はじめに
テーブルデータの項目には、しばしば任意に入力する項目といったオプション項目があります。このようなオプション項目を変換する手法について書きたいと思います。
環境
- macOS Majave 10.14.6
- pandas 0.23.4
手順
データの準備
下記のデータを準備します。
import pandas as pd
import numpy as np
data = [['南', '北', '東'],
['南', '東', None],
['東', '北', '西'],
['南', None, None],
['北', '西', '東'],
['西', '東', '南']]
df = pd.DataFrame(data, columns=['項目1', '項目2', '項目3'])
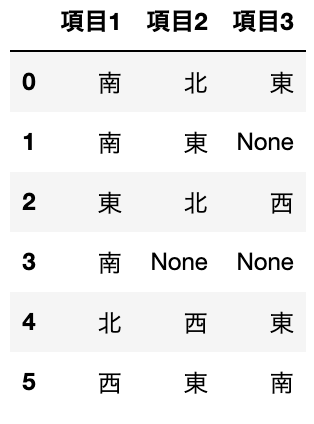
例えば、自分の部屋のどの方角に窓があるといいですか?といったアンケートの回答だとしましょう。最大3つまで回答してください、とお願いした場合に表のようなデータになります。
決まった順序を設けていないので東西南北入り乱れたデータになりました。また、最大3つ、なのでNoneの部分もあります。
このテーブルをRandom ForestやLightGBMにかけようとすると、列自体に意味がないので、予測器がうまく解釈できません。
データの変換
各行に東西南北があるか無いかの0-1データに変換します。選択項目の値を列にし、各行にその値があれば1、なければ0とします。
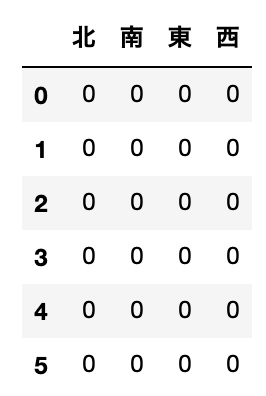
まず、Noneを選択項目の値の何かで埋め、重複を削除したものを列値とします。
この列値をもつ、元のデータと同じインデックスを持つデータフレームを作成します。
cols = np.unique(df.fillna('北').values) # cols = np.array(['南', '東', '北', '西'])
df_new = pd.DataFrame(data=0, index=df.index, columns=cols, dtype=np.int8)
元のデータのうち、新しい列値と一致する部分をTrue、しない部分をFalseに変換します。行方向に和をとれば、各行にその値があれば1、なければ0となります。これをすべての新しい列に対して実行すれば次のような表になります。
for col in cols:
dg = df == col
df_new[col] = dg.sum(axis=1)
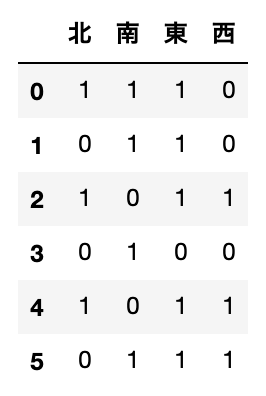
これで予測器がデータを解釈できるようになりました。
おわりに
最初からこうなるようにDB設計してくれれば(ry