機械翻訳の歴史
簡単な流れは以下のよう
- ルールベース翻訳
- 統計的機械翻訳(1980年~2010年代)
欠点:Bilingual Corpusという対訳集の作成コストが高い - ニューラルネットワーク RNN 翻訳
- RNN-Encoder-Decoder (2013年頃)
欠点:Encoderの出力が固定ベクトルであるため、学習時より長文になると精度が落ちる - RNN-Encoder-Decoder(Emmbedding追加)
- RNN-Search(Attention追加) (2016年頃)
- Transformer (2018年頃)
Embedding(単語埋め込み)とは
Embeddingとは、文や単語、文字などの自然言語の構成要素のone-hotベクトルを、同じ階層の要素すべてが同じ空間に属し、かつより低次元のベクトルに変換することである。これにより、自然言語をニューラルネットワークで特徴量として扱えるようにできる。
最もシンプルな方法として、One-hot表現があり、表現したい構成要素を1、それ以外を0のベクトルへ変換する。One-hot表現では、各単語間の関係が表現できないことや、メモリ使用量が増大するなどの問題がある。
そこで、分散表現(ベクトル空間に埋め込み、その空間上のひとつの点として捉える表現) と 分布仮説(単語の意味は周囲の単語によって形成される) を用いて、king - man + woman = queenなどの計算を可能にするword2vecというものが出てくる。word2vecは、分散表現を得るための2層のニューラルネットワークで、2種類に分けられ、中心の単語から周辺の単語を予測するSkip-Gram法と周辺の単語から中心の単語を予測する CBOW(Continuous Bag-of-Words Model) がある。具体的には、CBOWでは文章における対象ワードの前後N単語のOne-hotベクトルを入力として、まず全結合層で各単語ベクトルをより小さい次元に圧縮し、Softmax関数で対象のワードのベクトルの確率を計算する。これを学習することで、始めの全結合層で分散表現が得られる。Skip-Gram法では、単語数次元のone-hotベクトルから中間層の数100次元の埋め込みベクトルを通り、予測単語のone-hotベクトルを出力する。この中間層+ルックアップテーブルを埋め込み層 (Embedding Layer)と呼ぶ。

word2vecは、別で学習して起き、単語をベクトル化して、RNNなどに入力していた。その後、LSTM・GRUやRNNLMやseq2seqが登場してから、この入力単語の低次元ベクトル変換を、埋め込み層としてモデルの一部に組み込むようになった。初期値は学習済みword2vecやGloveでファインチューニングして、埋め込み層も含めてモデルの学習を行う。
RNN-Encoder-Decoder(埋め込み層なし)

RNN-Encoder-Decoder(埋め込み層あり)

英語の文章からフランス語の文章へ翻訳するseq2seqのニューラル機械翻訳
ソースコード
処理の流れは以下のよう
- 学習データのロードと正規化・フィルターおよび単語辞書の作成
- 学習データをtext fileから読み込む
- 半角空白で区切り、ASCII正規化と修飾語や特定文字をフィルタリングする
- 指定した単語数より多い文章をフィルタリングする
- 翻訳前と翻訳後の文章がペアになった辞書の作成
- 各単語ごとの正引き・逆引き辞書と数字インデックス引き辞書を作る
- 学習用データをテンソルに変換
- 各翻訳文章ペアごとに、単語のインデックスを割り当て、テンソルにする
- 翻訳前と翻訳後のテンソルをデータローダーに読み込む
- モデルの宣言
- 入力パラメター数がすべての単語数と同じエンコーダーをインスタンス化する
- エンコーダー出力を入力パラメター数と同じデコーダーをインスタンス化する
- 学習
- 翻訳前のテンソルをエンコーダーに入力する
- エンコーダーの出力をデコーダーに入力する
- デコーダーの出力と翻訳語のテンソルで損失を計算する
- エンコーダー・デコーダーそれぞれで最適化する
- 評価
- ランダムに選んだ学習データを入力して、推論を確認する
- 推論
- 翻訳したい文章を辞書によりテンソルに変換する
- モデルに入力し、出力の最も確からしい値を取得する
- 辞書でインデックスを単語に変換して文章にする
ざっくり、単語に数字を割り当て、ベクトル化して、RNN(GRU)エンコーダーで文脈を加味した分散表現を獲得し、デコーダーで翻訳先の単語に変換している。あとは、翻訳先の文章を正解テンソルとして、エンコーダー・デコーダーそれぞれで学習する。
エンコーダー・デコーダーの仕組みは以下のグラフがわかりやすい
- Encoder

- Decoder
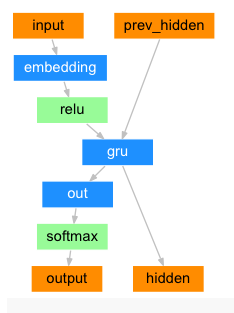
今回はチュートリアル通り、アテンションデコーダーを使用した。
- アテンションデコーダー

#from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import numpy as np
from torch.utils.data import TensorDataset, DataLoader, RandomSampler
import time
import math
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#### 1. データの読み込みと前処理
SOS_token = 0
EOS_token = 1
# 与えられた英語の文章を半角の空白で区切り、単語に分けた後、
# 正引き辞書と逆引き辞書に単語と対応する数字を格納し、出現回数の辞書を作成する
# 文の始めは、{0: "SOS"}、文の終わりは、{1: "EOS"}と定義する
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
# 単語表現を統一するため、UnicodeからASCIIに変換する
# NFD(Normalization Form D)に正規化したものが、Mark Non-Spacing(Mn:他の文字を修飾するための文字)に属していない場合、採用する
# 正規化の種類
# 正規化形式 D (Normalization Form D, 略して NFD)(分解)
# 正規化形式 C (Normalization Form C, 略して NFC)(合成)
# 正規化形式 KD (Normalization Form KD, 略して NFKD)(互換性)
# 正規化形式 KC (Normalization Form KC, 略して NFKC)(互換性)
# コードポイント(文字コードに割り当てられた番号)のカテゴリが、
# https://en.wikipedia.org/wiki/Unicode_character_property
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# 上記の正規化関数を適用し、特定文字を置換する
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
print(s)
# 指定文字の前に半角空白追加
s = re.sub(r"([.!?])", r" \1", s)
# 指定した文字以外の文字を空白に置換
s = re.sub(r"[^a-zA-Z!?]+", r" ", s)
return s.strip()
# 英語-日本語の対応テキストファイルを開いて、上記の前処理関数を適用し、Langクラスを呼び、辞書を作成する
# 入力は、lang1='eng', lang2='fra'と翻訳方向を決めるbool
def readLangs(lang1, lang2, reverse=False):
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
# センテンスの単語数の長さ
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
# 与えられた言語ペアが最大の長さを超えていないか、英語の接頭辞で始まっているかどうかを確認し、そのBoolを返す
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH #and \
#p[1].startswith(eng_prefixes)
# 与えられた言語ペアのリストをフィルタリングし、各ペアがfilterPair関数で定義された条件を満たす場合に、新しいリストに追加
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
# 指定された2つの言語のファイルを読み込み、辞書を作成し、上記のフィルタリングを適用し、最終的に言語ごとの単語の数を出力
def prepareData(lang1, lang2, reverse=False):
# input_lang, output_langはLangクラスのインスタンス
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("読み込んだ文章のペアー : %s 個" % len(pairs))
pairs = filterPairs(pairs)
print("フィルターを通過した文章のペアー : %s 個" % len(pairs))
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("それぞれの単語の数(重複除く)")
print(input_lang.name, input_lang.n_words, '個')
print(output_lang.name, output_lang.n_words, '個\n')
return input_lang, output_lang, pairs
#### 3. モデル定義
# One-hotベクトルを分散表現にするため、EmbeddingとGRU(Gated Recurrent Unit)で構成
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
# 入力サイズと隠れテンソルのサイズ分のID付きベクトルを作成
# nn.Embedding: 固定長の辞書埋め込みを保存するシンプルなルックアップテーブル
self.embedding = nn.Embedding(input_size, hidden_size)
# 隠れテンソルのサイズ分のGRUを定義
# 文脈にそって,各トークンの意味(=トークン表現ベクトルの値)を変えるようにする
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, hidden = self.gru(embedded)
return output, hidden
# ※使用していない
# EncoderRNNの出力と隠れ状態を受け取り、ターゲットのシーケンスを生成する
# SOS_token(開始トークン)を使用し、ループを通じてデコーダの出力を生成
# ターゲットテンソルが与えられた場合は、Teacher forcingと呼ばれる手法を使用して次の入力としてターゲットを与える
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
return decoder_outputs, decoder_hidden, None # We return `None` for consistency in the training loop
def forward_step(self, input, hidden):
output = self.embedding(input)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output)
return output, hidden
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.Wa = nn.Linear(hidden_size, hidden_size)
self.Ua = nn.Linear(hidden_size, hidden_size)
self.Va = nn.Linear(hidden_size, 1)
def forward(self, query, keys):
scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys)))
scores = scores.squeeze(2).unsqueeze(1)
weights = F.softmax(scores, dim=-1)
context = torch.bmm(weights, keys)
return context, weights
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1):
super(AttnDecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.attention = BahdanauAttention(hidden_size)
self.gru = nn.GRU(2 * hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout_p)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
attentions = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden, attn_weights = self.forward_step(
decoder_input, decoder_hidden, encoder_outputs
)
decoder_outputs.append(decoder_output)
attentions.append(attn_weights)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
attentions = torch.cat(attentions, dim=1)
return decoder_outputs, decoder_hidden, attentions
def forward_step(self, input, hidden, encoder_outputs):
embedded = self.dropout(self.embedding(input))
query = hidden.permute(1, 0, 2)
context, attn_weights = self.attention(query, encoder_outputs)
input_gru = torch.cat((embedded, context), dim=2)
output, hidden = self.gru(input_gru, hidden)
output = self.out(output)
return output, hidden, attn_weights
#### 4. 学習用テンソル作成
# Lang辞書を用いて、センテンスをインデックス数値のベクトル化
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
# 数値配列をテンソル化
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(1, -1)
# 単語をテンソル化する ※使用していない
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
# データを読み込み、文章をテンソル化して、データローダーで読み込み、学習データを出力する
def get_dataloader(batch_size, reverse):
# 'eng'と'fra'の言語ペアを読み込み、input_lang、output_lang、およびpairsに保存します。
input_lang, output_lang, pairs = prepareData('eng', 'fra', reverse)
# ペアの数を取得します。
n = len(pairs)
# ペアの数次元の0のテンソルを作成する
input_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
target_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
# 各ペアに対して、それぞれの言語の文を単語のインデックスのリストに変換します。
for idx, (inp, tgt) in enumerate(pairs):
inp_ids = indexesFromSentence(input_lang, inp)
tgt_ids = indexesFromSentence(output_lang, tgt)
inp_ids.append(EOS_token)
tgt_ids.append(EOS_token)
# 各ペアーのインデックスに、単語ベクトルをインデックスリストとして代入する
input_ids[idx, :len(inp_ids)] = inp_ids
target_ids[idx, :len(tgt_ids)] = tgt_ids
# 各文章の単語を辞書インデックス数字に置き換えたベクトルの集合をテンソル化して、データセットとする
# torch.LongTensor: 64bitの符号付き整数テンソル
train_data = TensorDataset(torch.LongTensor(input_ids).to(device),
torch.LongTensor(target_ids).to(device))
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
return input_lang, output_lang, train_dataloader
#### 5. 学習
def train_epoch(dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion):
total_loss = 0
# 各入力センテンスのテンソルと翻訳語のセンテンスのテンソルごとに損失計算
for data in dataloader:
input_tensor, target_tensor = data
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# エンコーダーに入力
encoder_outputs, encoder_hidden = encoder(input_tensor)
# デコーダーに入力
decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, target_tensor)
# デコーダーの出力テンソルと正解テンソルで損失を計算
loss = criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)),
target_tensor.view(-1)
)
# モデル内のすべてのテンソルの勾配を計算
loss.backward()
# 学習率と最適化手法に基づいてモデルパラメータの更新
encoder_optimizer.step()
decoder_optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def train(train_dataloader, encoder, decoder, n_epochs, learning_rate=0.001, print_every=100, plot_every=100):
start = time.time()
plot_losses = []
print_loss_total = 0
plot_loss_total = 0
# 最適化手法をAdamと定義
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
# 交差エントロピー:Negative Log-Likelihood Loss
criterion = nn.NLLLoss()
for epoch in range(1, n_epochs + 1):
# 学習
loss = train_epoch(train_dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if epoch % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, epoch / n_epochs),
epoch, epoch / n_epochs * 100, print_loss_avg))
if epoch % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
plt.show()
hidden_size = 128
batch_size = 32
reverse = False
# 学習用データの準備
input_lang, output_lang, train_dataloader = get_dataloader(batch_size, reverse)
# モデルのインスタンス化
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = AttnDecoderRNN(hidden_size, output_lang.n_words).to(device)
# モデルの学習
n_epochs = 80
train(train_dataloader, encoder, decoder, n_epochs, print_every=5, plot_every=5)
# モデルの保存
torch.save(encoder.state_dict(), 'encoder_model_weight.pth')
torch.save(encoder, 'encoder_model.pth')
torch.save(decoder.state_dict(), 'decoder_model_weight.pth')
torch.save(decoder, 'decoder_model.pth')
#### 6. 評価 : 辞書内の文章を入力して、正解文が返ってくるか確認
def evaluate(encoder, decoder, sentence, input_lang, output_lang):
with torch.no_grad():
# 入力テンソルを取得
input_tensor = tensorFromSentence(input_lang, sentence)
# エンコーダーに入力
encoder_outputs, encoder_hidden = encoder(input_tensor)
# デコーダーに入力
decoder_outputs, decoder_hidden, decoder_attn = decoder(encoder_outputs, encoder_hidden)
_, topi = decoder_outputs.topk(1)
decoded_ids = topi.squeeze()
decoded_words = []
for idx in decoded_ids:
if idx.item() == EOS_token:
decoded_words.append('<EOS>')
break
# 辞書からインデックスを用いて、文字を取得し直し、リストに追加
decoded_words.append(output_lang.index2word[idx.item()])
return decoded_words, decoder_attn
# n回学習データからペアーを取得して、上記の推論関数に入力して、結果を取得している
def evaluateRandomly(encoder, decoder, n=10, reverse=True):
input_lang, output_lang, pairs = prepareData('eng', 'fra', reverse)
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words, _ = evaluate(encoder, decoder, pair[0], input_lang, output_lang)
# 取得した結果のリストを半角空白でつなげて文字列にする
output_sentence = ' '.join(output_words)
print('<', output_sentence, '\n')
encoder.eval()
decoder.eval()
evaluateRandomly(encoder, decoder, 10, reverse)
#### 7. 推論 : 新しい文章を入力して正しく翻訳されるか確認
def showAttention(input_sentence, output_words, attentions):
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.cpu().numpy(), cmap='bone')
fig.colorbar(cax)
# Set up axes
xlabels = [''] + input_sentence.split(' ') + ['<EOS>']
ylabels = [''] + output_words
ticks_loc = ax.get_xticks().tolist()
ax.xaxis.set_major_locator(ticker.FixedLocator(ticks_loc))
ax.xaxis.set_major_formatter(ticker.FixedFormatter(xlabels))
ticks_loc = ax.get_yticks().tolist()
ax.yaxis.set_major_locator(ticker.FixedLocator(ticks_loc))
ax.yaxis.set_major_formatter(ticker.FixedFormatter(ylabels))
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
fig.tight_layout()
plt.show()
def evaluateAndShowAttention(input_sentence):
output_words, attentions = evaluate(encoder, decoder, input_sentence, input_lang, output_lang)
print('input =', input_sentence)
print('output =', ' '.join(output_words))
showAttention(input_sentence, output_words, attentions[0, :len(output_words), :])
# 保存したモデルの読み込み
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
encoder.load_state_dict(torch.load('encoder_model_weight.pth'))
decoder = AttnDecoderRNN(hidden_size, output_lang.n_words).to(device)
decoder.load_state_dict(torch.load('decoder_model_weight.pth'))
# フランス語 => 英語
#evaluateAndShowAttention('il n est pas aussi grand que son pere')
#evaluateAndShowAttention('je suis trop fatigue pour conduire')
#evaluateAndShowAttention('je suis desole si c est une question idiote')
#evaluateAndShowAttention('je suis reellement fiere de vous')
# 英吾 => フランス語
evaluateAndShowAttention('he is not as tall as his father')
evaluateAndShowAttention('i m too tired to drive being killed')
evaluateAndShowAttention('i m sorry if this is a stupid question')
evaluateAndShowAttention('i m really proud of you of you')
論文
word2vec
Efficient Estimation of Word Representations in Vector Space, Tomas Mikolov et al., 2013
RNN-Encoder-Decoder(seq2seq)
Sequence to Sequence Learning with Neural Networks, Ilya Sutskever et al., 2014
Attention(Soft Dot-product Attention)
Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau et al., 2014
Transformer
Attention Is All You Need, Ashish Vaswan et al., 2018
参考文献