はじめに
2019年終わりから2020年頭くらい?にTarget Encodingが話題になったような記憶があります。
Target Encodingはカテゴリ変数を目的変数の平均値で置き換えるわけですが、単純に処理してしまうとリークが発生してしまうので、工夫をする必要があります。リークを防ぐために変換対象の行以外の平均値を用いるLeave One Outの方法や、K-foldで分けて対象業が含まれるfold以外の平均値で置き換えるといった対策がとられます。
Target Encodingの解説は世にたくさん出ているのでこの記事では解説はしません(例えばこちらのサイトがとても参考になります)。
この記事ではこちらのサイトの素晴らしいTarget Encodingのコードを実際に使用して、動きを確かめることをやってみようと思います。
参考
- Python: Target Encoding のやり方について(https://blog.amedama.jp/entry/target-mean-encoding-types#Leave-one-out-TS-%E4%BD%BF%E3%81%A3%E3%81%A1%E3%82%83%E3%83%80%E3%83%A1)
- K-Fold Target Encoding(https://medium.com/@pouryaayria/k-fold-target-encoding-dfe9a594874b)
手順
サンプルデータフレーム
サンプルのデータフレームを作成する関数です。
import numpy as np
import pandas as pd
def getRandomDataFrame(data, numCol):
if data== 'train':
key = ["A" if x ==0 else 'B' for x in np.random.randint(2, size=(numCol,))]
value = np.random.randint(2, size=(numCol,))
df = pd.DataFrame({'Feature':key, 'Target':value})
return df
elif data=='test':
key = ["A" if x ==0 else 'B' for x in np.random.randint(2, size=(numCol,))]
df = pd.DataFrame({'Feature':key})
return df
else:
print(';)')
次のコードでデータフレームを生成できます。一つ目の引数にtestを指定すると目的変数列が出力されなくなります。二つ目の引数に行数を指定します。
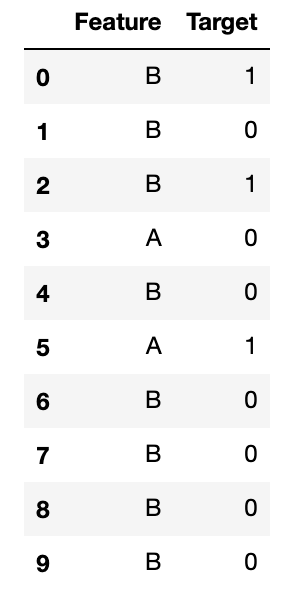
train = getRandomDataFrame('train', 10)
test = getRandomDataFrame('test', 10)
中身は下図のようになっています。

K-fold Target Encoding
K-fold Target Encodingをするクラスです。fitとtransformを持っているので、sklernのpreprocessingと同じように使用できます。Testのエンコーダーは、trainデータの結果をインプットにして、Target Encoding特徴量を付加しています。
また、コメントで書いた(1)の部分は、K-foldした際にnanになってしまう行に対して、平均値で埋める処理をしています。これは後で確認します。
from sklearn import base
from sklearn.model_selection import KFold
class KFoldTargetEncoderTrain(base.BaseEstimator,
base.TransformerMixin):
"""How to use.
targetc = KFoldTargetEncoderTrain('Feature','Target',n_fold=5)
new_train = targetc.fit_transform(train)
"""
def __init__(self,colnames,targetName,
n_fold=5, verbosity=True,
discardOriginal_col=False):
self.colnames = colnames
self.targetName = targetName
self.n_fold = n_fold
self.verbosity = verbosity
self.discardOriginal_col = discardOriginal_col
def fit(self, X, y=None):
return self
def transform(self,X):
assert(type(self.targetName) == str)
assert(type(self.colnames) == str)
assert(self.colnames in X.columns)
assert(self.targetName in X.columns)
mean_of_target = X[self.targetName].mean()
kf = KFold(n_splits = self.n_fold,
shuffle = False, random_state=2019)
col_mean_name = self.colnames + '_' + 'Kfold_Target_Enc'
X[col_mean_name] = np.nan
for tr_ind, val_ind in kf.split(X):
X_tr, X_val = X.iloc[tr_ind], X.iloc[val_ind]
X.loc[X.index[val_ind], col_mean_name] = X_val[self.colnames].map(X_tr.groupby(self.colnames)[self.targetName].mean())
X[col_mean_name].fillna(mean_of_target, inplace = True) # nanになってしまったところは平均値で埋める --(1)
if self.verbosity:
encoded_feature = X[col_mean_name].values
print('Correlation between the new feature, {} and, {} is {}.'.format(col_mean_name,self.targetName,
np.corrcoef(X[self.targetName].values,encoded_feature)[0][1]))
if self.discardOriginal_col:
X = X.drop(self.targetName, axis=1)
return X
class TargetEncoderTest(base.BaseEstimator, base.TransformerMixin):
"""How to use.
test_targetc = TargetEncoderTest(new_train,
'Feature',
'Feature_Kfold_Target_Enc')
new_test = test_targetc.fit_transform(test)
"""
def __init__(self,train,colNames,encodedName):
self.train = train
self.colNames = colNames
self.encodedName = encodedName
def fit(self, X, y=None):
return self
def transform(self,X):
mean = self.train[[self.colNames, self.encodedName]].groupby(self.colNames).mean().reset_index()
dd = {}
for index, row in mean.iterrows():
dd[row[self.colNames]] = row[self.encodedName]
X[self.encodedName] = X[self.colNames]
X = X.replace({self.encodedName: dd})
return X
次のように使います。KFoldTargetEncoderTrainのコンストラクタにはエンコードするカテゴリ変数列名、目的変数列名、fold数を指定します。TargetEncoderTestのコンストラクタにはエンコードしたデータフレーム、エンコードしたカテゴリ変数列名、Target Encodingした特徴量列名([エンコードするカテゴリ変数列名]_Kfold_Target_Enc)を指定します。
targetc = KFoldTargetEncoderTrain('Feature','Target',n_fold=5)
new_train = targetc.fit_transform(train)
test_targetc = TargetEncoderTest(new_train, 'Feature', 'Feature_Kfold_Target_Enc')
new_test = test_targetc.fit_transform(test)
それぞれ次のような中身になっています。
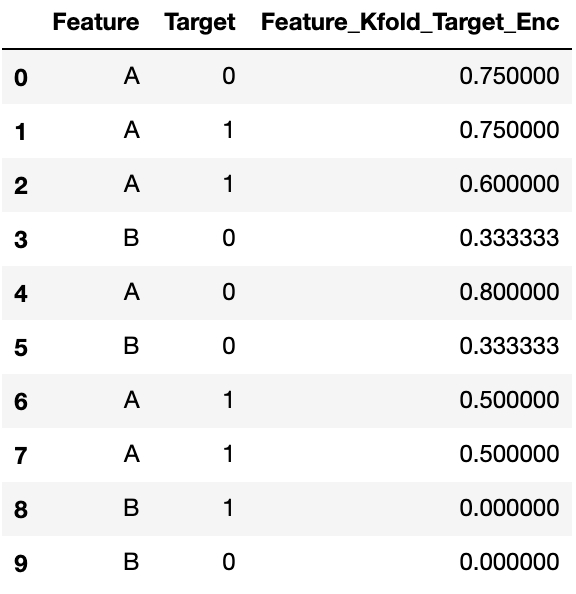
new_trainを確認してみます。5-foldなので、データは2行ずつ、5つのfoldに分割されます。一つ目のfoldは上から一行目と二行目です。一行目と二行目をエンコードするために、他の四つのfoldを合わせたデータ、つまり3行目から10行目のレコードに注目します。AとBそれぞれのグループでのTargetの平均値は、Aの方は3/4=0.75、Bの方は1/4=0.25になります。この値を用いて、一つ目のfoldの値をエンコードします。一つ目のfoldである一行目と二行目はどちらもAなので、0.75でエンコードします。以上の手続きをすべてのfoldで実施します。
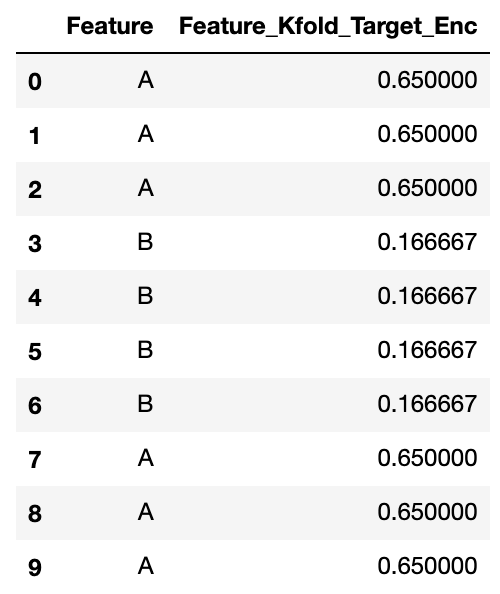
new_testを確認してみます。Testデータのエンコーディングは、TrainデータのTarget Encoding特徴量をエンコード対象のカテゴリ変数の平均値で行います。Aは(0.75+0.75+0.6+0.8+0.5+0.5)/6=0.65、Bは(0.3333333333333333+0.3333333333333333+0.0+0.0)/4=0.16666666666666666となります。
次に、nanになるケースを考えてみます。
train = getRandomDataFrame('train', 10)
train['Feature'].iloc[0] = "C"
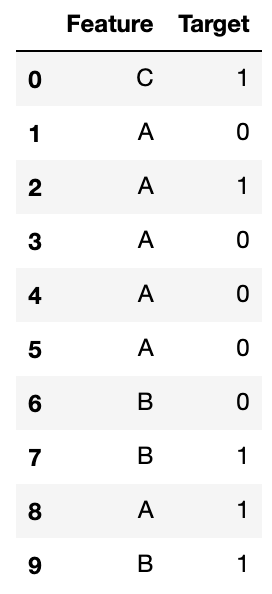
このデータだと、一行目のエンコードをするために残りのfoldでCグループの平均値を計算する必要がありますが、残りのfoldにCがありません。したがってTarget Encoding特徴量がnanになってしまいます。そこで、全行の目的変数の平均値で埋めます。したがってCは、(1+0+1+0+0+0+0+1+1+1)/10=0.5になります。
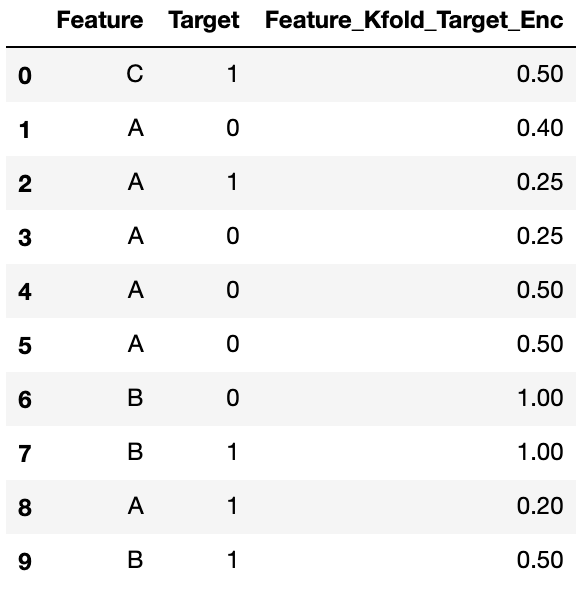
ちなみに、(1)の部分をコメントアウトすると、np.nanのままに出来ます。LightGBMではnanのままでも学習、予測が出来るので平均値で埋めないほうが良い場合があるかもしれません。
Leave-one-out Target Encoding
こちらの手法はK-fold Target Encodingに比べ、リークが大きいので使用すべきでないと言われています。が、せっかくなのでコードを載せておきます。
class LOOTargetEncoderTrain(base.BaseEstimator,
base.TransformerMixin):
"""How to use.
targetc = LOOTargetEncoderTrain('Feature','Target')
new_train = targetc.fit_transform(train)
"""
def __init__(self,colnames,targetName,
verbosity=True, discardOriginal_col=False):
self.colnames = colnames
self.targetName = targetName
self.verbosity = verbosity
self.discardOriginal_col = discardOriginal_col
def fit(self, X, y=None):
return self
def transform(self,X):
assert(type(self.targetName) == str)
assert(type(self.colnames) == str)
assert(self.colnames in X.columns)
assert(self.targetName in X.columns)
col_mean_name = self.colnames + '_' + 'Kfold_Target_Enc'
X[col_mean_name] = np.nan
self.agg_X = X.groupby(self.colnames).agg({self.targetName: ['sum', 'count']})
X[col_mean_name] = X.apply(self._loo_ts, axis=1)
return X
def _loo_ts(self, row):
group_ts = self.agg_X.loc[row[self.colnames]]
loo_sum = group_ts.loc[(self.targetName, 'sum')] - row[self.targetName]
loo_count = group_ts.loc[(self.targetName, 'count')] - 1
return loo_sum / loo_count
おわりに
今回はK-Fold Target Encodingを試してみました。
目的変数が二値の場合はスムーシングといった、さらに過学習を防ぐ手法もあるようです。