はじめに
近年、ディープラーニングの進化により、画像認識技術は飛躍的に向上しています。特に物体検出の分野では、Faster R-CNNのようなモデルが業界のスタンダードとして確立し、多くの応用例を生み出しています。しかし、このような高度なモデルをゼロから実装するのは非常に困難であり、多くの研究者やエンジニアは既存のライブラリを使用して開発を進めています。
torchvision は、PyTorchの公式拡張ライブラリとして、画像認識のためのデータセット、モデル、変換関数を提供しています。そして、その中にはFaster R-CNNの実装も含まれています。
本記事では、Faster R-CNNの論文をベースとしつつ、細かい処理はtorchvision に組み込まれているFaster R-CNNの実装を参考にし、モデルの内部構造や動作原理を明らかにします。
環境
- torchvision==0.14.1
torchvisionのソースコードはBSD 3-Clause "New" or "Revised" Licenseです。
Faster R-CNNの概要
Faster R-CNN(Region-based Convolutional Neural Networks)は、物体検出タスク用のディープラーニングモデルの一つです。物体検出は、画像内の物体を検出して、その物体の位置(bounding box)とクラスを同時に予測するタスクです。Faster R-CNNは、従来のR-CNNやFast R-CNNの進化版として、検出速度と精度の向上を目指して開発されました。
Faster R-CNNの主要な構成要素とステップは以下の通りです。
-
畳み込み特徴マップの生成
まず、入力画像を前処理し、畳み込み層(通常は事前に訓練されたCNN、例えばVGGやResNetなど)を通して特徴マップを生成します。 -
Region Proposal Network (RPN)
Faster R-CNNの最も重要な革新点はRPNです。RPNは、畳み込み特徴マップ上で物体が存在する可能性が高い領域(プロポーザル)を効率的に生成するためのネットワークです。これにより、外部の方法(例:Selective Search)を使用することなく、プロポーザルを高速に生成することができます。 -
RoI Pooling層
RPNで生成されたプロポーザルは、様々なサイズとアスペクト比を持っています。しかし、後続の全結合層は固定サイズの入力を必要とするため、RoI Pooling層を使用して異なるサイズのプロポーザルを固定サイズの特徴マップに変換します。 -
クラス予測とバウンディングボックスの回帰
RoI Poolingの後、全結合層とクラス分類器を経て、各プロポーザルのクラスラベルとバウンディングボックスの座標を予測します。
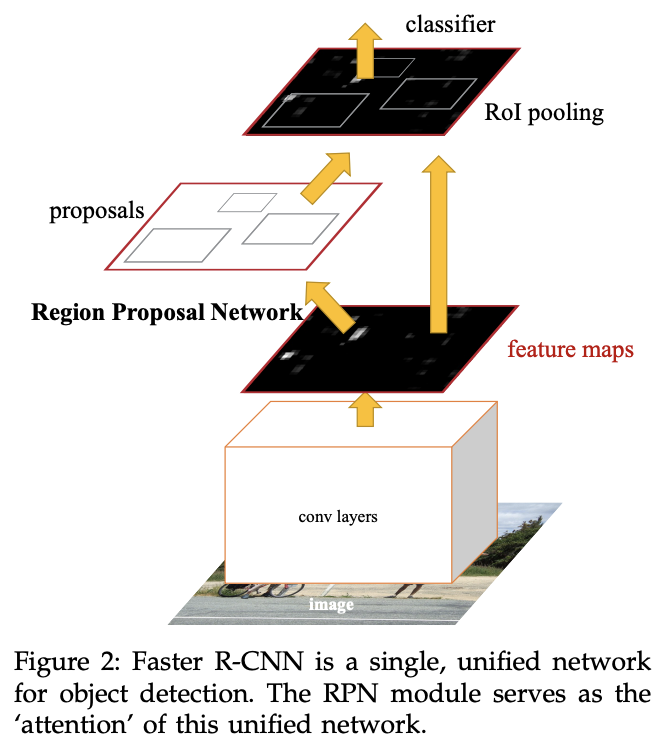
Faster R-CNNの概念的な理解
Faster R-CNNの特徴の一つに、Region Proposal Network (RPN) があります。RPNは、畳み込み特徴マップ上に物体が存在する可能性が高い領域を効率的に提案する役割を持ちます(提案された領域をプロポーザルと呼びます)。その際に使われるのが「アンカー」です。アンカーとは、Faster R-CNNが物体の存在を検出するための基準となる参照ボックスのことを指します。
下図でアンカーについて解説します。まず概念的なところからスタートするので、作図の粗さはご容赦ください。
やりたいことは、左の画像の車の位置、すなわちバウンディングボックスを右の画像のように特定することです。バウンディングボックスは左上の頂点座標と右下の頂点座標で指定されるので4成分を持つベクトルです。

いきなり左の図を入力してバウンディングボックスを出力させるのはタスクとしては難しいです。そこで、アンカーを用意してやります。まず画像をグリッドに分割します。このグリッドのどこに物体が写っているか判別するタスクなら解けそうな気がしますね。

さらに物体の位置をぴったり特定するために、グリッドそれぞれに対して複数パターンのアンカーを用意します。これらのアンカーに物体が写っているかの判別と、これらのアンカーをどれだけ変形させれば、求めたいバウンディングボックス(赤いボックス)になるかをRPNに解かせます。下図の左の画像では見やすさのために、物体が写っている箇所に対してのみアンカーを3つだけ描きました(オレンジのボックス)。下図の右の画像ではRPNが予測した変形後のアンカー、すなわちプロポーザルを描きました。

以上をまとめると、RPNは各アンカーに物体が写っている確信度(これをObjectnessと呼びます)とそのアンカーをどれだけ変形させればよいかのオフセットを学習します。
RPNはRoI Pooling層に対してプロポーザルを出力します。RoI Pooling層はプロポーザルが示す領域の特徴量を固定長に変形し、クラス予測とバウンディングボックスの回帰モジュールに渡します。クラス予測とバウンディングボックスの回帰モジュールは、物体のクラスとより正確な物体の位置(バウンディングボックス)を出力します。
Faster R-CNNの実装的理解
backboneによる特徴マップ生成
まず、画像から特徴マップを生成し、グリッドにしたいです。そのために特徴抽出器を使用します。画像を入力する特徴抽出器の部分を背骨に見立ててbackboneと呼びます。backboneには様々なネットワークを使用する事ができますが、今回はbackboneにVGG16を使用して説明します。
VGG16の最後のmax pooling以降(下図の右から5ブロック目以降)を取り除いてbackboneとして使用します。入力画像の大きさを$(3,H,W)$とすると、backboneの出力は$(512,H/16,W/16)$になります。入力画像の大きさを例えば$(3,800,800)$とするとbackboneの出力は$(512,50,50)$となり、$50\times50$のグリッドになります。
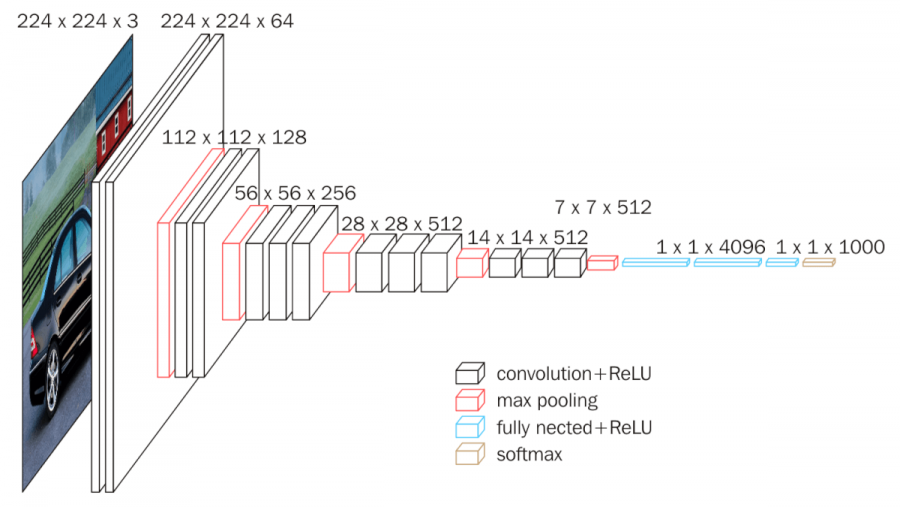
画像引用元:https://neurohive.io/en/popular-networks/vgg16/
import torch
import torchvision.models as models
backbone = models.vgg16(pretrained=True).features[:-1]
x = torch.rand((1, 3, 800, 800))
y = backbone(x)
print(y.size()) # torch.Size([1, 512, 50, 50])
RPNの処理
各グリッドに対してアンカーを$k$個生成します。生成するアンカーのスケール、アスペクト比は予め決めておくハイパーパラメータです。Faster R-CNNの論文に合わせて、スケールを$(128, 256, 512)$の3パターン、アスペクト比を$(0.5, 1.0, 2.0)$の3パターンで考えることにします。アンカーはそれぞれの組み合わせなので、$k=3\times3=9$となります。
アンカーは具体的には、$r$をアスペクト比、$s$をスケールとすると、
\begin{align}
h &= s\sqrt{r} ,\\
w &= \frac{s}{\sqrt{r}},
\end{align}
の高さと幅を持つボックスになります。入力画像に対するピクセルサイズなっていることに注意してください。
小数は四捨五入されます。実装は下記のとおりです。
class AnchorGenerator(nn.Module):
〜(略)〜
def generate_anchors(
self,
scales: List[int],
aspect_ratios: List[float],
dtype: torch.dtype = torch.float32,
device: torch.device = torch.device("cpu"),
) -> Tensor:
scales = torch.as_tensor(scales, dtype=dtype, device=device)
aspect_ratios = torch.as_tensor(
aspect_ratios, dtype=dtype, device=device)
h_ratios = torch.sqrt(aspect_ratios)
w_ratios = 1 / h_ratios
ws = (w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h_ratios[:, None] * scales[None, :]).view(-1)
base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2
return base_anchors.round()
各グリッドに対して生成されるアンカーを直接確認したい場合は下記のコードで確認できます。
import torch
import torchvision.models as models
from torchvision.models.detection.image_list import ImageList
from torchvision.models.detection.rpn import AnchorGenerator
backbone = models.vgg16(pretrained=True).features[:-1]
anchor_generator = AnchorGenerator(sizes=((128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
image_tensors = torch.rand((1, 3, 800, 800))
images = ImageList(image_tensors, [(800, 800)])
features = torch.rand((1, 512, 50, 50))
anchors = anchor_generator(images, features)
print(len(anchors)) # 1
print(anchors[0].shape) # torch.Size([22500, 4])
print(anchors[0][0]) # tensor([-91., -45., 91., 45.])
左上のグリッドに対するアンカーで、スケールが$128$、アスペクト比が$0.5$の場合は$128\sqrt{2}/2=90.5$、$128/\sqrt2/2=45.3$で合っていますね。アンカーの数はグリッドの数の$k=9$倍なので、$50\times50\times9=22500$になっています。
なお、anchors[0][0]はtensor([-91., -45., 91., 45.])であることから分かるように、torchvisionの実装ではアンカーが画像からはみ出してもそのまま使用しています。また、アンカーの中心位置は各グリッドの左上の座標です。つまり、下図の左の画像のようになっていると思わせて、実装では下図の右の画像のようになっています。

さて、これでアンカーが$H/16\times H/16\times k$個できたわけですが、これら全てを物体の正解バウンディングボックスと結びつけ、アンカーの変形量を予測させることは良くありません。なぜならば、物体から遠い箇所にあるアンカーをバウンディングボックスに変形させると変形量が大きくなり、予測が不正確になることが考えられるからです。
そこで、全てのアンカーの中から、正解バウンディングボックスに近いアンカーの変形量のみを損失関数で評価してバックプロパゲーションするようにします。そのためには、アンカーと正解バウンディングボックスが近いかどうかのラベルが必要になります。次のようにラベルを作成します。
- 各アンカーと各バウンディングボックスのIoUを計算します。
- それぞれのアンカーに対して次の操作をします。IoUが0より大きい正解バウンディングボックスが1つ以上存在する場合、IoUが最も大きい正解バウンディングボックスを1つ選択し、次のパターンに応じてアンカーをラベル付けします。
- 正解バウンディングボックスとIoUが
rpn_fg_iou_thresh(デフォルト$0.7$)以上のものを前景アンカーとしてラベルします。 - 正解バウンディングボックスとIoUが
rpn_bg_iou_thresh(デフォルト$0.3$)未満のものを背景アンカーとしてラベルします。 - IoUが
rpn_bg_iou_thresh以上rpn_fg_iou_thresh未満のものは前景とも背景ともいえないので、無視アンカーとしてラベルします。
- 正解バウンディングボックスとIoUが
- IoUが0より大きい正解バウンディングボックスが存在しない場合は、背景アンカーとしてラベルします。
- 以上の操作で前景アンカーとしてラベルしたアンカーに対しては、対応する正解バウンディングボックスを紐づけておきます。背景アンカー、無視アンカーとしてラベルされたアンカーに対しては、正解バウンディングボックスはありませんが、実装上は後続の処理と統一的に処理したいため、ダミーのバウンディングボックスを作成して紐づけておきます。
- 正解バウンディングボックスのうち、アンカーに紐づいていないものは、まだ紐づきがないアンカーのうちIoUが最も大きくなるものに紐づけ、前景アンカーとしてラベルします(
set_low_quality_matches_)。つまり、正解バウンディングボックスは必ず1つのアンカーと紐づきます。
アンカーのラベルのshapeは$(k, H/16, W/16)$です。また、このラベルを少し変形して前景アンカーを1、それ以外を0とすることで、各アンカー内に物体が写っているか、すなわちObjectnessの予測の正解ラベルを作成できます。
次に、アンカーの正解の変形量を計算します。アンカーの変形量は次のようなオフセット$(dx,dy,dw,dh)$形式で表します。
\begin{align}
dx^\ast &= \frac{cx^\ast-cx_a}{w_a} \\
dy^\ast &= \frac{cy^\ast-cy_a}{h_a} \\
dw^\ast &= \log\left(\frac{w^\ast}{w_a}\right) \\
dh^\ast &= \log\left(\frac{h^\ast}{h_a}\right)
\end{align}
ここで、$cx,cy,w,h$はボックスの中心座標と幅と高さを表します。添字$a$はアンカーボックスを表します。添字$*$は正解バウンディングボックスを表します。この$(dx^\ast,dy^\ast,dw^\ast,dh^\ast)$がアンカーの変形量の正解データになります。正解データのshapeは$(4k, H/16, W/16)$です。
以上をまとめます。予め決めたハイパーパラメータを用いてアンカーを生成し、正解バウンディングボックスと照らし合わせることで、Objectness(アンカー内に物体が写っているか)の正解ラベルとオフセット(アンカーの変形量)を求めました。
- Objectness: $(k, H/16, W/16)$
- オフセット: $(4k, H/16, W/16)$
RPNはこのshapeの出力を持つネットワークになっていればよいです。実装はシンプルで、畳み込みブロック1つと、1x1の畳み込みで構成されます。
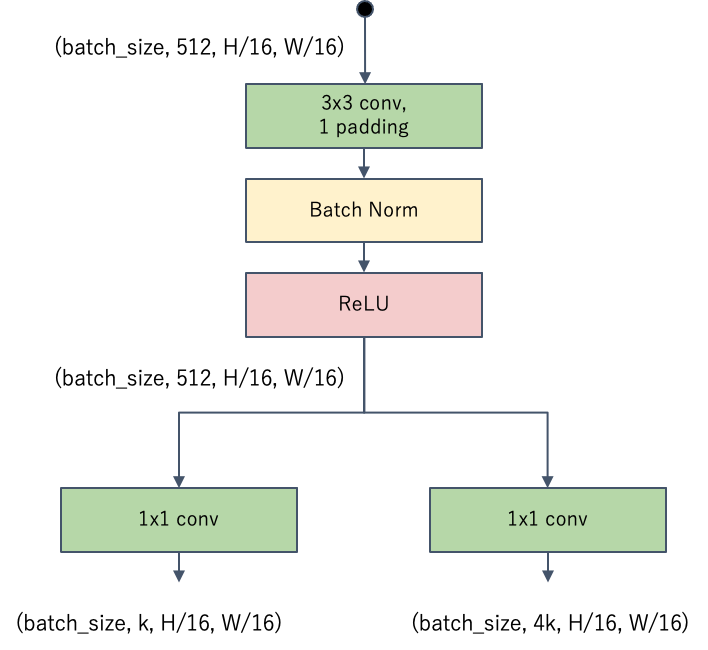
Objectnessの損失関数はBinary Cross Entropy Lossで、オフセットの損失関数はSmooth L1 Lossを使用します。
損失関数を計算する際、全てのアンカーを使わず、前景アンカーと背景アンカーをサンプリングしてから損失を計算します。サンプリング数はrpn_batch_size_per_image(デフォルト256)で、うち前景アンカーの割合はrpn_positive_fraction(デフォルト0.5)、残りは背景アンカーです。前景アンカーと背景アンカーのテンソル位置を表すインデックスを生成し、Objectnessの損失関数計算では前景アンカーと背景アンカーのインデックスの両方を、オフセットの損失関数計算では前景アンカーのインデックスのみを使用して損失を計算します。
ROI Pooling層への出力はプロポーザルです。アンカーと対応するオフセットからプロポーザルを計算できます。
\begin{align}
cx &= cx_a + w_a dx \\
cy &= cy_a + h_a dy \\
w &= w_a e^{dw} \\
h &= h_a e^{dh} \\
\end{align}
プロポーザルは次の処理でフィルターされます。
- Objectnessの大きさ順で
pre_nms_top_n個残す。 - プロポーザルを画像内に収まるようにクリップする。
- 小さすぎるプロポーザルは除外する。
-
rpn_score_threshより小さいObjectnessのプロポーザルを除外する。 -
rpn_nms_threshでNMSを実施する。 - Objectnessの大きさ順で
post_nms_top_n個残す。
これらの処理を施して、プロポーザルをROI Pooling層へ出力します。
ROI Pooling層の処理
ROI Pooling層では、backboneで抽出した特徴マップからRPNのプロポーザル部分を取り出し、その後固定長の特徴量に変換します。
Faster R-CNNの論文で使用されているROI Poolingはシンプルで、特徴マップからプロポーザル領域を切り出し、出力サイズになるように領域分割してmax poolingしているだけです。下図は$8\times8$の特徴マップから(xmin, ymin, xmax, ymax)=(2, 1, 5, 5)のROIを切り出し、$2\times2$の固定長特徴マップに変換する例です。
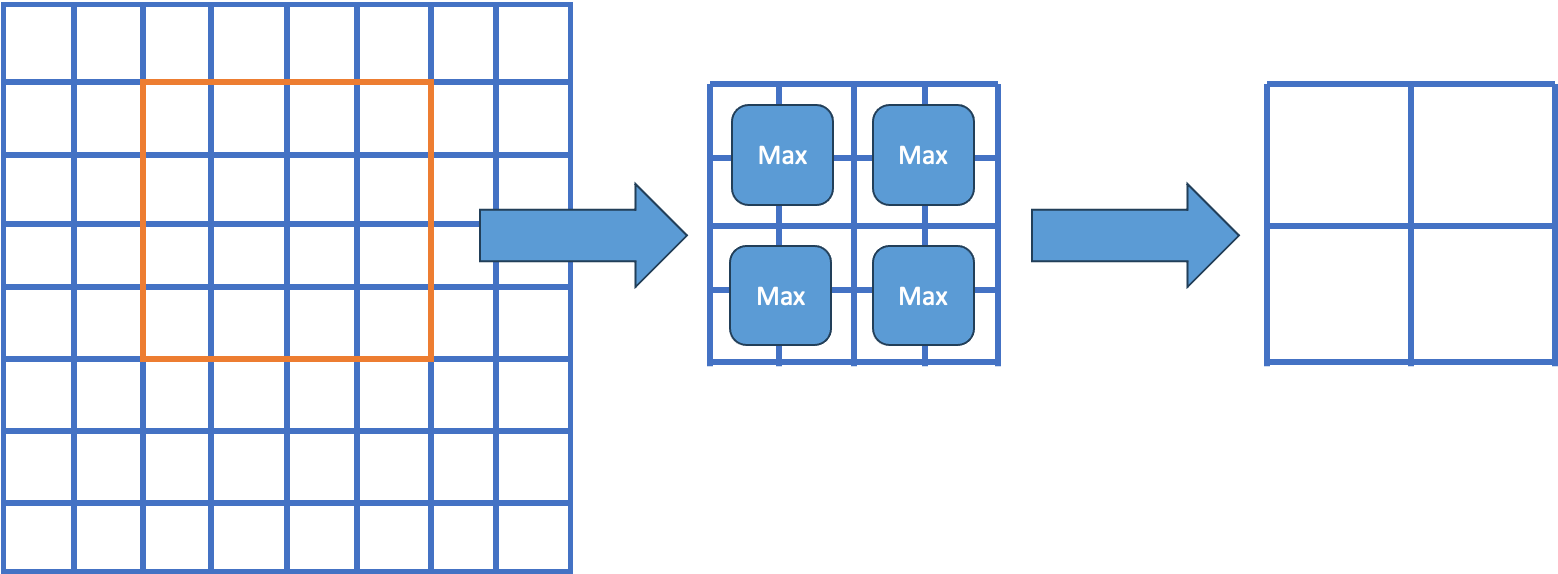
簡易実装は次のようになります。
def roi_pool(feature_map, rois, output_size):
assert feature_map.dim() == 4, "Feature map should be BxCxHxW"
pooled_outputs = []
for roi in rois:
batch_idx, x1, y1, x2, y2 = map(int, roi)
# ROIの特徴マップを取得します
region = feature_map[batch_idx, :, y1:y2, x1:x2]
# ROIを固定サイズにリサイズします
h_step = region.size(1) / output_size[0]
w_step = region.size(2) / output_size[1]
pooled_region = torch.zeros(
(feature_map.size(1), output_size[0], output_size[1]))
for i in range(output_size[0]):
for j in range(output_size[1]):
start_i = int(i * h_step)
end_i = int((i + 1) * h_step)
start_j = int(j * w_step)
end_j = int((j + 1) * w_step)
# 領域が空でないことを確認
if end_i > start_i and end_j > start_j:
max_value, _ = torch.max(
region[:, start_i:end_i, start_j:end_j], dim=1)
max_value, _ = torch.max(max_value, dim=1)
pooled_region[:, i, j] = max_value
pooled_outputs.append(pooled_region)
return torch.stack(pooled_outputs)
# ダミーの特徴マップを作成します
feature_map = torch.rand(1, 512, 50, 50)
# ダミーのRoIsを作成します
# shapeは[K, 5]で、5の方は(batch_idx, xmin, ymin, xmax, ymax)
# Kはミニバッチ中の全ROIの数
rois = torch.tensor([[0, 0, 0, 10, 10],
[0, 3, 3, 23, 33]], dtype=torch.float32)
y = roi_pool(feature_map, rois, output_size=(7, 7))
y.size() # torch.Size([2, 512, 7, 7])
RPNから出力したプロポーザルは画像サイズを基準としているので、プロポーザルのサイズを$1/16$倍して特徴マップのサイズに合わせます。
torchvisionのFaster R-CNNでは、デフォルトではMultiScaleRoIAlignが使用されます。RoIAlignでは、特徴マップ上のプロポーザルの座標を量子化せず、双線形補間を使用して、非整数座標の特徴値を得ることができます。これにより、元の特徴マップ上の正確な位置情報を維持しながら特徴を抽出することができます。MultiSscaleは、異なる解像度の特徴マップから特徴を適切に抽出する能力を意味し、Feature Pyramid Networkを使用したときの異なる解像度の特徴マップに対応することができます。
クラス予測とバウンディングボックスの回帰
RPNと同様に、予測バウンディングボックスの中から、正解バウンディングボックスに近い予測ボックスのみを損失関数で評価してバックプロパゲーションするようにしたいです。そこで、予測ボックスを出力するのに使用したプロポーザルが正解バウンディングボックスに近いもののみを使用します。RPNと同じように、ラベルを作成します。
- 各プロポーザルと各正解ボックスのIoUを計算します。
- それぞれのプロポーザルに対して次の操作をします。IoUが0より大きい正解バウンディングボックスが1つ以上存在する場合、IoUが最も大きい正解バウンディングボックスを1つ選択し、次のパターンに応じてプロポーザルをラベル付けします。
- 正解バウンディングボックスとIoUが
box_fg_iou_thresh(デフォルト$0.5$)以上のものを前景プロポーザルとしてラベルします。 - 正解バウンディングボックスとIoUが
box_bg_iou_thresh(デフォルト$0.5$)未満のものを背景プロポーザルとしてラベルします。
- 正解バウンディングボックスとIoUが
- IoUが0より大きい正解バウンディングボックスが存在しない場合は、背景プロポーザルとしてラベルします。
- 以上の操作で前景プロポーザルとしてラベルしたプロポーザルに対しては、対応する正解バウンディングボックスを紐づけておきます。背景プロポーザルとしてラベルされたプロポーザルに対しては、正解バウンディングボックスはありませんが、実装上は後続の処理と統一的に処理したいため、ダミーのバウンディングボックスを作成して紐づけておきます。
これで各プロポーザルを用いて生成する予測ボックスの正解クラスラベルと正解オフセットが与えられました。
あとはクラス予測とバウンディングボックスの回帰モジュールで出力したクラスラベルとオフセットを使用して学習すれば良いのですが、少し問題があります。学習初期ではプロポーザルの精度が悪いので、RPNが出力したプロポーザルのほとんどが背景プロポーザルになってしまい、クラス予測とバウンディングボックスの回帰モジュールをうまく訓練することができません。そこで、RPNから出力されたプロポーザル集合に、正解ボックス集合を追加して新たなプロポーザル集合とします。この新たなプロポーザル集合から合計box_batch_size_per_image(デフォルト512)個のプロポーザルをbox_positive_fraction(デフォルト0.25)の割合だけ前景プロポーザルになるようにサンプルして利用します。このプロポーザルサンプリングを予め行った上で、上記のラベル作成を行い、正解クラスラベルと正解オフセットを作成しておきます。
サンプリングしたプロポーザルをROI Pooling層に出力し、固定長特徴を生成します。固定長特徴をクラス予測とバウンディングボックスの回帰モジュールに入力します。クラス予測モジュールは予測バウンディングボックスがどのクラスであるかを予測します(クラスには背景クラスも含めます)。バウンディングボックスの回帰モジュールはRPN同様、プロポーザルに対する予測バウンディングボックスのオフセットを出力します。

クラス分類の損失関数はCross Entropy Loss、オフセットの損失関数はSmooth L1 Lossを使用します。オフセットの損失関数は前景プロポーザルから生成された予測バウンディングボックスに対してのみ計算されます。
学習モードではない推論モードではRPNから出力されるプロポーザルから固定長特徴を生成し、クラス予測とオフセット予測を行います。プロポーザルとオフセットを使用して予測ボックスを出力します。クラス分類のlogits出力はSoftmaxで確信度にします。後処理として次の処理を施します。
- 予測ボックスを画像内に収まるようにクリップする。
- 背景に分類された予測ボックスを除外する。
- テンソルをReshapeし、各クラスの予測を独立したインスタンスとして扱います。例えば1つの予測ボックスに対してCクラスの確信度がある場合、それぞれ確信度を1つ持つC個の予測ボックスとみなすことにする。
-
box_score_thresh(デフォルト0.05)未満のボックスを除外する。 - 面積が(ほぼ)ゼロのボックスを除外する。
-
box_nms_thresh(デフォルト0.5)でNMSを実行する。 - 確信度が高いトップ
box_detections_per_img(デフォルト100)だけ残す。
以上で予測ボックスとクラス確信度を出力します。
最後にFaster R-CNNのネットワーク全体図を示します。RPNからROI Poolingに出力されるテンソルはdetachされているため(点線矢印)、バックプロパゲーションはありません。したがって、RPNとHeadは独立に訓練されます。ROI Poolingの部分を微分可能にしてバックプロパゲーションさせる他の手法も検討されていたようです。

参考文献
-
Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun, "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks", https://arxiv.org/abs/1506.01497
-
"pytorch/vision: Datasets, Transforms and Models specific to Computer Vision", https://github.com/pytorch/vision
-
Kai, 「Faster R-CNNにおけるRPNの世界一分かりやすい解説」, https://medium.com/lsc-psd/faster-r-cnn%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8Brpn%E3%81%AE%E4%B8%96%E7%95%8C%E4%B8%80%E5%88%86%E3%81%8B%E3%82%8A%E3%82%84%E3%81%99%E3%81%84%E8%A7%A3%E8%AA%AC-dfc0c293cb69
-
Ankur, "Object Detection and Classification using R-CNNs", https://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/