Info
- タイトル:YOLO9000: Better, Faster, Stronger
- カンファ:CVPR2017
- 著者:Joseph Redmon, Ali Farhadi
- 論文:https://arxiv.org/abs/1612.08242
- プロジェクトページ:http://pjreddie.com/yolo9000/
概要
- 9000以上の物体カテゴリを検出できる最先端のリアルタイム物体検出システム、YOLO9000を作成。
- YOLOv2は、PASCAL VOCやCOCOなどの標準的な検出タスクにおいて、最先端の性能を発揮することができる。
- 新しいマルチスケール学習法を用いることで、同じYOLOv2モデルを様々なサイズで動作させることができ、速度と精度のトレードオフを容易に実現する。
- YOLOv2はVOC 2007で67FPS、76.8mAPを達成。また、40FPSでは、78.6mAPを達成し、Faster RCNN with ResNetやSSDといった最先端の手法を凌駕しながらも、大幅に高速に動作することができる。
- 最後に、物体検出と分類を共同で学習する方法を提案する。この方法を用いて、COCO検出データセットとImageNet分類データセットでYOLO9000を同時に学習させる。この共同学習により、ラベル付き検出データを持たない物体クラスに対しても、YOLO9000は検出を予測することができる。
背景
- ほとんどの検出方法は、まだ小さなデータセットに制限されています。
- 現在の物体検出のデータセットは、分類やタグ付けといった他のタスクのデータセットと比較して限定的である。一般的な物体検出データセットは、数千から数十万の画像と数十から数百のタグを含んでいる。一方で、分類データセットには、数百万の画像と数万から数十万のカテゴリが含まれる。
- このように、物体検出は物体分類のレベルにまでスケールアップすることが望まれる。しかし、検出のための画像のラベル付けは、分類やタグ付けのためのラベル付けよりもはるかにコストがかかる。
- そこで、現在の検出システムの範囲を拡大するために既にある大量の分類データを活用する新しい方法を提案する。本手法では、物体分類の階層的な見方を用いることで、異なるデータセットを一緒に結合することが可能となる。
- また、物体検出データと分類データの両方から物体検出器を学習することができる共同学習アルゴリズムも提案する。本手法は、ラベル付けされた検出画像を利用して物体の正確な位置特定を学習する一方、分類画像を利用して語彙と頑健性を向上させる。
- この方法を用いて、9000以上の異なる物体のカテゴリを検出できるリアルタイム物体検出器YOLO9000を学習させる。まず、ベースとなるYOLO検出システムを改良し、最新のリアルタイム検出器であるYOLOv2を作成する。次に、データセットの組み合わせ方法と共同学習アルゴリズムを用いて、ImageNetの9000以上のクラスとCOCOの検出データでモデルを学習する。
手法
YOLOの性能を向上させるために、過去の研究から得た様々なアイデアと独自の新しいコンセプトを融合させた。
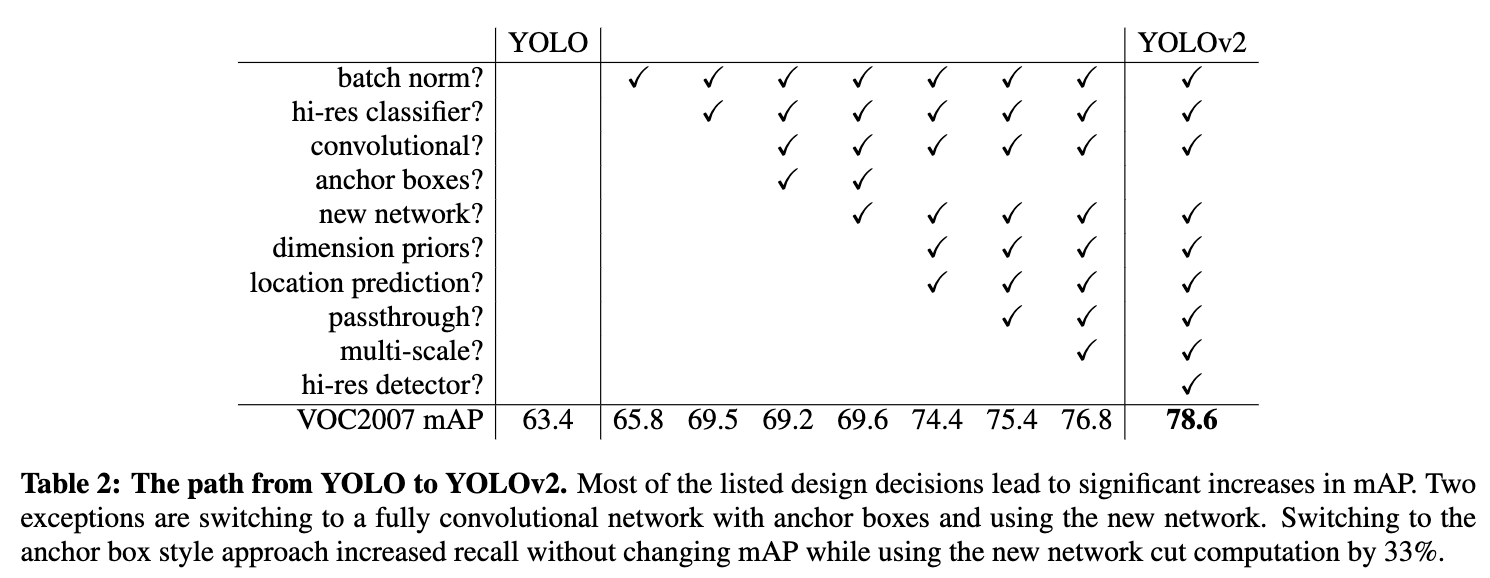
YOLOからの改善点は以下の通り。
バッチ正規化
YOLOのすべての畳み込み層にバッチ正規化を加えることで、mAPが2%以上改善された。ドロップアウトは除去した。
高解像度のbackboneを導入
ImageNetで事前に学習された分類器をbackboneに使用したいが、ほとんどの分類器は 256 × 256 よりも小さい入力画像に対して動作する。
そこでYOLOv2では、まずbackboneを448×448の解像度でImageNet上で10エポックファインチューニングした。そして、得られたネットワークを物体検出に使用してファインチューニングする。これにより、4%近いmAPの増加を得ることができる。
アンカーボックスの導入
YOLOからFC層を取り除き、アンカーボックスを使ってバウンディングボックスを予測する。まず、プーリング層を1つ削除し、ネットワークの畳み込み層の出力をより高解像度にする。
ネットワークを縮小し、448×448の入力画像ではなく、416の入力画像で動作するようにした。これは、グリッドセルの高さと幅が奇数にするためである。なぜ奇数が良いかというと、物体のほとんどは画像の中心に写っていることが多く、したがってグリッドが画像中心に存在するようにしたほうが予測性能が上がると考えられるためである。YOLOの畳み込み層は、画像を32倍にダウンサンプリングするので、解像度416の入力画像を使って、13×13の出力特徴マップが得られる 。
クラス予測と位置予測を切り離し、代わりにアンカーボックスごとにクラスとオブジェクトネスを予測する。YOLOに従って、objectness予測は依然としてグランドトゥルースと提案ボックスのIOUを予測し、クラス予測はYOLO同様条件付き確率を予測する。
寸法クラスタ

より良いアンカーボックスの寸法を選びたい。手動で選択する代わりに、学習セットのバウンディングボックスに対してk-meansクラスタリングを実行し、自動的に良い寸法を見つける。ボックスのサイズに依存しない、良いIOUスコアにつながるアンカーボックスを得るため、距離$d(\mathrm{box, centroid})=1-\mathrm{IoU}(\mathrm{box, centroid})$を用いる。
直接位置予測

YOLOのアプローチに従い、アンカーボックスとの相対位置を予測する。これによってグランドトゥルースの値を0-1に収めることができ、学習を安定化できる。
ネットワークは、出力特徴マップの各アンカーボックスに5つのバウンディングボックスを予測する。このとき、アンカーボックスが画像の左上隅から $(c_x ,c_y)$だけオフセットしており、バウンディングボックスが幅と高さ$(p_w ,p_h)$を持つ場合、予測は以下のようになる。
\begin{aligned}
b_x &= c_x + \sigma(t_x) \\
b_y &= c_y + \sigma(t_y) \\
b_w &= p_w e^{t_w} \\
b_h &= p_h e^{t_h} \\
\mathrm{Pr}(\mathrm{Object})\cdot \mathrm{IoU} &= \sigma(t_0)
\end{aligned}
寸法クラスタとバウンディングボックスの中心位置の直接予測により、アンカーボックスを用いたバージョンは約5%改善される。
Fine-Grained Features
YOLOv2は、13×13の特徴マップ上で検出を予測する。これは大きな物体には十分であるが、小さな物体を局在化させるためにはより細かい粒度の特徴が有効であると考えられる。
Faster R-CNNとSSDは、提案ネットワークをネットワーク内の様々な特徴マップで実行し、様々な解像度を得ることができる。我々は異なるアプローチをとり、単純に26×26の解像度で以前の層から特徴を持ってくるパススルー層を追加する。
パススルー層は、ResNetのアイデンティティマッピングと同様に、隣接する特徴を空間位置ではなく異なるチャンネルに積み重ねることで、高解像度特徴を低解像度特徴と連結する。これにより、26 × 26 × 512 の特徴マップは、13 × 13 × 2048 の特徴マップとなり、元の特徴と連結することができる。我々の検出器は、この拡張された特徴マップの上で動作し、より細かい特徴にアクセスできるようになる。これにより、1%程度の性能向上が期待できる。
Multi-Scale Training
オリジナルのYOLOは、448×448の入力解像度を使用している。アンカーボックスの追加により、解像度は416×416に変更されました。しかし、我々のモデルは畳み込み層とプーリング層しか使っていないので、オンザフライでサイズを変更することができる。
そこで、YOLOv2は異なるサイズの画像に対してロバストに動作するよう、モデルに学習させる。10バッチごとに、ネットワークは新しい画像サイズをランダムに選択する。このモデルは32倍でダウンサンプリングするため、32の倍数{320, 352, ..., 608}の中から選択する。
Faster
- 速度を向上させるため、backboneをDarknet-19に変更。
Stronger
※省略
評価
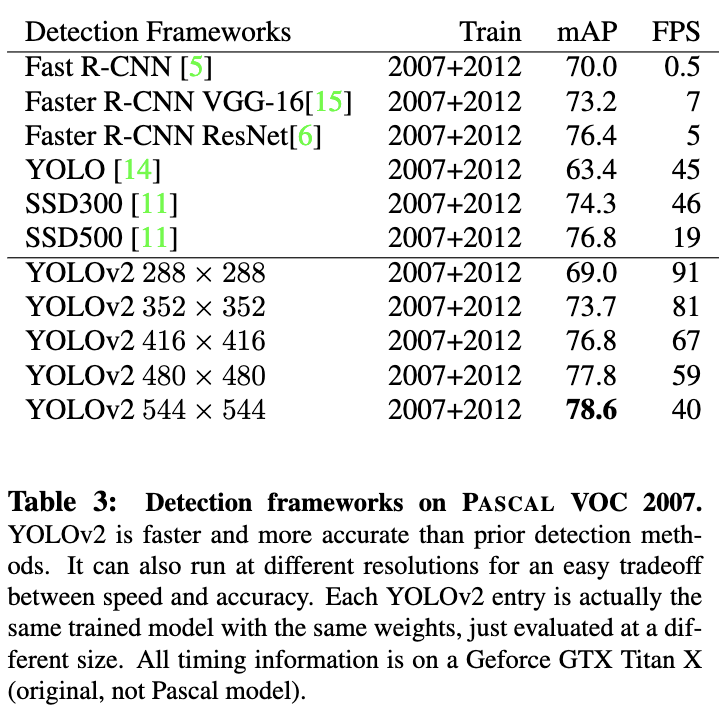
- SSDやFaster R-CNNに匹敵する精度を記録。
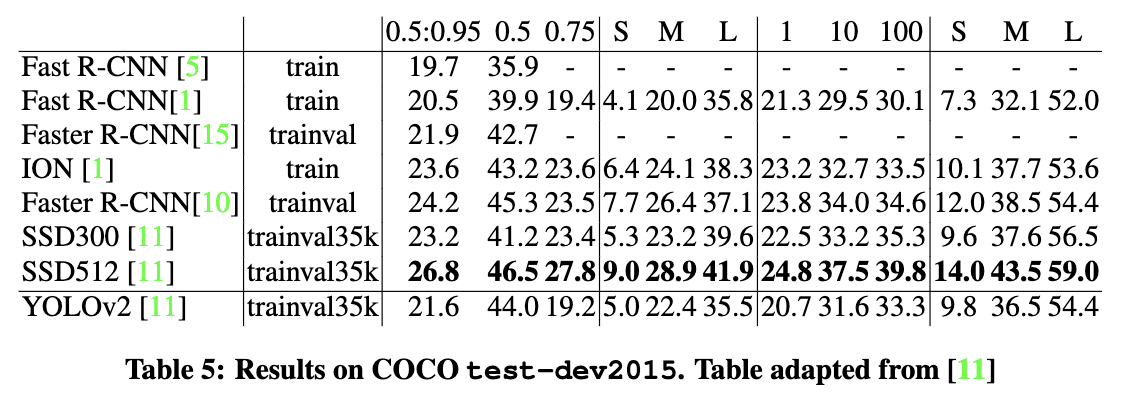
- COCOでもSSDやFaster R-CNNに匹敵する精度を記録。
まとめ・感想
- YOLOにアンカーボックスが導入されたバージョンなので読んでおくと良い。