その名は「decord」です
decordはハードウェアアクセラレーションによるビデオデコーダーの上に、薄いラッパーに基づいた便利なビデオスライスの方法を提供します。
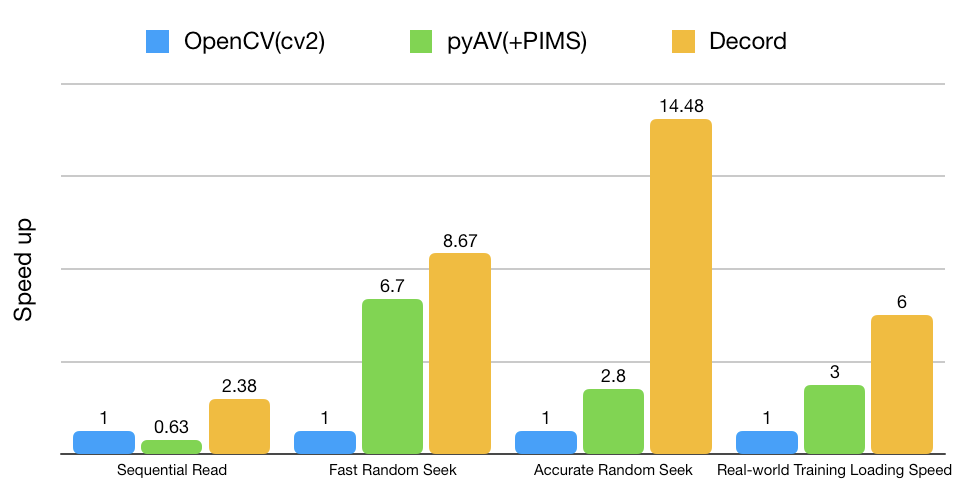
2023/2/9時点ではバージョン0.6.0で、pythonのバージョン等に制限があります。
などなど、開発中の不具合も多いみたいです。ですが読み込みは非常に高速で今後に期待できます。
pip install decord
GPUを利用する場合はソースからビルドする必要があります(省略)。
動画の読み込みはVideoReaderで行います。OpenCVと異なり、動画のメタデータから自動的に回転された向きで読み込みます。
from decord import VideoReader
from decord import cpu, gpu
vr = VideoReader('sample.mp4', ctx=cpu(0)) # cpu,gpuデバイスを選択できる
# vr = VideoReader('sample.mp4', ctx=cpu(0), width=640, height=480) # リサイズ解像度指定あり
# 全フレーム数
print('total frames:', len(vr)) # total frames: 3789
読み込むとlistライクにフレームを操作できます。返り値はクラスdecord.ndarray.NDArrayです。
# インデックスの指定でフレームを取り出す
vr_ = vr[0]
print(type(vr_)) # <class 'decord.ndarray.NDArray'>
print(vr_.shape) # (720, 1280, 3)
# スライスも可能
vr_ = vr[100:200]
print(type(vr_)) # <class 'decord.ndarray.NDArray'>
print(vr_.shape) # (100, 720, 1280, 3)
print(len(vr_)) # 276480000 ※0次元目の大きさでなく、要素数になることに注意
# インデックスの指定でフレームをバッチで取り出す
frames = vr.get_batch([1, 3, 5, 7, 9])
print(type(frames)) # <class 'decord.ndarray.NDArray'>
print(frames.shape) # (5, 720, 1280, 3)
# シーケンシャルに読み込む
print(len(vr))
count = 0
vr.seek(0) # このseekは厳密な位置を取得しない。厳密な場合は`seek_accurate`を用いる。
while True:
try:
next_frame = vr.next()
count += 1
vr.skip_frames(100) # 何フレームスキップするか
except StopIteration:
break
print(type(next_frame)) # <class 'decord.ndarray.NDArray'>
print(next_frame.shape) # (720, 1280, 3)
print(count) # 38
asnumpyメソッドでnumpy.ndarrayクラスに変換されます。
x = vr[0].asnumpy()
print(type(x)) # <class 'numpy.ndarray'>
print(x.shape) # (720, 1280, 3)
メタデータも取得できます。
# FPS
print(vr.get_avg_fps()) # 29.97002997002997
# 各フレームのタイムスタンプ
print(vr.get_frame_timestamp([0, 1, 3]))
# (N ,2)の返り値で、各フレームの(start_second, end_second) が格納されている
# [[0. 0.03336667]
# [0.03336667 0.06673333]
# [0.1001 0.13346666]]
Deep Learning 向けに型を変換するグローバル設定も可能です。Deep Learningフレームワークは予めインストールしておきます。PyTorchであれば、pip install torchです。
import decord
decord.bridge.set_bridge('torch')
# decord.bridge.set_bridge('mxnet')
# decord.bridge.set_bridge('tensorflow') # tensorflow(>=2.2.0)
# decord.bridge.set_bridge('native') # back to decord native format
print(vr[0].size()) # torch.Size([720, 1280, 3])
print(type(vr[0])) # <class 'torch.Tensor'>
次にVideoLoaderを使用します。
from decord import VideoLoader
from decord import cpu, gpu
# CPUを使用
ctx = cpu(0)
# 2フレームをバッチとして取り出す
shape = (2, 360, 640, 3)
# 動画をリストで指定できる
videos = ['sample1.mp4', 'sample2.mp4']
# バッチ内のフレームインデックスの間隔
interval = 19
# バッチ間のフレームインデックスの間隔
skip = 49
# shuffle = -1 # スマートシャッフルモード(未実装).
shuffle = 0 # ファイルもフレームもシーケンシャルに読み込む.
# shuffle = 1 # ファイルは毎回ランダムに読み込むが、ファイル別にはシーケンシャルに読み込む. 効果的.
# shuffle = 2 # ファイルもフレームも毎回ランダムな順番で読み込む.
# shuffle = 3 # ファイルもフレームも毎回ランダムな位置で読み込む.
vl = VideoLoader(
uris=videos,
ctx=ctx,
shape=shape,
interval=interval,
skip=skip,
shuffle=shuffle)
print('num batches:', len(vl)) # num batches: 108
読み込んでみます。
count = 0
vl.reset()
for batch in vl:
data = batch[0].asnumpy()
meta = batch[1].asnumpy()
print("=" * 10)
print("count:", count)
print("data shape:", data.shape)
print("meta shape:", meta.shape)
print("meta value:", meta)
count += 1
if count >= 4:
break
printされた値は次のようになります。
==========
count: 0
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 0]
[ 0 20]]
==========
count: 1
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 70]
[ 0 90]]
==========
count: 2
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 140]
[ 0 160]]
==========
count: 3
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 210]
[ 0 230]]
meta valueは(batch_size, 2)のshapeになっています。0列目はファイルを、1列目はフレームのインデックスを表しています。
バッチ内ではフレームが20ずつ、バッチをまたぐとフレームが50ずつ進んでいる事がわかります。これがそれぞれintervalとskipの意味です。
shuffle=1を見てみます。毎回読み込むファイルはランダムで、フレームは順番に読み込んでいます。
==========
count: 0
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 0]
[ 1 20]]
==========
count: 1
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 0]
[ 0 20]]
==========
count: 2
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 70]
[ 1 90]]
==========
count: 3
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 140]
[ 1 160]]
shuffle=2を見てみます。ファイルもフレームも毎回ランダムな順番で読み込んでいます。
==========
count: 0
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 0]
[ 1 20]]
==========
count: 1
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 2450]
[ 0 2470]]
==========
count: 2
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 3430]
[ 1 3450]]
==========
count: 3
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 3220]
[ 1 3240]]
shuffle=3を見てみます。ファイルもフレームも毎回ランダムな位置で読み込んでいます。
==========
count: 0
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 1890]
[ 0 1910]]
==========
count: 1
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 1820]
[ 0 1840]]
==========
count: 2
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 0 3570]
[ 0 3590]]
==========
count: 3
data shape: (2, 360, 640, 3)
meta shape: (2, 2)
meta value: [[ 1 1470]
[ 1 1490]]
なお、見てわかるように、上のbatchは動画のDeep Learningでいうバッチではありません(フレームをまとめて学習するモデルのバッチshapeは(B, N, C, H, W)です)。
VideoReaderと同様にDeep Learning 向けに型を変換するグローバル設定も可能です。
decord.bridge.set_bridge('torch')
vl.reset()
for batch in vl:
data = batch[0]
meta = batch[1]
print("=" * 10)
print("data type", type(data))
print("data shape:", data.size())
print("meta type", type(meta))
print("meta shape:", meta.size())
print("meta value:", meta)
break
# data type < class 'torch.Tensor' >
# data shape: torch.Size([2, 360, 640, 3])
# meta type < class 'torch.Tensor' >
# meta shape: torch.Size([2, 2])
# meta value: tensor([[0, 3640],
# [0, 3660]])
他にも音声読み込みのAudioReaderとAVReaderがあります。
ar = AudioReader('examples_example.mp3', ctx=cpu(0), sample_rate=44100, mono=False)
print(type(ar)) # <class 'decord.audio_reader.AudioReader'>
print(type(ar[0])) # <class 'decord.ndarray.NDArray'>
print(ar[0:5].shape) # (2, 5)
print(type(ar[0].asnumpy())) # <class 'numpy.ndarray'>
av = AVReader('examples_count.mov', ctx=cpu(0), sample_rate=44100, mono=False)
audio, video = av[0:20]
print(type(av)) # <class 'decord.av_reader.AVReader'>
print(type(audio), type(video)) # <class 'list'> <class 'decord.ndarray.NDArray'>
print('Frame #: ', len(audio)) # 20
print('Shape of the audio samples of the first frame: ', audio[0].shape) # (1, 2720)
print('Shape of the first frame: ', video.asnumpy().shape) # (20, 720, 1080, 3)
以上