Info
- タイトル: Augmentation for small object detection
- 著者:Kisantal, Mate ; Wojna, Zbigniew ; Murawski, Jakub ; Naruniec, Jacek ; Cho, Kyunghyun
- 論文:https://ui.adsabs.harvard.edu/link_gateway/2019arXiv190207296K/doi:10.48550/arXiv.1902.07296
概要
この論文は、小さなオブジェクトの検出におけるデータ拡張について述べたものです。著者らは、小さなオブジェクトの検出において、既存の手法では大きなオブジェクトと比べて性能が劣ることを指摘し、データ拡張によって性能を向上させる方法を提案しています。
具体的には、小さなオブジェクトが含まれる画像を過剰にサンプリングし、それらの画像をコピー&ペーストすることで、データセットを拡張する方法が提案されています。
最終的に、MS COCOの現在のSOTAと比較して、小さな物体のインスタンスのセグメンテーションで9.7%、物体検出で7.1%の相対的な改善を達成しています(COCO APの%でないことに注意)。
背景
小さなオブジェクトの検出において、既存の手法では大きなオブジェクトと比べて性能が劣ることがあるという問題があります。

画像引用元:https://arxiv.org/pdf/1902.07296
MS COCOにおけるインスタンスの大中小の分類は以下の通りです。

画像引用元:https://arxiv.org/pdf/1902.07296
この研究では、Mask R-CNNをMS COCO上で評価しています。MS COCOには小さな物体に関する2つの特性があります。
- このデータセットには小さな物体を含む画像が比較的少ないことが観察され、これはどのような検出モデルも中型や大型の物体に重点を置くように偏る可能性があります。
- 小物体がカバーする面積ははるかに小さく、小物体の位置に多様性がないことを示唆しています。このため、画像内のあまり探索されていない部分に小物体が現れた場合、テスト時において物体検出モデルが小物体に汎化することが困難になると推測されます。
実際MS COCOの訓練セットでは、全オブジェクトの41.43%が小オブジェクトで、中オブジェクトは34.4%、大オブジェクトは24.2%です。しかし、トレーニング画像の約半分しか小オブジェクトを含んでいません。トレーニング画像の70.07%と82.28%は、それぞれ中オブジェクトと大オブジェクトを含んでいます。これは、小物体検出の問題の一つである、小物体の例が少ないことを示しています。
二つ目の問題は、各サイズカテゴリのオブジェクトの総面積を見ると明らかです。アノテーションされたピクセルのわずか1.23%しか小オブジェクトに関連していません。中オブジェクトは、アノテーションされたピクセルの10.18%を占め、これは8倍以上の面積です。大部分のピクセル、82.28%は大オブジェクトとしてラベル付けされています。このデータセットで学習された検出器は、画像全体やピクセル全体で、小さなオブジェクトを十分に考慮できません。
領域提案ネットワークから予測される各アンカーは、グラウンドトゥルースのバウンディングボックスと最も高いIoUを持つ場合や、どのグラウンドトゥルースのボックスに対しても0.7以上のIoUを持つ場合に、正のラベルを受け取ります。複数のスライディングウィンドウを持つ大きなオブジェクトは、たくさんのアンカーボックスと高いIoUを持つことが多いのですが、小さなオブジェクトは、低いIoUを持つ1つのアンカーボックスとしか一致しないことがあります。このため、この手順は大きなオブジェクトにとって非常に有利です。表2によると、正確にマッチしたアンカーのうち、小さなオブジェクトとペアになっているのは29.96%しかなく、大きなオブジェクトとペアになっているのは44.49%です。逆に言うと、1つの大オブジェクトに対して2.54個のマッチしたアンカーがあり、小オブジェクト1つに対してマッチしたアンカーは1つしかありません。さらに、平均最大IoUの指標からも、小さなオブジェクトの最もマッチするアンカーボックスは、通常IoUの値が低いことがわかります。小オブジェクトの平均最大IoUは0.29で、中オブジェクトと大オブジェクトの最もマッチするアンカーは、それぞれ0.57と0.66で、約2倍の高いIoUを持っています。この現象は図5でいくつかの例を使って視覚的に示しています。これらの観察から、小オブジェクトは領域提案ロスの計算にあまり影響を与えず、ネットワーク全体が大オブジェクトと中オブジェクトに偏っていることが示されます。

手法
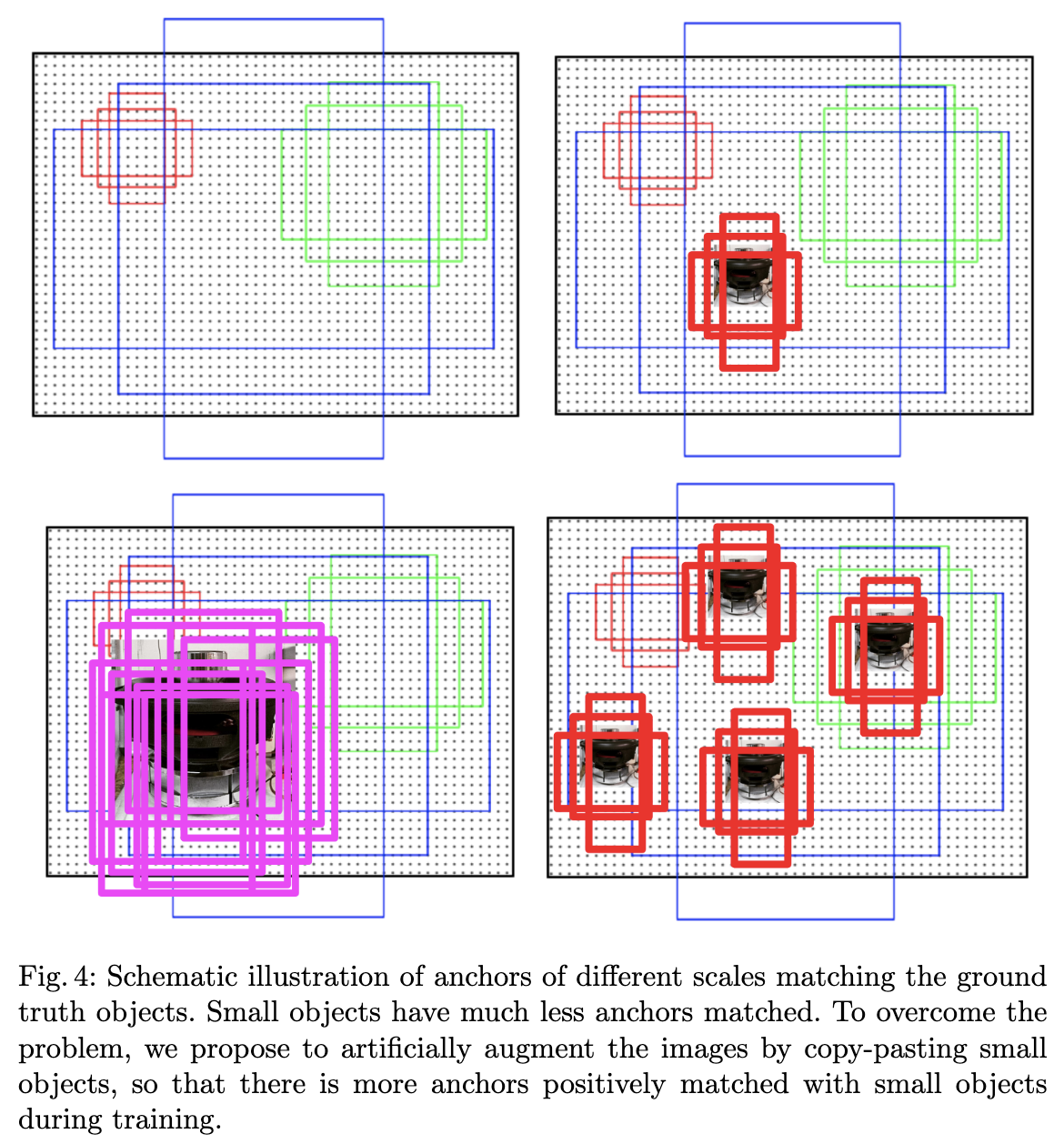
第一の問題に対処するために、小さな物体を含む画像を過剰にサンプリングします。
第二の問題には、各画像内で小さな物体を複数回コピー&ペーストすることで対処しています。各物体を貼り付ける際には、既存の物体と重ならないようにします。これにより、小さな物体の位置の多様性が増加し、同時に正しいコンテキストで物体が表示されることが保証されます。

画像引用元:https://arxiv.org/pdf/1902.07296
各画像内の小さな物体の数が増加することで、正確にマッチングされるアンカーの数の不足という問題にも対処しています。
評価
小さい物体が写っている画像をオーバーサンプリングすることで精度向上。

小さい物体をコピーペーストで画像内に増やすことで精度向上。

小さい物体全てをコピーペーストで画像内に増やすと精度が向上したが、画像内の小さい物体一つを1,2個コピーペーストして増やした場合と差がない。

貼り付ける際のオーバーラッピングやエッジのブラーに効果なし。

Related work
論文中で紹介されている小さいオブジェクトの検出の関連手法から抜粋。
入力画像の解像度を上げる
AugmentationでRandom Resized cropを使用し、小さな物体をクロップすることで、ズームと同じ効果をもたらします。
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: European conference on computer vision. pp. 21–37. Springer (2016)
高解像度の特徴と低解像度画像からの高次元特徴を融合する
2つの新しい戦略、すなわち1) スケール依存のプーリングと2) レイヤーワイズのカスケードリジェクション分類器について提案しています。スケール依存のプーリングは、候補オブジェクト提案のスケールに応じた適切な畳み込み特徴を利用することで検出精度を向上させます。カスケードリジェクション分類器は、畳み込み特徴を効果的に利用し、カスケード方式でネガティブなオブジェクト提案を排除することで、高い精度を維持しつつ検出速度を大幅に向上させます。

F. Yang, W. Choi and Y. Lin, "Exploit All the Layers: Fast and Accurate CNN Object Detector with Scale Dependent Pooling and Cascaded Rejection Classifiers," 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 2129-2137, doi: 10.1109/CVPR.2016.234.
大小の物体の区別がつかない畳み込みネットワークの特徴を構築する
小さい物体の検出は、その低解像度とノイズの多い表現のために非常に難しいとされています。既存の物体検出手法は、複数のスケールですべての物体の表現を学習することで小さい物体を検出しますが、そのようなアーキテクチャの性能向上は、計算コストに見合わないことが多いです。この研究では、単一のアーキテクチャを用いて小さい物体の表現を"超解像"に昇格させ、大きな物体と同様の特性を持つことで、検出において識別力を向上させる方法を提案しています。具体的には、小さい物体と大きい物体の表現の違いを縮小することで小さい物体の検出を向上させる新しいPerceptual Generative Adversarial Network (Perceptual GAN)モデルを提案しています。このモデルの生成器は、小さい物体の劣った表現を、識別器を欺くほど実際の大きな物体に似ている超解像のものに変換することを学習します。一方、識別器は生成器と競合し、生成された表現を特定するとともに、小さい物体の生成された表現が検出の目的に有益であるという追加の知覚要件を生成器に課す役割を持っています。

画像引用元:https://arxiv.org/pdf/1706.05274
Li, J., Liang, X., Wei, Y., Xu, T., Feng, J., Yan, S.: Perceptual generative adversarial networks for small object detection. In: IEEE CVPR (2017)
領域提案ネットワークにおいて、異なる解像度レイヤーに基づく異なるアンカースケールを使用する
現代の物体検出手法の多くは、2段階のパイプラインを採用しています。最初の段階で注目領域を特定し、次の段階で分類を行います。Faster R-CNNは、これらの両段階を一つのパイプラインに統合した物体検出の手法です。本論文では、Faster R-CNNを企業のロゴ検出のタスクに適用します。小さな物体の検出性能が低いことから、様々な物体の大きさに関して提案段階と分類段階の両方を詳細に調査します。特徴マップの解像度がこれらの段階の性能にどのように影響するかを調査します。
理論的な考察に基づいて、アンカー提案の生成スキームを改良し、小さな物体のための高解像度特徴マップを活用するFaster R-CNNへの変更を提案します。

画像引用元:https://arxiv.org/abs/1704.08881v1
Eggert, C., Zecha, D., Brehm, S., Lienhart, R.: Improving small object proposals for company logo detection. In: Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval. pp. 167–174. ACM (
画像特徴間のギャップをカバーするために、アンカーサイズの正しい割合だけ画像特徴をシフトする
物体検出のための小さな物体に敏感な方法を提案します。この方法は、画像の物体検出のためのシンプルで効果的な深層ニューラルネットワークであるSSD (Single Shot MultiBox Detector) を基盤として構築されています。しかし、SSDで使用されているアンカーメカニズムの離散的な性質は、アンカーボックスの間のギャップに位置する小さな物体の検出ミスを引き起こす可能性があります。入力画像の円形シフト後、SSDは小さな物体の検出でより良い性能を発揮します。そのため、小さな物体の検出のためにSSDの下位の追加特徴マップ上で円形シフトを行い、補助的な特徴マップを生成します。これは、物体の位置をアンカーボックスの位置に合わせるためのシフトと同等です。私たちはこの提案システムをShifted SSDと呼びます。さらに、小さな物体の検出においては、位置の高精度な特定が非常に重要です。そのため、より正確な位置を取得するための新しい2つの方法、Smooth NMSとIoU-Predictionモジュールを提案します。ビデオシーケンスの場合、新しいフレームでの予測位置を取得するために、軌道仮説を生成します。PASCAL VOC 2007、MS COCO、KITTI、および私たちの小さな物体ビデオデータセットで行われた実験は、mAPとリコールが異なる程度で向上し、速度はSSDとほぼ同じであることを確認しています。
Liangji Fang, Xu Zhao, and Shiquan Zhang. 2019. Small-objectness sensitive detection based on shifted single shot detector. Multimedia Tools Appl. 78, 10 (May 2019), 13227–13245. https://doi.org/10.1007/s11042-018-6227-7
小さなオブジェクトの提案を切り取る際にコンテキストを追加する
小さな顔を探す文脈での問題の3つの側面、すなわち、スケール不変性、画像解像度、文脈的推論の役割について探究します。多くの認識アプローチはスケール不変性を目指していますが、3pxの高さの顔を認識する手がかりは、300pxの高さの顔を認識する手がかりとは根本的に異なっています。私たちは異なるアプローチを取り、異なるスケールのために異なる検出器を訓練します。効率を維持するために、検出器はマルチタスク方式で訓練され、単一の(深い)特徴階層の複数の層から抽出された特徴を利用します。大きな物体のための検出器の訓練は簡単ですが、小さな物体のための検出器の訓練は大きな課題となっています。文脈が重要であることを示し、極端に大きな受容野を持つテンプレートを定義します(テンプレートの99%が関心の対象となる物体を超えて拡がっています)。最後に、事前訓練されたディープネットワークにおけるスケールの役割を探り、限定されたスケールにチューニングされたネットワークを非常に極端な範囲に外挿する方法を提供します。FDDBとWIDER FACEという大規模にベンチマークされた顔のデータセットで業界をリードする結果を示します。特に、WIDER FACEに関して先行研究と比較すると、私たちの結果はエラーを2分の1に減少させます(私たちのモデルはAPが82%で、先行研究は29-64%の範囲です)。

画像引用元:https://arxiv.org/abs/1612.04402
Hu, P., Ramanan, D.: Finding tiny faces. In: Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. pp. 1522–1530. IEEE (2017)
まとめ・感想
- 小さい物体の検出に対して、理論的に考察した論文で貴重な論文。
- 小さい物体とアンカーの関係を統計値を用いて説明している点が良い。小さい物体に対する大きさ・位置が近いアンカーが不足していることを明らかにしている。
- Augmentation後の統計がないのが残念。また、実用的にはMixupがのほうがAugmentationとして強力かつ手軽そう。