はじめに
みなさん、OCR (Optical Character Recognition、光学文字認識)やっていらっしゃいますでしょうか。画像上の文字情報などを読み取る技術で、いろんなところで見られるようになってきています。また、庶民でもOCR技術を使えるよう、GCPなどでも手軽に使えるようになってきています。
そこでGCPのCloud Vision APIを利用してPDF内の文字情報を読み取ろうとしていたのですが、公式ドキュメントがちょっとわかりにくい(?)気がしたのでこちらでメモがわりにまとめたいと思います。
上記のドキュメントだといろいろ大切なところが省略されている気がして、初心者の自分にとってはちょっと苦戦しました。
環境
Mac OS Mojave
Python 3.7
費用
まだ4月分の請求がわからないのですが、たぶん少ないと思います。
あと初回でもらえる無料クレジットを使っているのもあり、わかり次第更新します。
Cloud Vision APIを有効にする
Cloud Vision APIの有効化を行います。

APIとサービスからライブラリを選び、Cloud Vision APIを検索し、有効化します。

jsonの鍵ファイルを作成

IAMと管理からサービスアカウントを選び、新たなサービスアカウントの作成を行います。
以下のサービスアカウントを作成から、鍵jsonファイルを作成することが可能です。

これでパブリックキーなどが記載された鍵ファイルが作成できます。
この鍵ファイルをあとで作業ファイルに移すことになります。
Cloud Storageの準備

Storageからブラウザを選びます。そうすると、ストレージブラウザに飛ぶので、バケットを作成をクリックします。

新たなバケットを作成し、そこにOCRしたいpdfファイルをアップロードします。自分の今回のバケット名はenvironment-engineering-pdf-bucket-1で、scan-001.pdfをアップロードしました。
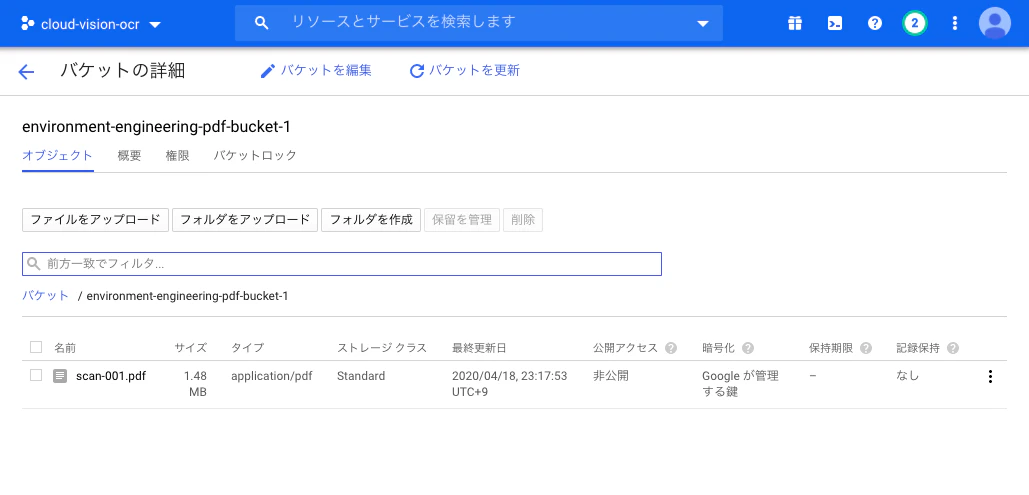
またもうひとつpdfファイルの文字情報を読み取ったものを保存しておくバケットも作成します。その名前をocr-result-bucket-qiitaとしました。
必要なモジュールのインポート
以下の3つが必要なので、importしておきましょう。virtualenvを使うのもありです。
pip install google-cloud-vision
pip install google-cloud-storage
pip install protobuf
https://pypi.org/project/google-cloud-storage/
https://pypi.org/project/google-cloud-vision/
https://pypi.org/project/protobuf/
実際のpythonの処理開始
import os
import json
import re
from google.cloud import vision
from google.cloud import storage
from google.protobuf import json_format
# ここは自分のuriに変更も自分のに変更してください
gcs_source_uri = "gs://environment-engineering-pdf-bucket-1/scan-001.pdf"
gcs_destination_uri = "gs://ocr-result-bucket-qiita"
# ここのバケット名も自分のに変更してください
bucket_name = "ocr-result-bucket-qiita"
# ここの鍵ファイルも自分のに変更してください
# JSONの鍵ファイルは同じディレクトリに置くことを忘れずに!
credential_path = 'engaged-symbol-274611-192d61800d05.json'
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
mime_type = 'application/pdf'
batch_size = 2
client = vision.ImageAnnotatorClient()
feature = vision.types.Feature(
type=vision.enums.Feature.Type.DOCUMENT_TEXT_DETECTION)
gcs_source = vision.types.GcsSource(uri=gcs_source_uri)
input_config = vision.types.InputConfig(
gcs_source=gcs_source, mime_type=mime_type)
gcs_destination = vision.types.GcsDestination(uri=f"{gcs_destination_uri}/")
output_config = vision.types.OutputConfig(
gcs_destination=gcs_destination, batch_size=batch_size)
async_request = vision.types.AsyncAnnotateFileRequest(
features=[feature], input_config=input_config,
output_config=output_config)
operation = client.async_batch_annotate_files(
requests=[async_request])
print('Waiting for the operation to finish.')
operation.result(timeout=180)
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
output = blob_list[0]
json_string = output.download_as_string()
response = json_format.Parse(
json_string, vision.types.AnnotateFileResponse())
# The actual response for the first page of the input file.
first_page_response = response.responses[0]
annotation = first_page_response.full_text_annotation
print(u'Full text:\n{}'.format(
annotation.text))
最後に例を
成功する例
以下のような画像pdfをOCRしてみました。

するとターミナルでは以下のようにタイトルは表示されました。
幻冬舎文庫
京都の中華
姜尚美
失敗する例
ただ、以下のような筆記体の文字があるページでは失敗しています。餃子が釜子と認識されているし、にんにくなしのはにんにくなのと、"し"が抜けたりしています。

出力:
目次
《釜子》
《舞》
かしんのす
にんにくなの
袋子 4
章 魚 (丸太町七本松)|
34
三絲魚翅
蕪庵(下鴨)
ごま入り皮の
水篮子
数字(净土寺)
04
親子弁のような
鳳凰蛋
芙蓉園 (河原町加条)
人公
最後に
これをepub形式などに出力することができれば、そこからmobi形式に変換してkindleで読むことも可能ですね!どれくらいコストがかかるのかはわかりませんが。。。