Docker環境の用意
DockerでSparkの環境構築をしてみました。
FROM openjdk:8
ARG SPARK_VERSION=3.0.3
ARG HADOOP_VERSION=3.2
RUN wget -q http://apache.mirror.iphh.net/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz \
&& tar xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz \
&& mv spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /spark \
&& rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
EXPOSE 8080
バージョンなどについてはこちらのウェブサイトで確認しました。
docker-compose.yml
version: '3'
services:
master:
build: .
ports:
- 4040:4040
- 8080:8080
command: /spark/bin/spark-class org.apache.spark.deploy.master.Master --host 0.0.0.0
worker:
build: .
depends_on:
- master
ports:
- 8081-8089:8081
command: /spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077 --host 0.0.0.0
意外と構築まで時間がかかりました(5分程度)。
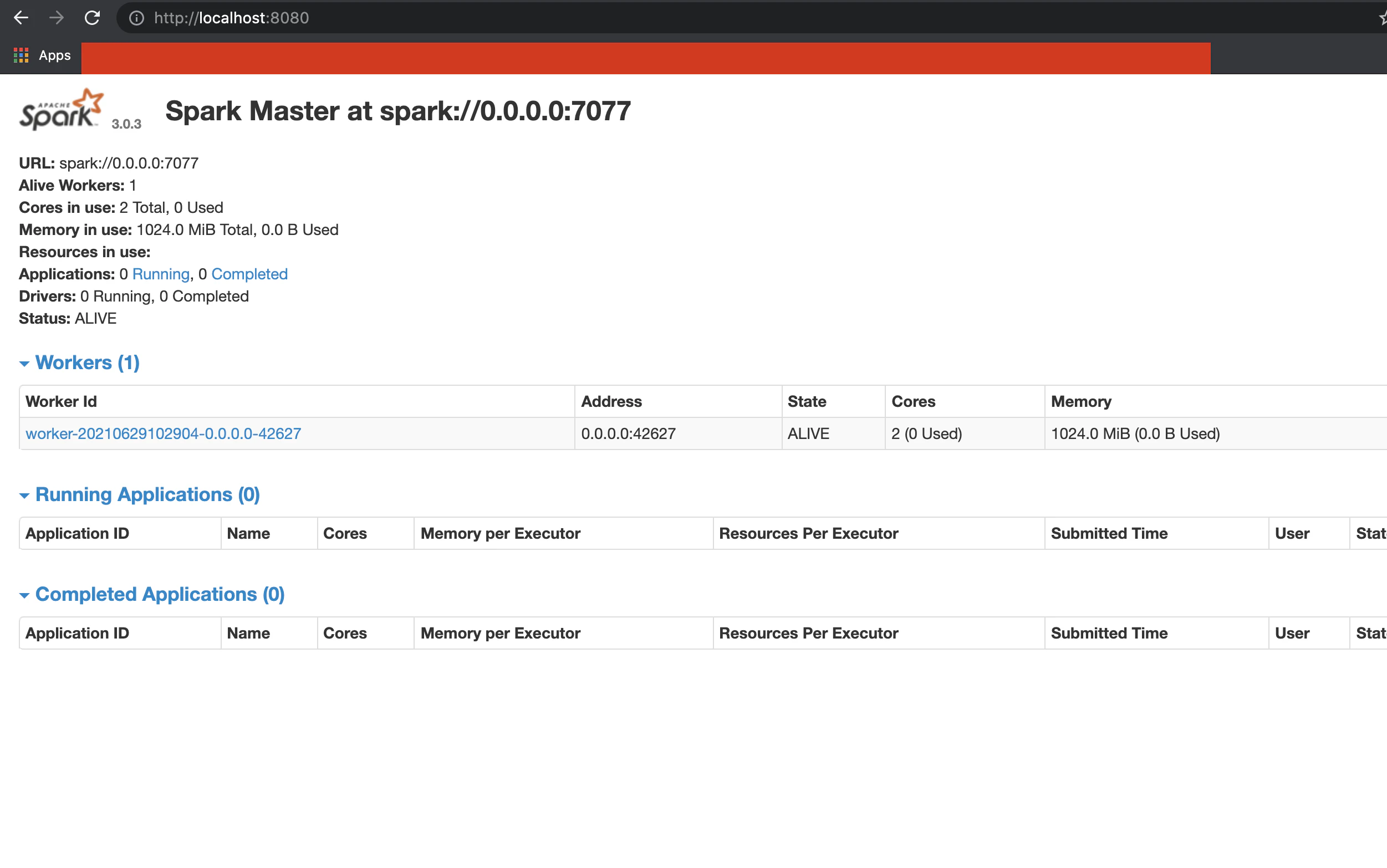
localhost:8080にアクセスすると、以下のようになっていました。
コンテナの中に入ってみる
自分のコンテナの名前であるapache-spark-experiment_master_1で入っています。
$ dx apache-spark-experiment_master_1 /spark/bin/spark-shell --master spark://localhost:7077
21/06/29 11:08:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/06/29 11:08:44 WARN SparkContext: Please ensure that the number of slots available on your executors is limited by the number of cores to task cpus and not another custom resource. If cores is not the limiting resource then dynamic allocation will not work properly!
Spark context Web UI available at http://92e2a6cc4096:4040
Spark context available as 'sc' (master = spark://localhost:7077, app id = app-20210629110845-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.3
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_292)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scalaを走らせてみる
以下のようにデータの操作を行うことができました。
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@4fa91d5b
scala> val ds = Seq(1, 2, 3).toDS()
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds.show()
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
scala> ds.map(_ * 2).show()
+-----+
|value|
+-----+
| 2|
| 4|
| 6|
+-----+
Pythonに飽きているので、これからScalaとSparkを使って色々やってみたいです。
参考文献