Info
- タイトル:Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection
- 著者:Debidatta Dwibedi, Ishan Misra, Martial Hebert
- カンファ:ICCV2017
- 論文:https://arxiv.org/abs/1708.01642?context=cs
- プロジェクトページ:https://github.com/debidatta/syndata-generation
概要
- 物体検出用のデータセットを作成する方法を提案。
- オブジェクトインスタンスを自動的に「切り取り」、ランダムな背景上に「貼り付け」る。
背景
- 物体検出モデルを構築する上での大きな課題の一つは、大規模なラベル付きデータセットがないこと。新しいインスタンスを含む新しい環境ごとに、高価なデータ収集とアノテーションが必要となる。
- 合成的にレンダリングされたシーンやオブジェクトを使用して検出システムを学習させるという研究が行われているが、この方法には課題がある。
- 現実的なシーンや現実に近いオブジェクトを作るために、大域的・局所的な観点でそれぞれ無矛盾になるようにデータを作る労力が必要になる。
- synthetic data と実データでは統計量が異なり、学習済みモデルを実データに適用した際に精度が落ちる。
- 本論文では最小限の労力で大規模な注釈付きインスタンスデータセットを生成するための簡単なアプローチを提案する。
- 検出対象の物体近傍のパッチが人間の目で見てリアルであればよいという仮説を立てた。
- そこで、オブジェクトインスタンスを自動的に「切り取り」、ランダムな背景上に「貼り付け」る。素朴にオブジェクトマスクをシーンに配置すると、画像に微妙なピクセルアーチファクトが発生し、ネットワークのより深い層にフィードフォワードされ、顕著に異なる特徴につながり、学習済みモデルの性能が低くなる。
- そこで、学習時にこれらのアーチファクトを無視し、実データで競争力のある性能を発揮するデータを生成する方法を示した。
- 結果、生成された画像は大域的に整合していない画像であるが、少ない労力で高性能な検出器が得られる。
- 特に、本手法では視点やスケールの異なる画像を多数生成することができ、最小限の労力で対象物の外観を十分にカバーすることができる。そのため、テストシーンが学習シーンと異なる場合、つまり、物体が異なる視点・スケールで出現する場合に、性能向上は特に顕著になる。
手法
概要

- Collect object instance images: 本手法は、データ収集の方法に依存しない。本手法では、多様な視点をカバーし、適度な背景を持つ物体画像を入手できると仮定する。
- Collect scene images: これらの画像は学習データセットの背景画像として利用される。スマートホームや倉庫のように、あらかじめテストシーンが分かっている場合は、そのシーンから画像を収集することができる。我々は幾何学やレイアウトのようなシーン統計量を計算しないので、このアプローチは新しいシーンに容易に対応することができる。
- Predict foreground mask for the object: インスタンスピクセルと背景ピクセルを分離する前景マスクを予測する。これにより、シーンに配置可能なオブジェクトのマスクが得られる。
- Paste object instances in scenes: 抽出されたオブジェクトをランダムに選ばれた背景画像に貼り付ける。学習アルゴリズムが境界のサブピクセルの不一致に注目しないように、オブジェクトを配置する際に、局所的なアーチファクトに対する不変性を確保する。また、様々なブレンドのモードを追加し、全く同じシーンを異なるブレンドで合成することで、これらのアーティファクトに対してロバストなアルゴリズムを実現する。また、多様な視点/スケールをカバーするために、データ補強を追加する。
データセット
- 背景画像には UW Scenesデータセットを使用。1548枚の画像が含まれる。
- 前景画像には Big Berkeley Instance Recognition Dataset (BigBIRD)データセットを使用。各オブジェクトは、異なる視点を持つ5台のカメラで撮影された600枚の画像(125 オブジェクト)を持っている。また、各画像にはIRカメラで撮影された深度画像も持っている。
前景マスクの自動切り出し
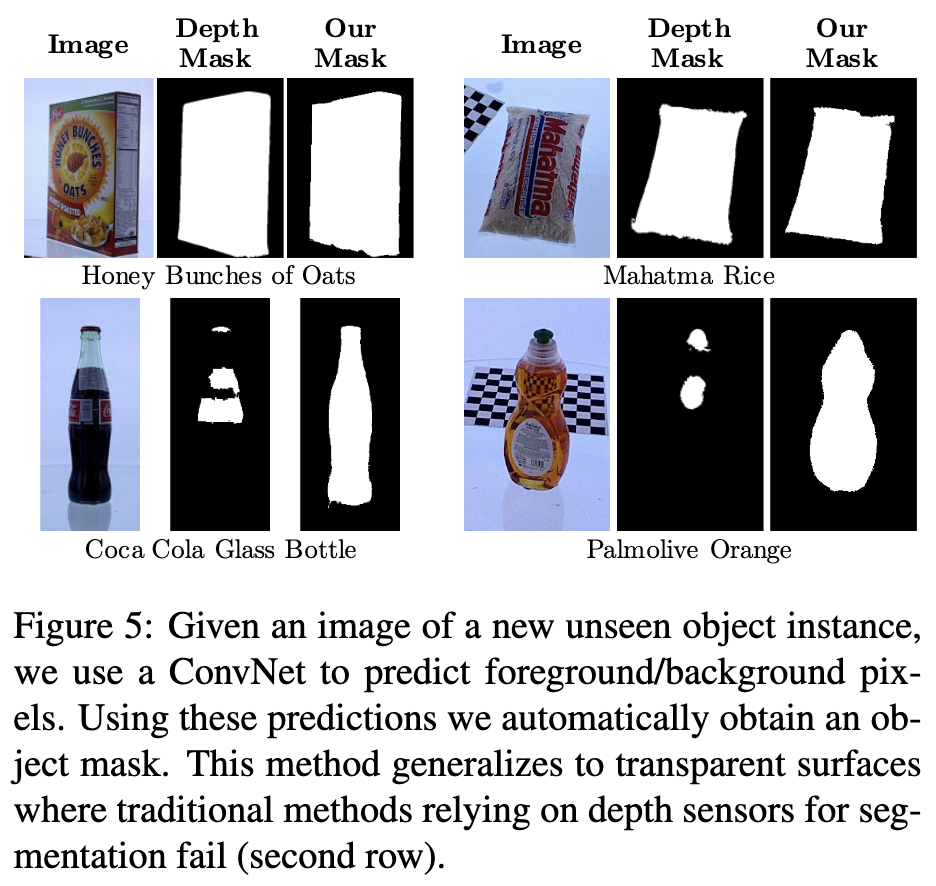
- 前景/背景のセグメンテーションをFCNで学習する。VGG-16 backboneはPascalデータセットで学習済のものを使用。
- CNNの予測結果の後処理にはバイラテラルソルバーを使用。
- 深度センサからのオブジェクトマスクがグランドトゥルースとして用いられる。
- 最終的な検出評価には存在しないインスタンスの画像を用いて学習させる。
- 透明な物体でも対応可能。
貼り付け(ブレンド)方法

- いくつかのブレンディング手法で画像を貼り付けた。
- 例えばポアソンブレンディングを施すと、エッジが平滑化され、照明も反映されている。
- これらのブレンド法は、視覚的に完全な結果を得ることはできないが、学習された検出器の性能を向上させることができる。
- 全く同じシーンで、ブレンディングを変えたものを含めたパターンを"All Blend + same image"と記す。ブレンドの種類だけを変えた複数の画像で学習を行うことで、学習アルゴリズムはブレンドの種類に左右されなくなり、ブレンドを一切使用しない場合に比べて性能が向上する。
Augmentation
-
背景にオブジェクトを貼り付けると同時に、以下のようなデータ増強を行う。
- 2次元回転: カメラとオブジェクトの回転の変化を考慮し、オブジェクトを30度から-30度の間で一様にサンプリングされたランダムな角度で回転させる。
- 3D回転: 実データには含まれにくいインスタンスの非定型な3次元回転を含む画像を生成する。
- オクルージョンとトランケーション: トランケーションをモデル化するために、画像の境界にオブジェクトを配置し、オブジェクトボックスの少なくとも25%が画像内にあるようにする。オクルージョンを追加するために、オブジェクトを互いに部分的に重なり合うように貼り付ける(最大IOUは0.75)。
-
ディストラクター・オブジェクト: シーンに邪魔なオブジェクトを追加する。これは、複数の妨害オブジェクトが存在する実世界のシナリオをモデル化したものである。BigBIRDデータセットから追加されたオブジェクトをディストラクターとして使用します。ディストラクターの存在は、学習アルゴリズムがオブジェクトを検出する際に境界のアーチファクトに
latchするだけでなく、精度も向上させる。
物体検出手法
- 検出モデルは Faster R-CNNを用い、MSCOCOデータセットで物体検出の事前学習を行ったVGG-16モデルを使用。
- 評価はGMU Kitchenデータセットで行った。23個のオブジェクトを含み、うち11種類はBigBirdデータセットと同じ、残りはキッチンにある一般的な物体である。
- train/test splitは3パターンあり、平均を報告した。評価指標はmAP@0.5を使用。
データ生成
- 学習に使用する人工画像は約6000枚生成した。背景は約1500枚なので、平均4回ほど同じ背景が使われる。
- 物体同士のオクルージョンは最大75%まで許容し、トランケーションは最小25%が画像内にあればよいとした。
物体検出の実験設定
- COCOで学習済みモデルをfine-tune。
- 25Kイテレーション。
- オプティマイザはSGD+momentumで、momentumは0.9、lrは0.001とした。weight decay は 0.0005とした。
- fc層のdrop outは0.5とした。
- シードは全実験で同一。
評価
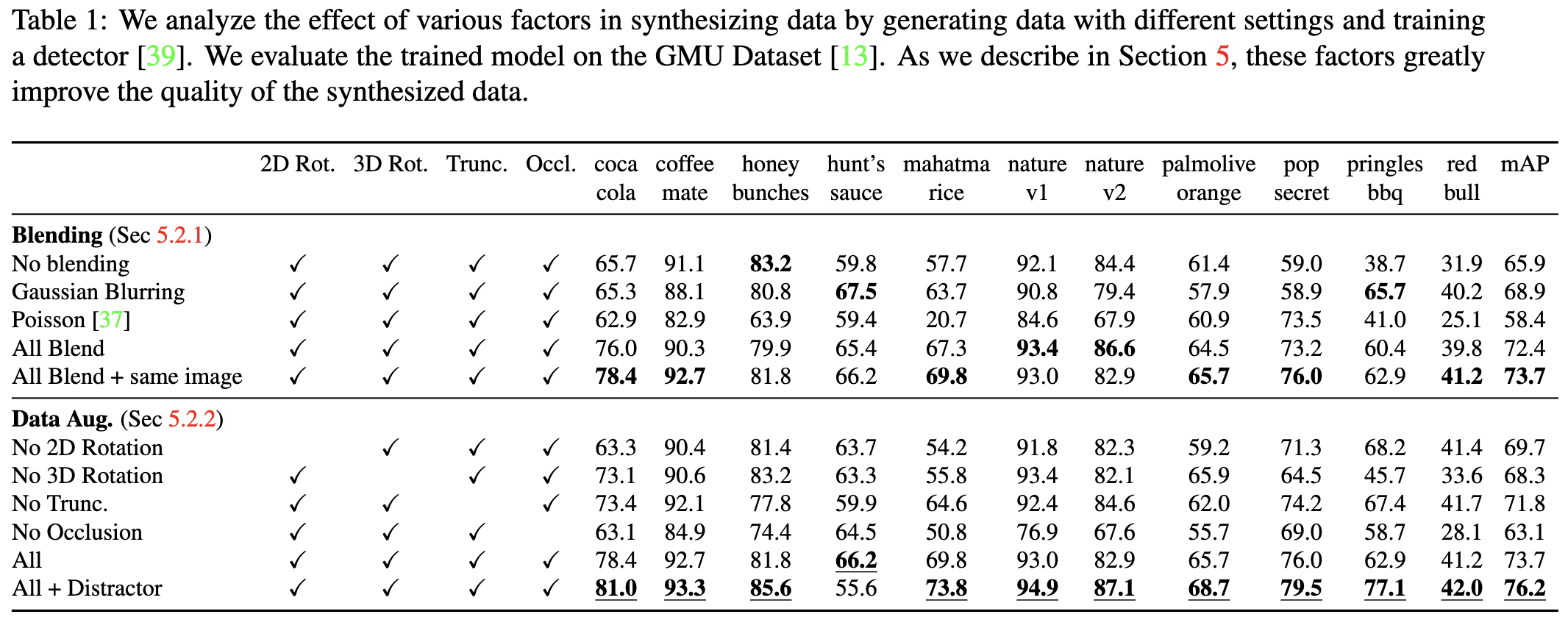
- 上段がシーンは同じで、ブレンディングを変えた場合。ブレンドを複数使ったほうが精度が良い。
- 下段がAugmentationのablation study。特にオクルージョンと回転が効いている。
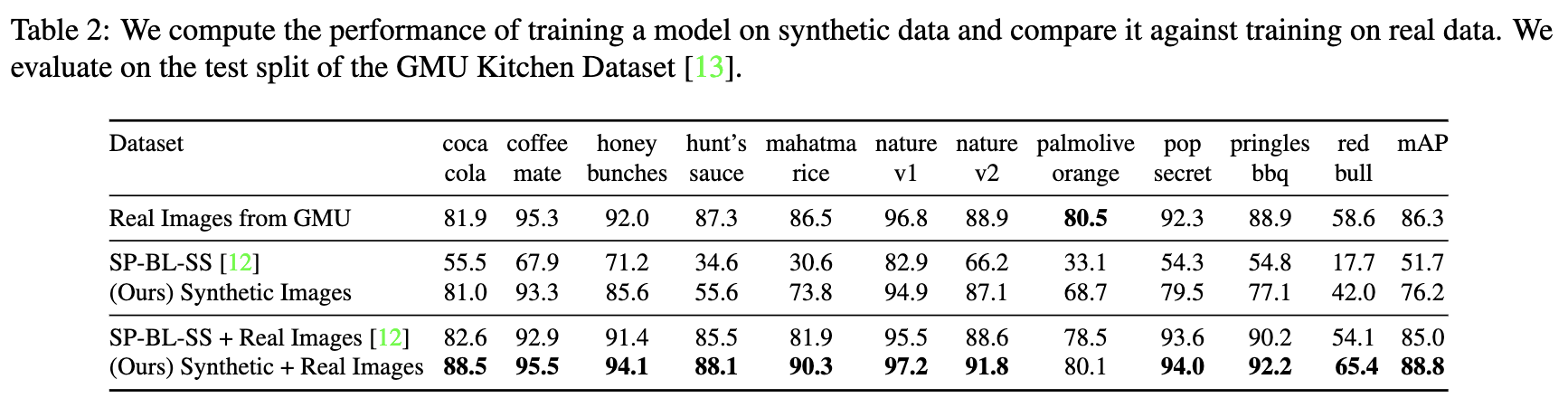
- 人口データだけでもAP76%。実データも加えると、実データのみより精度を向上できる。

- 質的な評価。人口データを用いることで、オクルードやトランケーション状態でのFalse Negativeの抑制、邪魔なオブジェクトのFals Positiveの抑制、視点変化によるFalse Negativeの抑制がされている。
まとめ・感想
- シンプルな手法ながら精度が出ている。
- 貼り付け境界がこんなにもモデルに影響があるとは意外であった。
- オクルージョンの有無もかなり精度に影響する。
- 論文中に3D回転とあるが、3Dモデルでないのにどうやって3D回転させた? 射影変換のことを指しているのか?
- バッチサイズは1?Faster-RCNNを提案した論文設定と同じか?