Info
- タイトル:Learning Deep Object Detectors from 3D Models
- カンファ:ICCV2015
- 著者:Xingchao Peng, Baochen Sun, Karim Ali, Kate Saenko
- 論文:https://arxiv.org/abs/1412.7122
概要
- 3D CADモデルを使用してCNNを学習できるか調査した。
- CADモデルは本物と比べて、現実的な物体の質感、姿勢、背景などの特徴が欠落している場合がある。特徴の欠落がCNNの精度にどう影響するか調査した。
- PASCAL VOC2007に対して人工データを加えることで、Few-shot学習の場合に従来手法を上回った。
背景
- 大規模データのアノテーションは時間がかかる。
- 3D CADモデルがオンラインで公開され、簡単にアクセスできるようになってきた。
- そこで、2次元の人工学習画像を3D CADを使用して自動的に生成することにした。
- HOG勾配モデルは色とテクスチャに依存せず輪郭に強く依存するため、人工データでも(全体が写っていれば)ある程度学習できることが知られている。一方CNNはテクスチャに依存するため、CNNでも人工データで学習できるかは明らかでない。
- 3D CADは物体の質感、背景、リアルな姿勢、照明などの「低レベル特徴」が欠けており、CNNが低レベル特徴が欠落していても精度を保てるかは明らかでない。
- 低レベル特徴の欠落の影響を詳細に調べた。その結果、低レベルの特徴の欠落に対するCNNの不変性に関する知見を得た。
- 知見を応用してFew-shot 学習の手法を提案した。
手法
データセット
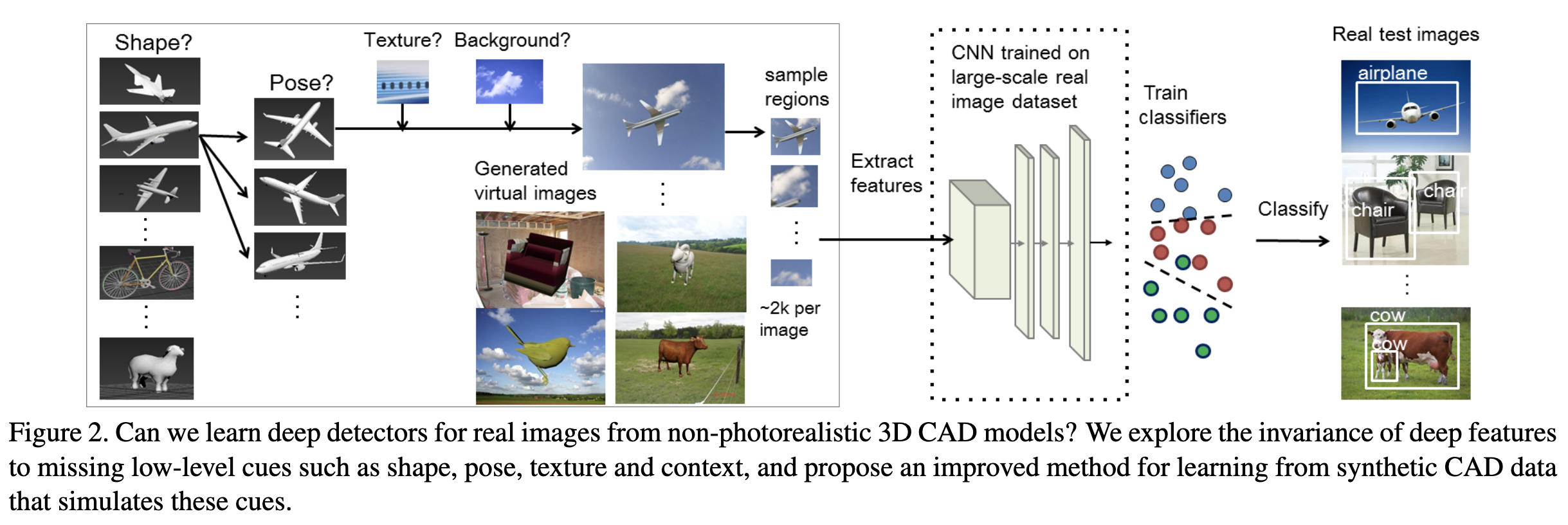
上図のように2次元の人工画像データを作成する。タスクは物体検出で、RCNNを用いる。
実験で人工的に調整できるパラメータとして以下の項目を用意した。
- object texture
- color
- 3D pose
- 3D shape
- background scene texture and color.
各項目の設定手順は以下の通り。
- 各カテゴリに対して5〜25個程度のモデルを取得した。また、実験では同一クラス内のモデル数を制限することで、クラス内の形状変化の影響を調査した。
- 3D姿勢については、姿勢の多様性が最大となるようにメインの視点を3-4個選び、それぞれに対して微小な回転を加えた。
- 最後に、各ポーズ摂動に対して、テクスチャ、色、背景画像を選択し、人工画像をレンダリングして、仮想学習データセットを作成する。
- オブジェクトと背景画像の両方について、色とテクスチャの影響を調べた。具体的には、リアルなカラーテクスチャと一様なグレースケールのテクスチャ(すなわち、テクスチャが全くない)の2種類の物体テクスチャにおけるCNNへの影響を調べた。
- 背景については、実写のカラーシーン、実写のグレースケールシーン、白背景の3種類のシーンに対する分散を検討した。
- 現実の物体の質感を再現するために、実物を含む少数の実画像(各カテゴリ5〜8枚)を用い、そこに含まれる質感をバウンディングボックスにアノテーションを付けて抽出する。このテクスチャ画像をCADモデルに合わせて伸縮させる。同様に、リアルな背景を再現するために、各カテゴリーが適用されそうなシーン(飛行機なら青空、ボートなら湖や海など)の実画像をカテゴリーごとに40枚程度集めた。次に、テクスチャプールからランダムにテクスチャ画像を選択し、CADモデル上にマッピングしてからオブジェクトをレンダリングする
ネットワーク
- CNNの部分には8層のAlexNetを採用した。
- 入力は224×224のRGB画像。
評価
"cue invariance"(手がかり不変性)を評価する。低レベル特徴が[ある/ない]データをそれぞれ用意してネットワークを学習させ、精度を比較する。低レベル特徴が無い状況でも性能が低下しない場合、その特徴に対してネットワークは手がかり不変性を持つという。
事前学習済みモデルを使用してファイン・チューニングを行うが、事前学習への依存を確認するため、3つの学習済みモデルを比較した。
- ImageNetで事前学習
- ImageNetで事前学習したものをさらにPASC-FT(20クラス物体検出)でファイン・チューニング
- ImageNetで事前学習し、少数ラベルのカテゴリはCADデータでファイン・チューニング(後のVCNNのこと)

学習済みモデル設定1と2の比較について下記の結果が得られた。
- ImageNetでは、傾向は似ているが最も性能が良いのはRR-RRとRG-RRの方法である。これは、現実的な文脈とテクスチャの統計量を追加することで分類器を助け、その結果、少なくとも我々のデータセットのカテゴリについては、IMGNETネットワークはこれらの要因にあまり左右されないことを意味する。
- やや予想外の結果は、PASC-FTのRR-RR、W-RR、W-UG、RGRRは同等の性能を達成していることである。テクスチャはあるが背景に色がない場合(RGRR、W-RR)の結果が最も優れています。このように、PASC-FTネットワークは、物体やその背景の色や質感に対して不変であることを学習していることがわかる。
- また、PASC-FTのRR-UGとRG-UGは性能がかなり低い(6~9ポイント低い)ことに注意。これは、均一な物体の質感と白でない背景がうまく区別できない可能性がある。I
- 興味深いことに、RG-RRはどちらのネットワークでも非常に良い結果を出しており、どちらのネットワークも正しい文脈の色をオブジェクトに関連付けることを学習したという結論に達する。

また、カテゴリによって精度向上に最適な設定は異なる。下図は実画像、RR-RR、W-RR、W-UGのトップ精度画像で、テレビモニターではW-UGでも発火しているが、羊はW-UGだと性能が低下する。

- 正面図に加え側面図を追加することで効果が上がるが、第3の視点を追加することによる改善はわずかであることがわかった。
- また、PASCALのテストセットにはこれらのビューにオブジェクトがない場合があるため、いくつかのビューを追加すると性能が低下する可能性があることに注意する必要がある(例:テレビ)。
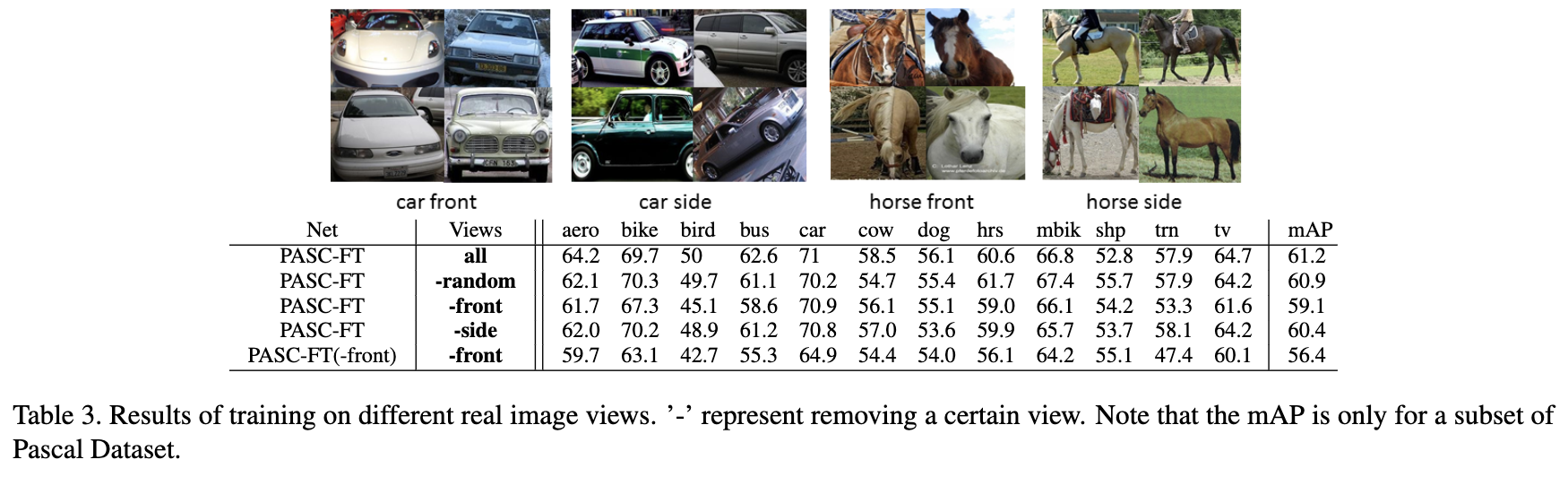
また、実画像を用いた視野不変性のテストも実施。
- どれかのビューを削除して学習させた検出器をテストした場合、mAPは2%未満しか低下しない。
- PASCALのデータには様々な視点のデータが含まれていることには注意。
結論をまとめると、DCNNは同じタスクで学習(または微調整)した場合、テクスチャ、色、姿勢に対する不変性がかなり高く、3次元形状に対する不変性は低いことがわかった。また、同じタスクで学習しない場合は、不変性の程度が低くなる。したがって、ラベル付けされた実データがない、あるいは限定的な実データを利用して新しいカテゴリの検出モデルを学習する場合、これらの要因を合成データでシミュレートすることが有利である。
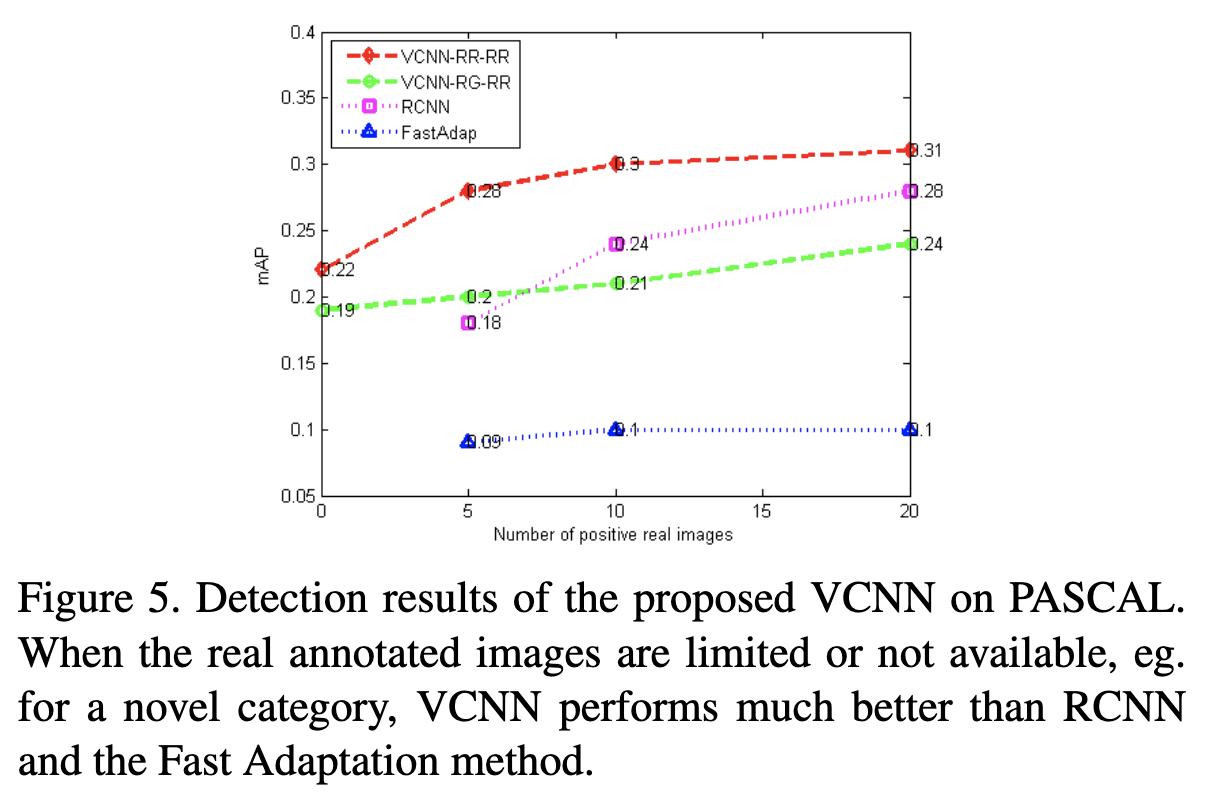
RR-RR、RG-RRの設定でFew-Shot学習を検証。各カテゴリに対して、20枚(10枚、5枚)の正の学習画像をランダムに選択し、データセットR20(R10,R5)を構築する。最終的なデータセットのサイズは276(120,73)。仮想データセット(V2kと記す)のサイズは常に2000画像である。Imagenetで事前学習を行い、V2kでファイン・チューニングを行い、VCNNネットワークを得た後、Rx+V2kの両方でSVM分類器を学習させる。
結果、実画像が少ない状況では、VCNNネットワークのほうが性能が良い。

最後にドメインシフトも調査した。webカメラで収集したデータとCADデータで学習し、Amazonの商品画像の物体検出に適用した。webカメラデータはAmazonの商品画像とは見え方が異なる。CADデータはAmazonの商品画像のように白背景とし、グレーテクスチャ、リアルテクスチャの2パターン(V-GRAY、V-TX)を作成した。
V-TXで性能をが7ポイント改善した。
まとめ・感想
- クラス分類では実画像に近いほうが精度が向上するが、物体検出では前景のテクスチャとシェイプが重要で、背景はあまり影響しない。タスクによって適切な人工データが異なる。
- 人工物は人工的にテクスチャを付与しいるため、テクスチャの影響が少ないのかもしれない。自然環境ではテクスチャの分布が複雑で、CADもリアルに近づけたほうが良い。
- CADのシェイプはテストデータの見た目に合わせたほうがよい。
- 実画像が少ないときはCADデータを加えると効果的。
- 視点(見た目)がtrainとtestで大きく異る場合でも、testに近いCADデータを加えることで精度向上できる。