はじめに
コードリーディングの重要性はそこらじゅうで語り尽くされてる感があります。
僕も地道にコードリーディングをしているのですが、いざやろうとするとハードルが高いことがままあります。そこで、個人的にコードリーディングがはかどったと感じたテクニックをまとめておこうと思います。
筆者環境の前提
- ソースコードのバージョン管理は Git を使っている
- 開発 PC は Mac を使っている
- エディタは Vim を使っている
ghq + peco で読みたいリポジトリに気軽にたどり着く
読みたいソースコードのリポジトリが増えてくると、ローカル環境でのリポジトリをどのディレクトリに置くか、またいざ読もうとするときにディレクトリを辿っていくのが煩雑になってきます。
そんな時、読みたいリポジトリに気軽にたどり着くことができれば、読むハードルが下がります。
僕は peco と ghq の組み合わせを使っています。この組み合わせによって、
-
ghqでリポジトリを~/.ghq/配下に<github username>/<repo name>のディレクトリ構造で一元管理し -
pecoで~/.ghq配下のリポジトリ群をあいまい検索でフィルタリング
出来るようになり、読みたいリポジトリにたどり着くまでのハードルが下がります。
参考URL
gocloc でリポジトリの規模を知る
リポジトリのソースコードがどんな規模なのかを予め知っておくのは、コードリーディングを始める上で参考になると思います。
僕が使っているのは gocloc です。こちらはもともと存在するコードの行数をカウントする cloc(Count Lines Of Code) を golang で書き直したものです。「a little fast cloc」と紹介されてたので使っています。
例えば先程取り上げた ghq に gocloc をかけると、以下のような形でファイル数やコード行数でリポジトリの規模を知ることが出来ます。
$ gocloc ~/.ghq/github.com/motemen/ghq
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Go 17 432 61 1748
AsciiDoc 1 36 0 116
BASH 2 14 0 36
Markdown 1 12 0 27
Makefile 1 10 0 23
YAML 1 2 0 6
-------------------------------------------------------------------------------
TOTAL 23 506 61 1956
-------------------------------------------------------------------------------```
参考URL
リリースバージョンを遡ってリポジトリの規模を縮小する
いきなり大規模なリポジトリを読もうとすると、どこから読めばいいかわからなくなりがちですよね。そんな時、最初のリリースに遡ってリポジトリを規模を小さくしてから読むと、糸口が見つかるかも知れません。
Github 上のリポジトリでは リリースバージョンのコミットに tag をつけることが多いので、tag でリリースバージョンを遡ることができます。
例えば rails のリポジトリでバージョンを遡ってみましょう。2018/06/24 時点で Releases に載っている最新バージョンである v5.2.0 から確認します。
$ cd rails
$ git checkout v5.2.0
$ gocloc .
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Ruby 2313 55095 47048 234288
Markdown 75 15327 0 38364
JavaScript 47 3341 2804 13723
YAML 137 282 208 2854
CSS 20 215 140 1264
CoffeeScript 24 194 225 763
JSON 5 1 0 236
HTML 20 15 3 199
Yacc 1 4 0 46
SQL 1 6 0 43
Plain Text 6 0 0 6
-------------------------------------------------------------------------------
TOTAL 2649 74480 50428 291786
-------------------------------------------------------------------------------
約29万行。。さすがの規模ですね。次に、初期バージョン v1.0.0 を見てみると、
$ cd rails
$ git checkout v1.0.0
$ gocloc
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Ruby 567 10753 12570 50875
JavaScript 4 519 183 3271
SQL 22 209 6 1561
Ruby HTML 61 107 0 533
YAML 27 72 46 399
HTML 3 32 0 261
CSS 1 13 0 61
Bourne Shell 3 3 0 9
Plain Text 1 0 0 1
Batch 1 0 0 0
-------------------------------------------------------------------------------
TOTAL 690 11708 12805 56971
-------------------------------------------------------------------------------
約5万行程度まで規模が小さくなりました。(それでもかなりの規模ですが。。)
最新バージョンとは書き方が違っていたりするところも多いかと思いますが、リリース初期から存在する機能や、肝となるディレクトリ構造などを知ることは出来るのかなと思います。
コードを検索する
コードリーディングにはコード検索が欠かせないと思います。ここでは僕が使っているコード検索方法を書きます。
CLI でコード検索する
find / xargs / grep を使う
CLI 上で検索するときは、 find 、xargs 、grep をパイプで繋いで検索するコマンドを、.zshrc で alias 登録して使っています。./.git や ./log といったディレクトリは検索除外にしています。
alias codegrep='find . -path ./.git -prune -o -path ./log -prune -o -type f -print0 | xargs -0 grep -n -E $1'
例えばこのコマンドで rails リポジトリをREADME という文字列で検索すると、こんな感じで確認できます。
$ cd rails
$ codegrep README
./actionpack/test/controller/action_pack_assertions_test.rb:88: render file: File.expand_path("../../README.rdoc", __dir__)
./actionpack/test/controller/action_pack_assertions_test.rb:92: render file: "README.rdoc"
./actionpack/actionpack.gemspec:20: s.files = Dir["CHANGELOG.md", "README.rdoc", "MIT-LICENSE", "lib/**/*"]
...
参考URL
git grep を使う (2018/06/27 追記)
git管理のリポジトリであれば、git コマンドのサブコマンドであるgit grep コマンドが使えるようです。こちらは通常の grep と同じ操作感で、 Git を利用した高速で快適な grep が可能とのこと。
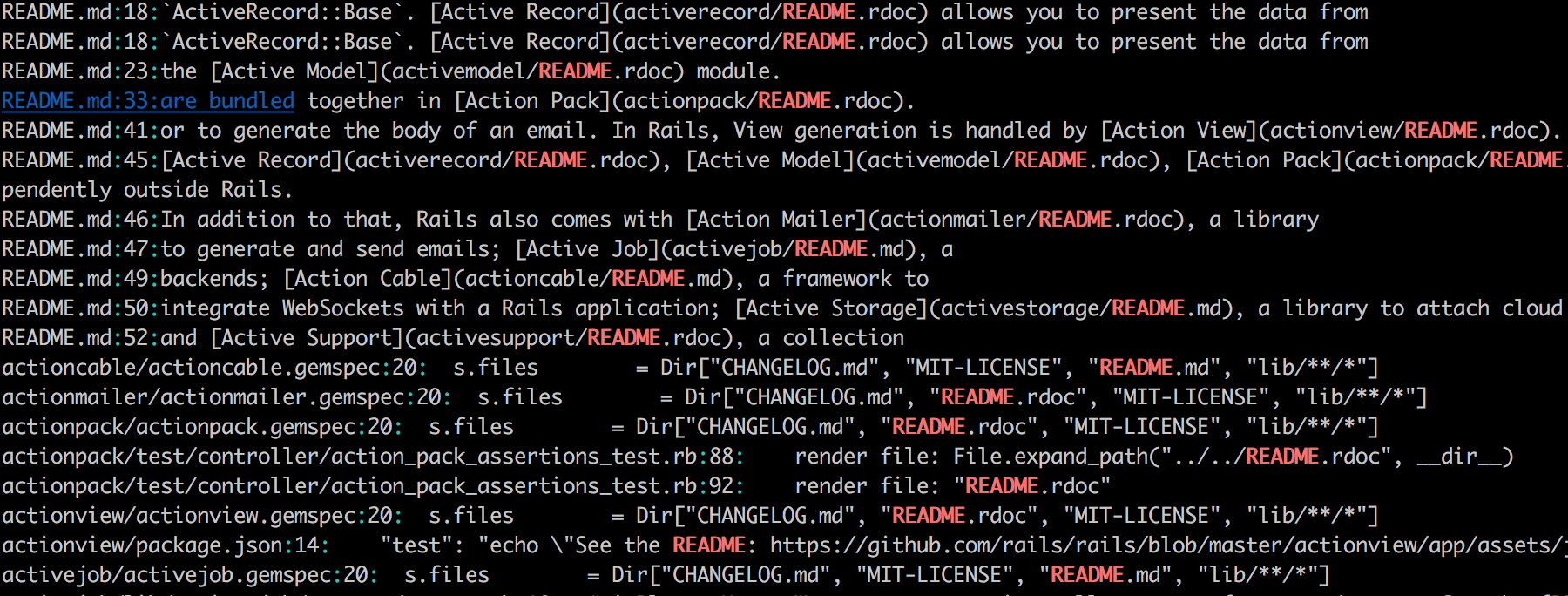
同様に、rails リポジトリをREADME という文字列で検索してみます。
git grep -n と -n オプションをつけ、行数字も表示する形で検索します。
するとこんな感じで確認できました。
less や more コマンドの要領で、u や d キーで上下移動できるのも便利です。
@potato4d さんコメントありがとうございます!
参考URL
Vim で ack.vim と the silver searcher を組み合わせてコード検索する
僕は開発で Vim を使っているのですが、ack.vimというプラグインでコード検索しています。こちらに高速でコード検索が出来るthe_silver_searcherを使えるように設定しています。
検索の仕方は:Ack hogehoge のような形で検索できます。
CLIでの検索と同様、 rails リポジトリをREADME という文字列で検索してみると、こんな感じでエディタと別のペインで検索結果が表示されます。
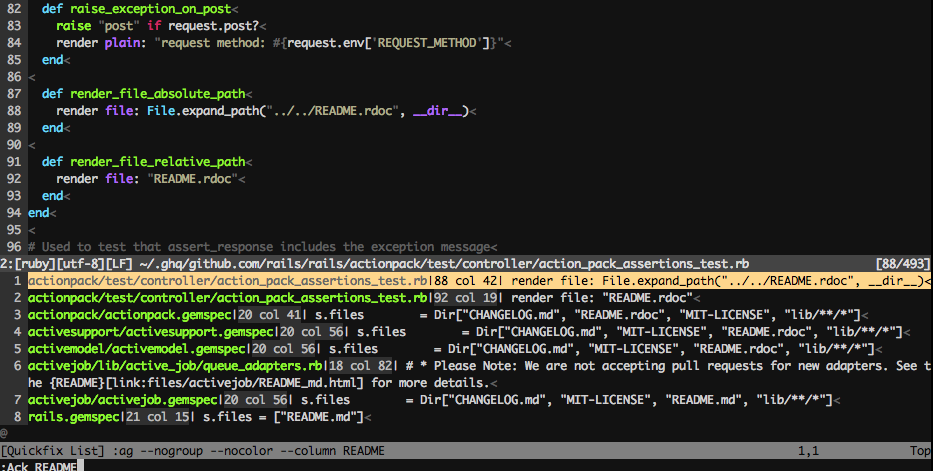
Vim から抜けること無くコード検索ができ、かつ検索結果から直接検索ヒット箇所に移動できるので便利です。僕は開発時は CLI よりもこちらを使うことが多いです。
参考URL
終わりに
コードをたくさん読むことが大事だと最近痛感しています。もっと効率よく読めるようになりたいなと思っています。他にもコードリーディングがはかどるテクニックありましたら教えてください。