事内の「8 非権利者による著作物の入力→著作物」に詳細がありますが、翻案主体はユーザーになると考えられるようです。私的利用の範囲では適法の可能性がありますが、事業者が事業として活用する場合は著作権侵害になると考えられます。
要約や翻訳はChatGPTの得意なタスクであり、多用されると考えられますので十分注意が必要です。
出力したものが第三者の著作物だった
生成モデルはその性質上、学習に使用したデータをそのまま出力する可能性があります。生成した文が著作物であった場合、その著作物を利用する場合はもちろん著作権に従う必要があります。
プログラムのソースコードは著作物なので、著作権で保護されます。出力されたソースコードが公開されており、ライセンスされている場合は、そのライセンスに従う必要があると考えられます。GPLライセンス等のコピーレフトライセンスの場合は影響が大きい可能性があるので注意が必要です。また、ソースコードにライセンスが付与されていない場合は、著作権者に使用する了解を得る必要があります。
出力したものが第三者の著作物に類似
この場合は第三者の著作物を翻訳・編曲・変形・脚色・映画化等し、二次的著作物を創作する行為をみなされる可能性があります。
二次的著作物かどうかは依拠性によって判断されます。自分の著作物が第三者の著作物に依拠しているかの司法の判断は一般の感覚と異なると思われますので、安易な判断はNGです。
下図は左が「既存のイラスト」、右が「新しく作成されたイラスト」です。著作権侵害が否定された例です。

下図は左が「既存のイラスト」、右が「新しく作成されたイラスト」です。著作権侵害が肯定された例です。

これら上図2つは下記サイトから引用しました。私には著作権侵害の基準は難しいです。
西川暢春, "イラストや画像の著作権侵害の判断基準は?どこまで類似で違法?", URL, (閲覧日: 2023/4/10).
また、著作物の偶然の一致で、偶然類似したものが出力された可能性もあります。この場合の依拠性はAIの学習データに類似のテキストが含まれていたかどうかで判断されるのでしょうか?もしそうであれば、AIの学習に利用されたデータに類似のものがないかを全件確認する必要があり、非常に大きな労力がかかります。
情報提供頂いた@tenmyo様ありがとうございました。
出力したものが第三者の商標
ChatGPT等の大規模言語モデルを使用して商品名等のアイデア出しを行うことが考えられます。このとき、'23/4/10現在で提供されているChatGPT、OpenAI API、Azure OpenAI Serviceは商標かどうかを判定する機能を持っておりませんので、第三者の商標権を侵害していないか確認が必要です。
不正競争防止法に関する注意点
社外秘情報や営業秘密の入力
ChatGPTに入力した内容はオプトアウトしない限りAIの学習に利用されます。そのため、社外秘情報や営業秘密を入力してしまうと、第三者に漏洩し不正競争防止法に違反する可能性があります。
Amazon社では、ChatGPTが社外秘であるはずのデータに非常に似た出力をしたとのことで、緊張感が高まっているようです。
Samsung社では実際に社内情報の漏洩があったようです。
社外秘の情報を入力したい場合は、包括的なセキュリティとコンプライアンスの組み込みに取り組んでいるMicrosoftのAzure OpenAI Serviceを利用できると思います。
ただし、営業秘密に該当する情報は、秘密管理性を認められる必要があります。
参考: 経済産業省, "営業秘密管理指針", URL, 平成27年1月28日, (閲覧日: 2023/4/2).
'23/4/10現在のChatGPTやAzure OpenAI Serviceで秘密管理性の要件を満たせるかは分かりません。ファイルではないのでマル秘の付与はできませんが、Azure OpenAI Serviceはデータの暗号化やアクセス管理が設定できます。
参考: Microsoft, "Azure OpenAI Service による保存データの暗号化", URL, (閲覧日: 2023/4/2).
Azure OpenAI Serviceのデータポリシーを確認しましょう。
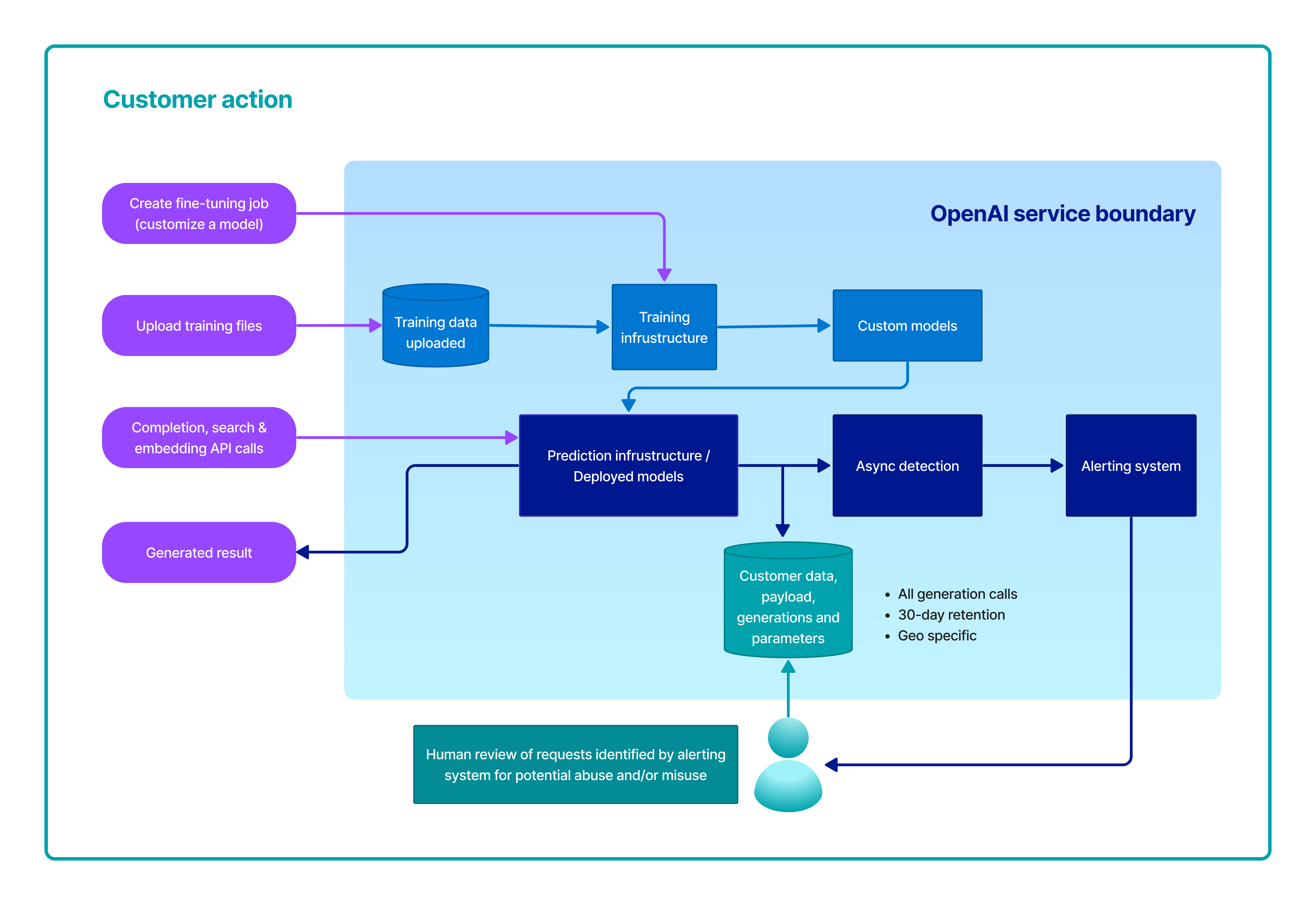
Training data for purposes of fine-tuning an OpenAI model
The training data (prompt-completion pairs) submitted to the Fine-tunes API through the Azure OpenAI Studio is pre-processed using automated tools for quality checking including data format check. The training data is then imported to the model training component on the Azure OpenAI platform. During the training process, the training data are decomposed into batches and used to modify the weights of the OpenAI models.Training data provided by the customer is only used to fine-tune the customer’s model and is not used by Microsoft to train or improve any Microsoft models.
・・・(中略)・・・
Abuse and harmful content generation
The Azure OpenAI Service stores prompts & completions from the service to monitor for abusive use and to develop and improve the quality of Azure OpenAI’s content management systems. Learn more about our content management and filtering. Authorized Microsoft employees can access your prompt & completion data that has triggered our automated systems for the purposes of investigating and verifying potential abuse; for customers who have deployed Azure OpenAI Service in the European Union, the authorized Microsoft employees will be located in the European Union. This data may be used to improve our content management systems.In the event of a confirmed policy violation, we may ask you to take immediate action to remediate the issue to and to prevent further abuse. Failure to address the issue may result in suspension or termination of Azure OpenAI resource access.
引用元: Microsoft, "Data, privacy, and security for Azure OpenAI Service", URL, (閲覧日: 2023/4/3)
Azure OpenAI Serviceにはファインチューニング機能が用意されており、自社だけのAIを作成することが可能なようです。ファインチューニングに使用した学習データは、Microsoftが保有する共通のモデル(原文: Microsoft model)の学習には利用されないようです。
一方で、Azure OpenAI Serviceは入力と出力を保存し、不正使用の監視とAzure OpenAI Serviceのコンテンツ管理システムの品質改善の開発に利用するようです。不正使用のアラートが発報されたコンテンツに対しては、内容を人間が確認するようです。さすがにMicrosoftがコンテンツを悪用することは無いかと思いますが、留意しておきましょう。
人間によるコンテンツの監視をオプトアウト出来るか確認しましょう。
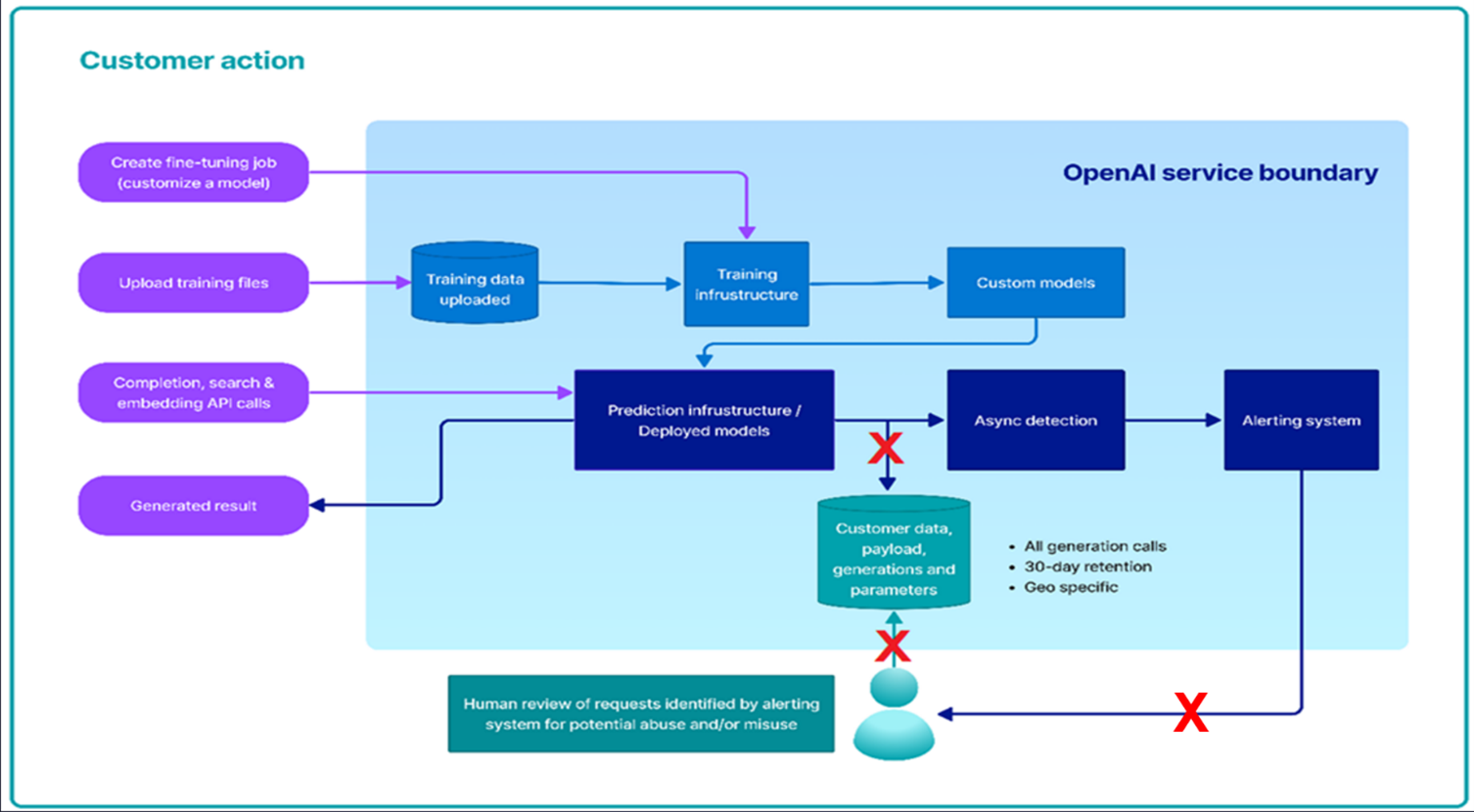
Can a customer opt out of the logging and human review process?
Some customers in highly regulated industries with low risk use cases process sensitive data with less likelihood of misuse. Because of the nature of the data or use case, these customers do not want or do not have the right to permit Microsoft to process such data for abuse detection due to their internal policies or applicable legal regulations.To empower its enterprise customers and to strike a balance between regulatory / privacy needs and abuse prevention, the Azure Open AI Service will include a set of Limited Access features to provide potential customers with the option to modify following:
- abuse monitoring
- content filtering
These Limited Access features will enable potential customers to opt out of the human review and data logging processes subject to eligibility criteria governed by Microsoft’s Limited Access framework. Customers who meet Microsoft’s Limited Access eligibility criteria and have a low-risk use case can apply for the ability to opt-out of both data logging and human review process. This allows trusted customers with low-risk scenarios the data and privacy controls they require while also allowing us to offer AOAI models to all other customers in a way that minimizes the risk of harm and abuse.
If Microsoft approves a customer’s request to access Limited Access features with the capability to (i) modify abuse monitoring and (ii) modify content filtering, then Microsoft will not store the associated request or response. Since no request or response data will be stored at rest in the Service Results Store in this case, the human review process will no longer be feasible. Therefore, both CMK and Lockbox will be deemed out-of-scope for harm and abuse detection.
引用元: Microsoft, "Data, privacy, and security for Azure OpenAI Service", URL, (閲覧日: 2023/4/3)
不正使用の監視と人間による確認は、Microsoftが提供する制限付きアクセス機能の資格を有し、不正利用の可能性が低いユースケースの場合のみオプトアウトできるようです。
秘密保持契約を結んだ情報を社内で共有
秘密保持契約を結んだ情報は関係者外秘の情報で、例え社内であっても関係者以外に共有してはいけません。また、目的外利用もNGですので、秘密保持契約で保護される情報は入力すべきでないでしょう。
💡情報を区分管理する
社内の情報は機密度で管理されていると思います。これらの区分を拡張して、ChatGPT等の大規模言語モデルへ入力して良い情報区分を策定するのがよいのではないでしょうか。一般文書、社外秘文書までが入力可能な区分でしょうか。個人情報と組み合わせた区分も検討した方が良さそうです。

引用元: ALSOK, "機密とは?情報漏えいを防ぐために企業が取り組むべき管理方法", URL, (閲覧日: 2022/8/15)
なお、ALSOKが引用しているIPAの資料は例のアレでリンクが切れています。WARPのリンクはこちら。
💡バグやサイバー攻撃等にも注意
ChatGPTではシステムのバグにより一時的に第三者のチャット履歴が見えてしまう状況にありました。
意図しない情報漏えいはバグやサイバー攻撃等によって起きる可能性もあります。AIの学習に利用されないからといって必ず漏洩しないわけではありません。サービス利用の際には十分信頼できるパートナーを選ぶ必要もあります。
個人情報保護法に関する注意点
個人情報の入力
OpenAI社の利用規約としては、適切に手続きをしていれば個人情報を入力できます。
個人情報を利用する場合は個人情報保護法に従い、本人の同意を得る等適切な対応が必要になります。
個人情報を含むシステムと連携
個人情報が含まれるようなデータベースを社内文書データベースとして連携してしまうと、個人情報が出力されてしまう可能性があります。連携するシステムやデータベースにどのようなデータが含まれているか注意が必要です。
💡保存したプロンプトログに個人情報が含まれていたら?
大規模言語モデルを利用するシステムを開発する際、コンテキストを保存したり、入出力をトレースしたりできるように別途データベースに入力と出力のログを保存することが考えられます。
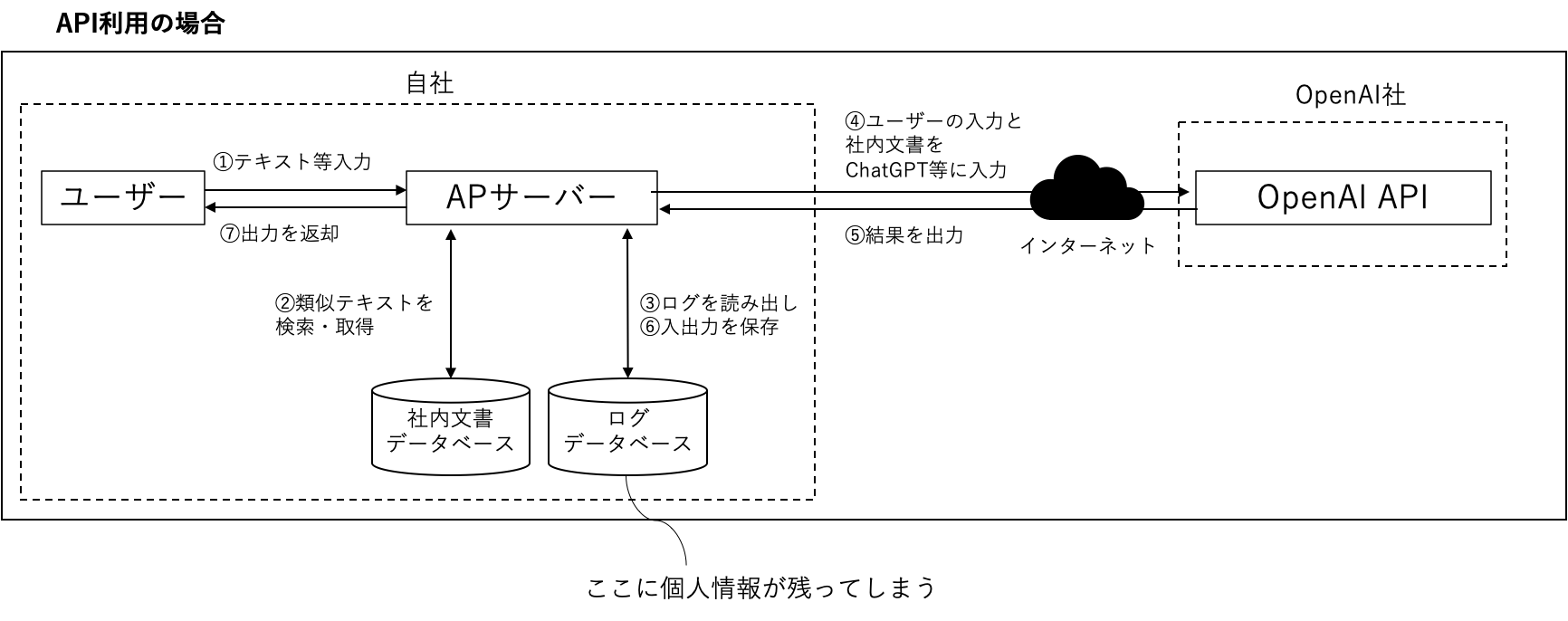
個人情報を入力してしまった際、このプロンプトログは個人情報として対応が必要でしょうか?これは「個人情報データベース等」に該当するかで判断できます。
2-4 個人情報データベース等(法第16条第1項関係)
・・・(中略)・・・
【個人情報データベース等に該当する事例】
事例 1)電子メールソフトに保管されているメールアドレス帳(メールアドレスと氏名を組み合わせた情報を入力している場合)
事例 2)インターネットサービスにおいて、ユーザーが利用したサービスに係るログ情報がユーザーID によって整理され保管されている電子ファイル(ユーザーID と個人情報を容易に照合することができる場合)
事例 3)従業者が、名刺の情報を業務用パソコン(所有者を問わない。)の表計算ソフト
等を用いて入力・整理している場合
事例 4)人材派遣会社が登録カードを、氏名の五十音順に整理し、五十音順のインデック
スを付してファイルしている場合引用元: 個人情報保護委員会, "個人情報の保護に関する法律についてのガイドライン(通則編)", URL, (閲覧日: 2023/4/3)
上記の例は事例2に該当すると考えられるので、個人情報データベース等に該当し、適切に個人情報を管理する必要があると考えます。
準拠法について
ここまで検討した事例については、加害行為地・結果発生地が日本であると思われますので、基本的には準拠法は日本法になると思います。しかし、事例によっては海外のサービスも当事者に含まれ、その場合どの国の準拠法を適用するか自明ではないので、注意が必要です。
参考: 山口敦子, "インターネットを介した著作権侵害と国際私法", URL, (2020年1月14日)
海外の法令に関する注意点
サーバ設置場所・輸出
入力したデータがどの国のサーバに保管されるかは注意が必要です。当該国の法令に適切に従う必要があります。海外に技術情報を送信する場合は輸出に該当する場合もあるので注意が必要です。
EU一般データ保護規則(GDPR)・カリフォルニア州のプライバシー権法(CPRA)
GDPRはEU圏内外への個人データの送信を厳しく制限しており、罰金の額も大きいため注意が必要です。CPRAも別途対応が必要です。
所感
ChatGPTはとても便利です。しかし、我々が入力する文は誰かが作ったものでもあります。取引先の資料や本、プログラムのドキュメント等、想像以上に入力するデータに対してはセンシティブに確認する必要がありそうです。
その他読んでおきたい記事
その他著作権一般については、文化庁のテキストが詳しく、分かりやすいです。
参考: 文化庁, "令和4年度著作権テキスト", URL, (閲覧日: 2023/4/3)