はじめに
時系列予測にはBox–Jenkins法や状態空間モデルなど統計的なモデルが複数ありますが、テーブルデータに強いLightGBMでもやって見ようと思いました。
時系列データをLightGBMに食わせるにはデータの変換が必要です。精度の追求はせず、データ加工の手順について書こうと思います。
データはAirPassengersを使用します。
環境
- google colab
手順
データの準備
以降の節でいくつかの変換手法を試していますが、下記ライブラリ、データの読み込みがされている前提とします。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
from sklearn.model_selection import *
# !wget "https://www.analyticsvidhya.com/wp-content/uploads/2016/02/AirPassengers.csv"
dateparse = lambda dates: pd.datetime.strptime(dates, '%Y-%m')
df = pd.read_csv('AirPassengers.csv', index_col='Month', date_parser=dateparse, dtype='float')
一期先予測
これはリアルタイムに近い予測です。どういうことかというと、予測器を訓練したあと、テストデータとして、毎期の観測値を使用します。実用上は予測→結果が当たろうが外れようが、次の予測には最新の観測値を使用します。
値の履歴
特徴量を作っていきます。
データに存在する12ヶ月の周期性は何らかの方法で推定できたとします。
過去12ヶ月の履歴を入力とし、13ヶ月目を予測するとしましょう。pandas.Series.shiftでデータを時間方向にずらします。
for i in range(1, 13):
df['shift%s'%i] = df['#Passengers'].shift(i)
データの先頭と末尾を見てみます。
pd.concat([df.head(13), df.tail(3)], axis=0, sort=False)
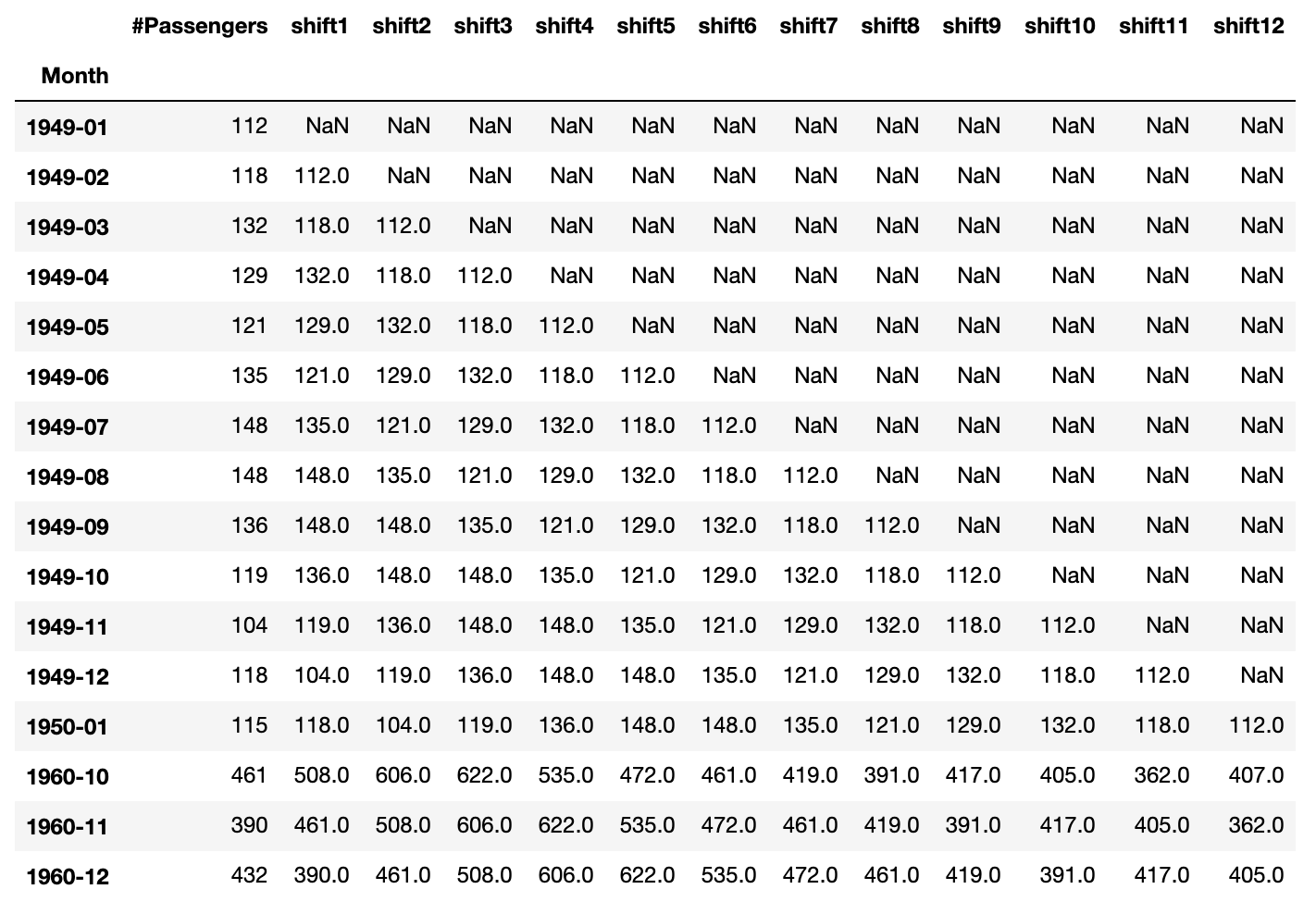
データが下方向にずれ、右から左に向けてデータが並ぶようになります。下にずらしたので、データがない部分がNaNとなり、データの型もfloatになっています。NaNの部分は後でdropします。
1950-01の行を見てください。これ以降が訓練とテストに使用するデータです。shift1~shift12を説明変数として、目的変数#Passengersを予測します。
微分の履歴
時系列データでは、変数の時間変化の特徴を取りこみたいので、履歴の値に加えて微分も特徴量としてみます。高々2階微分までで良いとしましょう。
データは離散化されているので、微分は差分になります。そこで差分列を作ります。pandas.Series.diffを使用します。shift1に対して操作するのがポイントです。
df['deriv1'] = df['shift1'].diff(1)
データを見てみます。
df[['#Passengers', 'deriv1']].head(5)
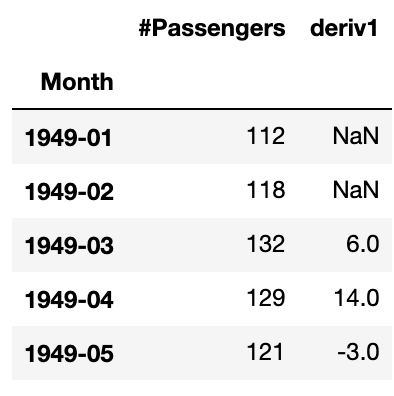
例えば、1949-03を予測するときには1949-02までのデータしかないので、1949-03の行は1949-02から1949-01の値を引いた$118-112=6$が入ります。
二階微分はpandas.Series.diffを二階作用させます。
df['deriv2'] = df['shift1'].diff(1).diff(1)
データを見てみます。
df[['#Passengers', 'deriv1', 'deriv2']].head(5)
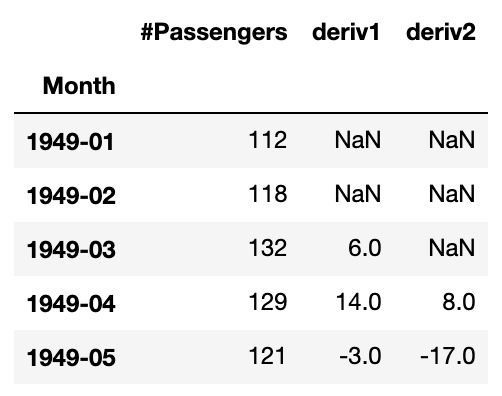
二階微分の差分版は、例えば1949-04の行は$132-2 \times 118+112 = 8$となります。
移動○○値
過去12ヶ月の平均値も特徴量として使ってみます。pandas.Series.rollingを使用します。
df['mean'] = df['shift1'].rolling(12).mean()
データを見てみます。
df[['#Passengers', 'shift1', 'mean']].head(15)
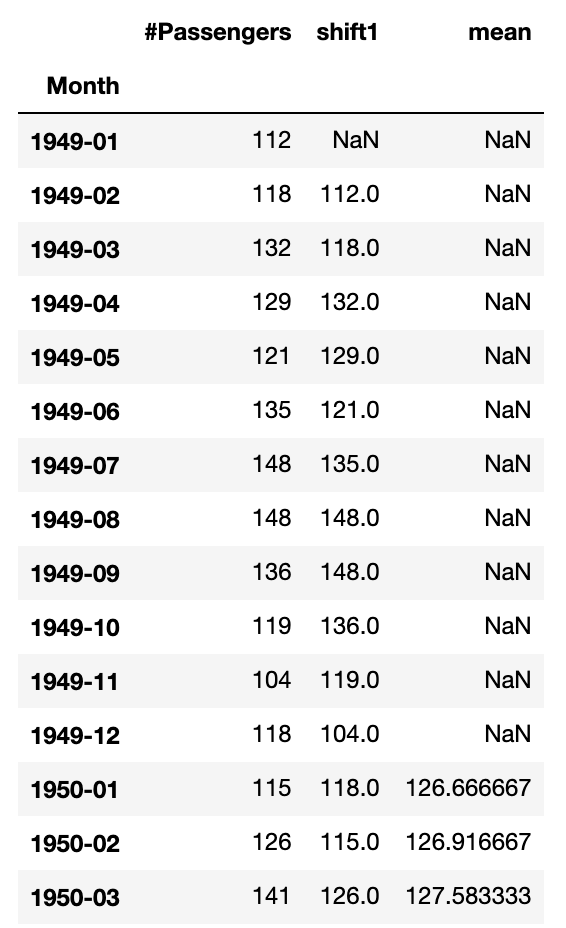
同様にして中央値や最大値、最小値もつくれます。
df['median'] = df['shift1'].rolling(12).median()
df['max'] = df['shift1'].rolling(12).max()
df['min'] = df['shift1'].rolling(12).min()
学習
学習していきます。実験なのでパラメータ等は適当です。
df = df.dropna()
X = df.drop('#Passengers', axis=1)
y = df['#Passengers']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.2, shuffle=False)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_validation, y_validation, reference=lgb_train)
# LightGBM parameters
params = {
'task' : 'train',
'boosting':'gbdt',
'objective' : 'regression',
'metric' : {'mse'},
'num_leaves':78,
'drop_rate':0.05,
'learning_rate':0.01,
'seed':0,
'verbose':0,
'device': 'cpu'
}
evaluation_results = {}
gbm = lgb.train(params,
lgb_train,
num_boost_round=100000,
valid_sets=[lgb_train, lgb_eval],
valid_names=['Train', 'Valid'],
evals_result=evaluation_results,
early_stopping_rounds=1000,
verbose_eval=100)
予測
テストデータの予測をプロットしてみます。
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_ = np.concatenate([np.array([None for i in range(len(y_train)+len(y_validation))]) , y_pred])
y_ = pd.DataFrame(y_, index=X.index)
plt.figure(figsize=(10,5))
plt.plot(y, label='original')
plt.plot(y_, '--', label='predict')
plt.legend()
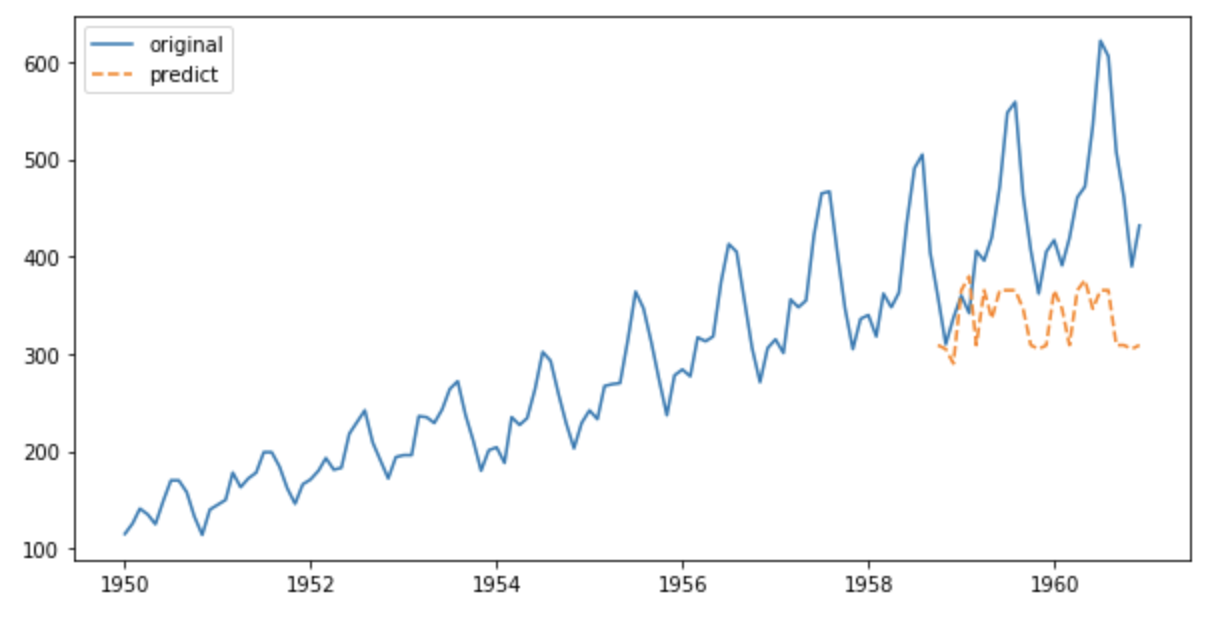
。。。微妙な結果となりました。
ダイナミカルな予測
一期先予測ではテストデータに観測値を使用しましたが、ダイナミカルな予測では、テストデータの一つ目で予測した値を次の説明変数に使用し予測、予測値を次の説明変数に、、、と再帰的に予測していきます。
前節の予測の前まで同じ手順です。
予測
予測値を再帰的に予測器に入力するので、予測値をもとに再度特徴量を作る必要があります。
まず、テストデータの1行目をdataとします。
テストデータ1行目のうち、yの履歴部分をvalとします。
微分特徴量の計算のためにテストデータから1期前と2期前のyをy_backward1、y_backward2とします。
data = X_test.iloc[0, :]
data_index = data.index
val = X_test[['shift1', 'shift2', 'shift3', 'shift4', 'shift5', 'shift6', 'shift7', 'shift8', 'shift9', 'shift10', 'shift11', 'shift12']].iloc[0].values
y_backward1 = y_validation[-1]
y_backward2 = y_validation[-2]
dataを予測器に入力し予測値を出します。予測値はリストに格納しておきます。
valをシフトしてNaNを予測値で埋めることでyの履歴を一期ずらします。
valから統計量を計算します。
y_backward1、y_backward2を用いて微分特徴量を計算します。
以上をまとめて新たなdataとします。次のループで予測器に入力します。これを繰り返します。
from scipy import ndimage
pred_dynamic = []
for i in range(len(X_test)):
y_d = gbm.predict(data, num_iteration=gbm.best_iteration)
pred_dynamic.append(y_d[0])
val = ndimage.interpolation.shift(val, 1, cval=y_d)
mean_val = np.mean(val)
median_val = np.median(val)
max_val = np.max(val)
min_val = np.min(val)
deriv1 = (y_d - y_backward1)[0]
deriv2 = (y_d - 2*y_backward1 + y_backward2)[0]
feature = np.array([deriv1, deriv2, mean_val, median_val, max_val, min_val])
data = np.hstack([val, feature])
data = pd.Series(data, index=data_index)
y_backward2 = y_backward1
y_backward1 = y_d
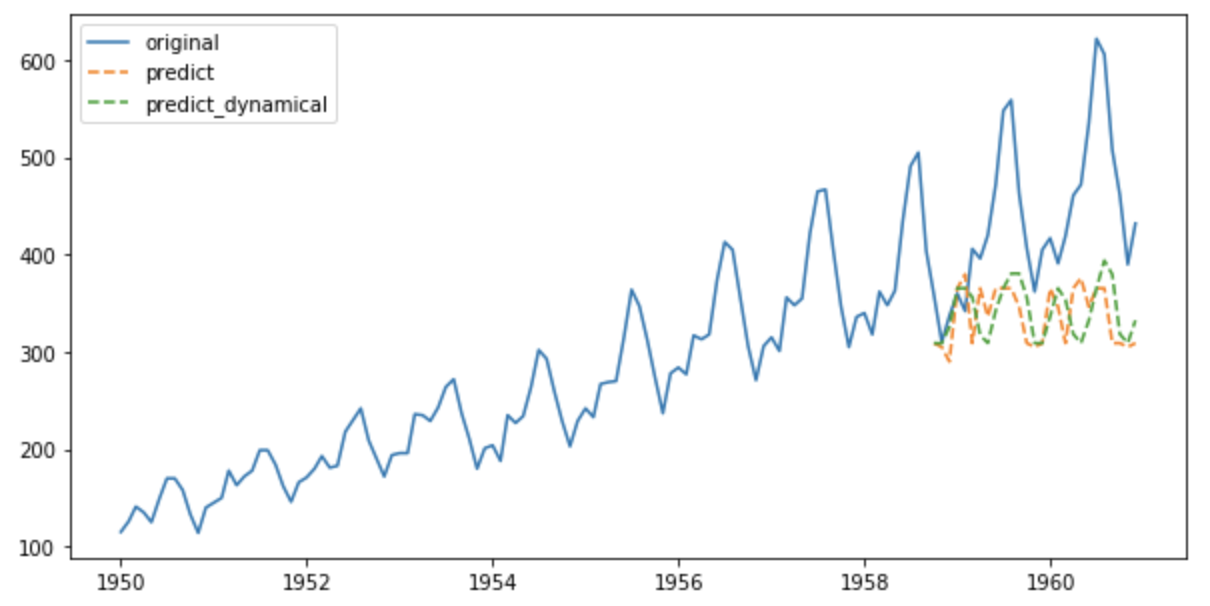
予測値をプロットします。
y__ = np.concatenate([np.array([None for i in range(len(y_train)+len(y_validation))]) , np.array(pred_dynamic)])
y__ = pd.DataFrame(y__, index=X.index)
plt.figure(figsize=(10,5))
plt.plot(y, label='original')
plt.plot(y_, '--', label='predict')
plt.plot(y__, '--', label='predict_dynamical')
plt.legend()
おわりに
tree系の予測器は学習データの範囲内でしか予測できないので、トレンドがあるデータの予測には適さないと考えられます。LightGBMなどのテーブル系に使う予測器ではトレンドの成分を除去して、かつ大量データでパターンを学習させれば時系列データも予測できるかもしれません。