不得意な問題が多めで完全に出遅れました。
A - Integer Sum
sum を使うだけ。
結果
main = getLine >> getLine >>= print . sum . map read . words
B - Everyone is Friends
シグネチャを決める。ki,xij は原理主義者なら [(Int,[Int])] とするべきだが日和る。
abc272b :: Int -- N
-> Int -- M
-> [[Int]] -- ki,xij
-> Bool -- 答え
abc272b n m kxss = ...
二人の組み合わせが $_N C_2 = N (N-1) / 2 \leq 4950$ とおり、
それらが全て出現したか、表を作って確認する。
結果
Data.Set を用いて $(x_i,x_j)$ の個数を数えるやり方:
import Data.List
import qualified Data.Set as S
abc272b :: Int -> Int -> [[Int]] -> Bool
abc272b n m kxss = (div (n * pred n) 2 == S.size s -- 6. 全て現れたか
where
s = S.fromList -- 5. 重複なしで集めて
[ (x,y) -- 4. ペアを作って
| kxs <- kxss -- 1. 全ての ki,xi1,...,xi(ki) について
, (x:ys) <- tails $ tail kxs -- 2. 先頭のkを落として、全てのxについて
, y <- ys -- 3. 全てのxより後ろのyについて
]
(10-11追記:2.のところで tails が抜けていました。訂正しました。)
Data.Array を用いて、チェック表を作るやり方:
import Data.List
import Data.Array
abc272b :: Int -> Int -> [[Int]] -> Bool
abc272b n m kxss = n * pred n == (length $ filter id $ elems a)
where
a = accumArray (||) False ((1,1),(n,n)) -- (i,j)が現れたらTrueなチェック表
[ ((x,y), True)
| kxs <- kxss -- この辺同じ
, (x:ys) <- tails $ tail kxs
, y <- ys
]
C - Max Even
シグネチャを決める。
abc272c :: Int -- N
-> [Int] -- Ai
-> Int -- 答え
2つの数を足して偶数を作るには、「偶数+偶数」か「奇数+奇数」のどちらかにする必要がある。
なるべく大きな値を作るには、最大値と次点を使うしかない。
2つ揃わない場合への例外対応が必要。
結果
最大値と次点は丁寧に調べれば、一度に $O(N)$ で求められるが、遅延評価込みならソートでもきっと変わらないだろうということで手抜きする。
import Data.List
abc272c :: Int -> [Int] -> Int
abc272c n as = max (sub es) (sub os)
where
(es, os) = partition even as
sub xs@(_:_:_) = -- xsが長さ2以上であることをパターンで確認
sum $ take 2 $
sortBy (flip compare) xs
sub _ = -1 -- 足りない場合はエラー値
D - Root M Leaper
シグネチャを決める。
abc272d :: Int -- N
-> Int -- M
-> [[Int]] -- 答え
abc272d n m = ...
考える
まず、出発点からユークリッド距離が $\sqrt M$ になる、つまり距離の2乗が $M$ になるような相対位置のリストを作っておく。浮動小数点の平方根と丸めを持ち出すと計算誤差の不安があるので、整数だけで処理したい。
$k^2$ を $k$ に対応づけるマップを作っておき、これを検索することで平方根の計算に替える。
import qualified Data.IntMap as IM
-- 距離^2がMになる相対位置のリスト
distm :: Int -> [(Int,Int)]
distm m =
[ p -- 4. リストに集める
| x <- cands -- 1. 候補xに対して
, Just y <- [IM.lookup (m - x * x) isq] -- 2. x^2+y^2=Mとなるようなyがあれば
, p <- [(x1,y1) | x1 <- pm x, y1 <- pm y] -- 3. (±x,±y)の最大4つを
]
where
cands = takeWhile ((m >=).(^ 2)) [0..] -- √M以下の整数
isq = IM.fromAscList [(i * i, i) | i <- cands] -- 平方の逆引き表
pm x = [- x | x > 0] ++ [x] -- [-x, x] または [0]
あとは、$\{(1,1)\}$ から出発して、次に進めるマスがなくなるまで、次に進めるマスを幅優先探索で探せば、反復の回数がすなわち距離になる。
distで作った次の位置を全て単純にリストで連結すると、重複が起きて無駄な計算が爆発する。これを除去することも考える必要がある。
命令型な書き変えられる配列があれば、初期値を未到達のフラグ -1 としておき、次に進む位置の候補として見つけた瞬間に距離を書き込んでしまう。すると、同じ回で重複して次の候補として挙げられても、距離が記入済みとして却下される。というアプローチでData.Array.STを用いてACしたが、とてもかっこわるい上になんか遅い。
表は後で作る
幅優先探索の結果を表に随時書き込む方法では、幅優先探索の引数として出発点からの移動回数を持たせ、更新していく表も持たせ、最後に完成した表が返る形になっていた。
bfs :: Int -- 移動回数
-> Array (Int,Int) Int -- 更新される距離の表 は、訪問済みチェック表を兼ねる
->[(Int,Int)] -- 今回訪問するマスのリスト
-> Array (Int,Int) Int -- 答え 距離の表
幅優先探索の反復回数がそれぞれのマスに対して欲しい値なので、それぞれの探索で「次に探索するべきマスの集合」を見つけたとき、これに対する距離を表に書き込む代わりに、「今回の反復で見つけたマスの集合」を毎回その場で出力してしまうようにする。
bfs :: PointSet -- 訪問済みのマスの集合
-> PointSet -- 今回訪問するマスの集合
-> [PointSet] -- それぞれの反復で訪問したマスの集合
この結果を使って、配列に結果をまとめて書き込むことができる、という方針で書いてみる。
import qualified Data.Set as S
import Data.Array
type PointSet = S.Set (Int,Int)
abc272d :: Int -> Int -> [[Int]]
abc272d n m = chunksOf n $ elems arr
where
ps = bfs S.empty (S.singleton (1,1))
arr = accumArray (flip const) (-1) ((1,1),(n,n))
[(xy, d) | (d, xys) <- zip [0..] ps, xy <- S.elems xys]
ds = distm m
bfs :: PointSet -> PointSet -> [PointSet]
bfs ps ns
| S.null ns = []
| otherwise = ns : bfs ps1 ns1
where
ps1 = S.union ps ns
ns1 = S.fromList
[ xy1
| (x,y) <- S.elems ns, (dx,dy) <- ds
, let xy1@(x1,y1) = (x + dx, y + dy)
, 1 <= x1, x1 <= n
, 1 <= y1, y1 <= n
, S.notMember xy1 ps1
]
chunksOf _ [] = []
chunksOf n xs = let (as,bs) = splitAt n xs in as : chunksOf n bs
結果
Data.Set に比べて Data.IntSet は速いはずなので、座標を $(1,1) \sim (N,N)$ の代わりに $(0,0) \sim (N-1,N-1)$ で考える。
そして座標 $(x,y)$ を整数 $Nx + y$ で表す。
xy2i x y = x * n + y
i2xy i = divMod i n
こうして上の Data.Set の計算を Data.IntSet に差し替えたらACした。
Setに比べてタイムがかなり上がっている。
E - Add and Mex
シグネチャを決める。
abc272e :: Int -- N
-> Int -- M
-> [Int] -- Ai
-> [Int] -- 答え M個
$N,M$ の上限が大きいので、$O(NM)$ とかにならないように気を付ける必要がある。
(※ 以下、公式解説と異なる、垢抜けない解答)
横軸に操作回数、縦軸に数列の値をプロットする。
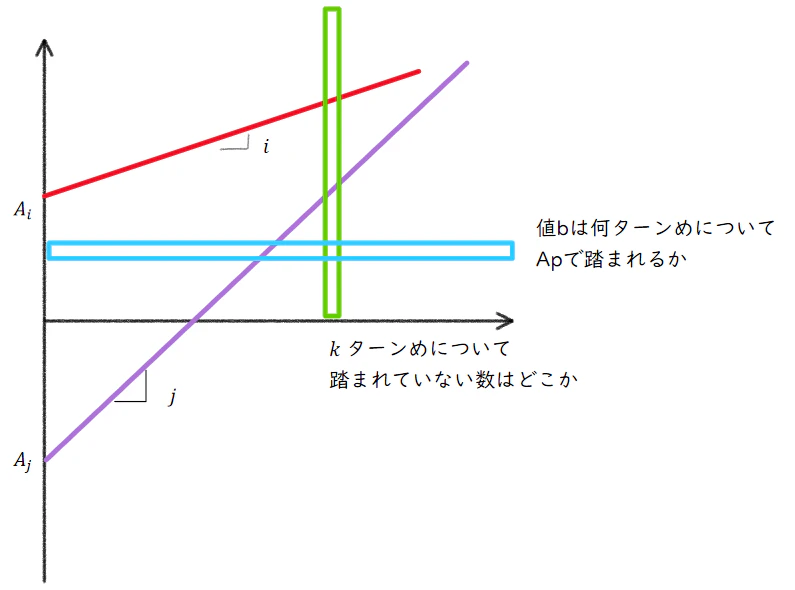
各 $k \; (1 \leq k \leq M)$ ターンめについて、縦の緑色の枠で、数列に踏まれていない最小の値を探すことが目標。
MEXを効率的に求めるには、「出現していない数の区間」を管理するような方法を使うが、この問題ではそれを$M$回も行うことになる。
$i$ 回めの操作後の整数集合のMEXから、$i+1$回めの操作後のMEXを効率的に作る方法がありそうにもない。
性質を検討する。第 $k$ ターンでの数列の第 $i$ 要素を $x_{i,k} = A_i + ik$ とする。これは正の傾き $i$ で増加する直線になる。
数列の第 $i$ 要素は各ターンについて一か所でしか影響を及ぼさない(緑色の枠との交点はたかだか1か所)なのは当たり前だが、横向きにも同じことがいえる。
すなわち、ある値 $b$ が数列の第 $i$ 要素に横切られるのは何ターンめか、は、解はたかだか1つしかない。(横長の水色の枠との交点はたかだか1か所、実際には傾きは1以上なので飛ばされて、踏まれていない $b$ も多い。)
すると、$b = 0$ について、$b$ を踏むような項 $x_{i,k} = 0$ が存在しないターン $k$ については、MEXは0であるとわかる。
0が踏まれているようなターンについてのみ、$b = 1,2,\dots$ と調べていけばよい。
全部で$NM$個ある $x_{i,k}$ を $b$ の順で徐々に検討するには、優先度付きキューが使える。
$x_{i,k}$の値をキー、$i,k$ を値とし、$i$ ごとに一つの値だけをキューに入れる。
また、それぞれのターン $k$ について、まだ踏まれていると判明していない最小の値を配列に持つ。(mexm :: IntMap Int Int)
また、MEXが判明していないターン番号 $k$ の集合も持っておく。(nfys :: IntSet : not found yet)
キューの先頭が $(b = x_{i,k}, (i,k))$ であるとき、それ未満の値は今後キューから現れることはない。よって、maxm が $b$ 未満の値であるようなターン全てについて、その値がMEXとして確定する。
そして、ターン $k$ については、$b$ が踏まれたので、mexm を $k+1$ に更新する。
その後、この$x_{i,k}$ について次に注意するべき値をキューに投入する。これは $(x_{i,k+1}, i, k + 1)$とは限らない。ターン $k+1$ の MEX が確定済みである場合、これは飛ばすことができる。
実際には、maxm が $b$ 未満の全てのターンについて確定させることは難しいので、$k$ のみを nfys から除く。そして、nfys を参照することで、まだMEXの確定していない、$k+1$ 以降の直近のターン番号を知ることができる。
結果
キューには Data.Heap を用いる。
import Control.Monad
import qualified Data.ByteString.Char8 as BS
import Data.Char
import Data.List
import qualified Data.IntSet as IS
import qualified Data.Heap as H
import qualified Data.IntMap as IM
abc272e :: Int -> Int -> [Int] -> [Int]
abc272e n m as = [IM.findWithDefault 0 k mexm | k <- [1..m]]
where
-- Ai<0なものは、ターンが1からでなく途中から始まる
q0 = H.fromList
[ H.Entry (ai + i * k) (i,k)
| (i,ai) <- zip [1..] as
, let k = if ai < 0 then max 1 $ negate (div ai i) else 1 ]
mexm :: IM.IntMap Int
mexm = loop (IS.fromList [1..m]) q0 IM.empty
loop :: IS.IntSet -> H.Heap (H.Entry Int (Int,Int)) -> IM.IntMap Int -> IM.IntMap Int
loop nfys h mexm
-- 全てMEXが判明したら終了
| IS.null nfys = mexm
| otherwise =
case H.uncons h of
-- キューが空なら終了
Nothing -> mexm
-- kについてMEXを確定させる
Just (H.Entry x (i,k), h1) -> loopsub nfys mexm x i k h1
-- 変数が多くなったので補助関数に飛ばす
loopsub nfys mexm x i k h1
-- kが確定済みならスルー
| IS.notMember k nfys = loop nfys h2 mexm
| otherwise =
case compare mexk x of
-- mexkはxより小さいのでその値がkのMEXに確定
LT -> loop (IS.delete k nfys) h2 mexm
-- mexkを踏んだので、mexk+1する
EQ -> loop nfys h2 (IM.insert k (succ mexk) mexm)
-- 他の項で既に踏んだ後なので何もしない(という場合は起こらないはず)
GT -> loop nfys h2 mexm
where
mexk = IM.findWithDefault 0 k mexm
-- 次にMEXが未確定のターンまで進める
h2 = case IS.lookupGT k nfys of
Nothing -> h1
Just j -> H.insert (H.Entry (x + i * (j - k)) (i,j)) h1
結果はTLE。
MEX配列を Data.Vector.Muboxed.Mutable にしてSTモナドで命令的な計算にしても届かなかった。
ここで天啓。
Data.Heap はあまり速くないので、要素の重複がないことが保証できるなら Data.Set で代用した方が速度が稼げる。
$x_{i,k}$ を優先度と捉えると、普通に重複するため無理そうだが、$(x_{i,k},i,k)$ というタプル全体で見れば$i$は必ず他と異なる。ということでそれも入れたらACできた。
解説から、$x_{i,k} \leq N$ の範囲だけ考えればよくて、$N$ を超えた場合はキューに追加しないロジックを足すことでとさらに少し速くできた。
解説を見る
確認のため公式解説を見たら、全く方針が違う。
$0 \leq b \leq N, 1 \leq k \leq N$ の範囲に収まる $x_{i,k}$ だけを丁寧に狙って生成すると実はそんなに個数はなくて(後述)、それを $k$ ごとに分けて集め、存在しない値を線形に見つけても間に合う、と言っている。
上の解答は、「丁寧に生成」がキューにより偶然達成されているところだけが似ている感じ。(開始位置は計算で求め、一つずつ作り、回数がMまたは値がNを超えたところで止める。)
どれどれ。
abc272e :: Int -> Int -> [Int] -> [Int]
abc272e n m as = map findmex $ elems arr
where
-- k ごとに x_ik を集める
arr = accumArray (flip (:)) [] (1,m)
[ p
| (i,a) <- zip [1..] as
, a <= n
-- a<0のとき、⌈-a / i⌉ ターン以降で有効範囲
, let k1 = if a >= 0 then 1 else negate (div a i)
-- 終了ターンはa + ik ≦ N となる上限 ⌊N-a/i⌋ または m
, let km = min m $ div (n - a) i
, let ak1 = a + i * k1
-- ターンごとの k と x_ik
, p <- zip [k1..km] [ak1, ak1 + i ..]
]
-- ターンごとに、存在する x_ikを避けてMEXを探す
findmex xs = head [i | (i, True) <- assocs arr]
where
arr = accumArray (&&) True (0,n) [(x, False) | x <- xs]
accumArray よりも単純な処理の findmex の方がネックになっている気がして、こちらを unboxed vector にしてみる。
findmex xs = ans
where
v0 = UV.replicate (succ n) True
v1 = UV.accum (&&) v0 [(x, False) | x <- xs]
Just ans = UV.findIndex id v1
通った。 mutable でない vector の UV.findIndex やら UV.accum が使える場面なんて珍しい気が。
もう少し手を抜いてみるということで、単に findmex 内の配列を Unboxed にしてみる。
import qualified Data.Array.Unboxed as UA
findmex xs = head [i | (i, True) <- UA.assocs arr]
where
arr :: UA.UArray Int Bool
arr = UA.accumArray (&&) True (0,n) [(x, False) | x <- xs]
今までで一番速いってどういうことなの…もう何も信じない…
公式解説の「大事な値」とは、ターン $1 \leq k \leq M$ の範囲で値 $0 \leq b \leq N$ に入るような数列の値のこと。全部で $N$ 個の値がみっしり並んでも $0$ から $N-1$ が限度で、MEX は $N$ 以下になるから。
それぞれの数列の項 $A_i$ は速度 $i$ で増加するので、$0 \leq b \leq N$ の範囲を踏める回数はたかだか $\lfloor N + 1/ i \rfloor$ 回。大事な範囲に付く足跡の個数はこれを $1 \leq i \leq N$ について足し合わせた $N \log N$だ、という数学的直観があればこういうアプローチができたということですか…
ここでの教訓は「型宣言を面倒がらずに、使えるときは Data.Array.Unboxed を積極的に使おう」かも。
感想
今回はボロボロだった。Fもわからない。
E別解
(2022-10-11追記)
整理できたので説明させて下さい。上記のオリジナル解を発展させた完成形です。
全てのターンを同時に、MEXの候補値を0から順に、反復して調べる。
反復関数 loop の引数は
-
ts: まだMEXの確定していないターン番号の整数集合 -
b: 今から調べるMEXの候補の値(これ未満のMEXを持つターンは全て判明している) -
q: $x_{i,k}$ の優先度付きキュー(的な何か)
結果はHaskellらしく、ターン番号とそのMEX値の対 (t,b) のリストで随時出力する。命令的な言語なら配列にその場で書き込めばよいだろう。
初期値は ts が $\{1, \dots, M\}$ 全体、b が $0$、q は数列のそれぞれの項 $A_i$ について $(A_i + ik, i, k)$ を第1要素の順に、ただしそれが0からNまでの間に入る最小の $k$ (で1からMまでのもの)を選ぶ。(今までと同じ)
繰り返しの動作は:
-
tsが空なら、仕事は全て完了したので終わる。 -
qが空なら、tsの要素のMEXは全てbで確定して終わり。 - そうでないとき、
qから第1要素がbと等しいものq1と、それより大きいものq2に分ける。(*1)-
q1が空なら、qが空のときと同じで終わり。 -
q1の要素の k の中で、ts に含まれているものを集めると、これが次の反復のためのtsになる。これをts1とする。 -
tsの中で、ts1に含まれないものは、MEXがbで確定するのでそう出力する。 -
q1の各要素 $(x_{i,k}, i, k)$ について、「$k$ より大きなts1の最小要素(*2)、つまりまだ調べる必要のある直近のターン」に進めたものをq2に追加する。(ただし値が $N$ を超えたら捨てる。)これをq3とする。 -
ts1,b+1,q3で次の反復に進む。
-
(*1) を普通に優先度付きキューですると、b と等しいものである間、前から一つずつ取り出す、とやって $O(N \log N)$ かかるが、Haskellの Data.Set.split の「ピボットとの比較で二分割」は $O(\log N)$ で動く。これで b と等しい要素をまとめて取り出せる。
(*2) Data.IntSet.lookupGT により $O(\log N)$ でこれを見つけられるのも効いている気がする。
結果
import qualified Data.IntSet as IS
import qualified Data.Set as S
import qualified Data.Array.Unboxed as UA
abc272e :: Int -> Int -> [Int] -> [Int]
abc272e n m as = UA.elems arr
where
-- 結果をまとめて出力
arr :: UA.UArray Int Int
arr = UA.array (1,m) $ loop 0 (IS.fromList [1..m]) q0
-- キューの初期値
q0 = S.fromList
[ (x,i,k)
| (i,ai) <- zip [1..] as
, let k = if ai >= 0 then 1 else max 1 $ negate (div ai i)
, k <= m
, let x = ai + i * k
, x <= n] -- なくても動くけど
-- 反復計算
loop :: Int -> IS.IntSet -> S.Set (Int,Int,Int) -> [(Int,Int)]
loop b ts q
| IS.null ts = []
| S.null q = [(t,b) | t <- IS.toList ts]
| S.null q1 = [(t,b) | t <- IS.toList ts]
| otherwise = foldr (:) (loop (succ b) ts1 q3) out -- out ++ loop (succ b) ts1 q3
where
(q1,q2) = S.split (b, maxBound, 0) q -- 優先度がbであるものを取り出し
ts1 = IS.fromList [k | (_, _, k) <- S.toList q1, IS.member k ts]
out = [(t,b) | t <- IS.toList ts, IS.notMember t ts1]
q3 = foldl (flip S.insert) q2
[ (x+i*(k1-k),i,k1)
| (x,i,k) <- S.toList q1
, Just k1 <- [IS.lookupGT k ts1]]
これでACした。
Data.IntSet の性能のおかげだろうか。
E 別解2
(2022/10/11夜追記)
もっといい感じになったので説明させて下さい。
キュー的な$x_{i,k}$の生成と、ターンごとの素朴なMEX探索の組み合わせです。
数列のそれぞれの項について、大事な範囲(ターン数1から$M$、値0から$N$)に入る最初の値を、ターン番号ごとに分けてまとめる。公差も添える。
xiss1 :: Array Int (Int,Int)
xiss1 = accumArray (flip (:)) [] (1,m)
[ (k, (a + i * k, i))
| (a, i) <- zip as [1..]
, a + i <= n
, let k = if a + i >= 0 then 1 else negate (div a i)
, k <= m
]
この配列の要素列は、既に使っているものについては公差を足しこむ、今回から加わるものはそのまま加えることで、各ターンの $x_{i,k}$ の値を順に作ることができる。
xiss2 = scanl1 step $ elems xiss1
step xis xis1 = xis1 ++ [(x1,i) | (x,i) <- xis, let x1 = x + i, x1 <= n]
これの左項だけ取り出してMEXを見つければ答えが得られる。
abc272e n m xs = map (findmex . map fst) xiss2
where
...