概要
- DBからデータを取ってくるだけのシンプルなWebAPIを実装
- 以前に取ってきたクエリの場合はRedisからデータを取得
- どれくらい早くなったかを確認
検証スクリプト -> https://github.com/sogawa-yk/simple-webapi-with-redis
はじめに
Redisを触る機会があったので、実際どの程度の高速化が見込めるのか気になったので簡単に検証してみました。GUI操作の手順もあり少し面倒ですが、ぜひご自身の環境でも試してみてください。
検証環境
概要
OCI上にインスタンスを立てて検証します。利用した主なリソースは、
- Compute
- Autonomous Database (ATP)
- Cache with Redis
の3つです。Computeにdockerをインストールして、dockerコンテナ上にFastAPIを使ってWebAPIサーバを構築します。クライアントはこのWebAPIサーバにアクセスしてDBのデータを取得します。大まかな構成図は以下のようになります。
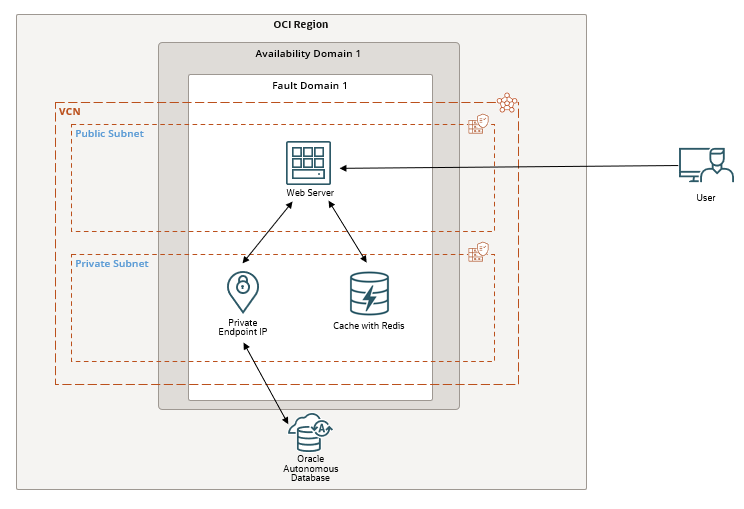
構築手順
構成図のように各リソースをプロビジョニングしてください。
ネットワークの設定
VCNは、VCNウィザードから作成します。すべてデフォルトでOKです。
WebAPIサーバにローカルのPCからアクセスするために、パブリックサブネットのイングレスルールを設定する必要があります。作成したネットワークを開き、「セキュリティ・リスト」を選択します。「Default Security List for ***」を選択します(パブリックサブネットのセキュリティ・リストを選択)。WebAPIサーバには80番ポートでアクセスするので、宛先ポート範囲を80に設定し、ソースは0.0.0.0にします。
次に、WebAPIサーバからDBにアクセスするためにプライベートサブネットのイングレスルールを設定する必要があります。「プライベート・サブネット-***のセキュリティ・リスト」を選択し、宛先ポート範囲を1521、ソースを10.0.0.0/16に設定します。
以上でネットワークの設定は終了です。
Autonomous Databaseの設定
Autonomous Databaseは、ワークロードタイプをトランザクション処理に設定する以外は、一旦デフォルトのままでプロビジョニングします。デフォルトで設定されているはずですが、「ネットワークアクセスの選択」において、「すべての場所からのセキュア・アクセス」になっているかどうかを確認してからプロビジョニングしてください(理由は後述)。
プロビジョニングが完了したら、「データベース・アクション」から、「データベース・ユーザー」を選択します。

データベース・ユーザーの画面が開いたら、画面右上のユーザーの作成を選択します。ここで、WebAPIサーバがDBにアクセスする際のユーザーを作成します。設定する項目は以下の3点です。
- ユーザ名とパスワード
- 表領域の割り当て制限をUNLIMITEDに
- Webアクセスを有効化

設定すると、上の画像のようになります。
ユーザーの作成が終わったら、「データベース・アクション」から、「SQL」を選択します。SQLの画面が開くと、ADMINとしてログインされているはずなので、一旦右上のADMINと書かれた部分をクリックし、サインアウトボタンを押してサインアウトします。その後表示されるログイン画面で、先ほど作成したユーザーでログインします。
Database Actionsの画面が表示されるので、SQLを選択します。エディタが起動するので、スクリプトファイルの中の、plsql/create_table.sqlの内容をコピペして実行します。その後、plsql/insert_data.sqlの内容をコピペして実行します。しばらく待つと、100万件のデータが作成したテーブルに挿入されます。
データが挿入できているかをselect * from products fetch first 100 rows onlyを実行して確認します。正しく挿入できていれば、以下のようになるはずです。

ここまででユーザーの設定とデータの挿入が終わったので、データベースのネットワークアクセスの設定を変更します。Autonomous Databaseの詳細のページから、「More actions」を選択し、「ネットワーク・アクセスの更新」を選択します。

表示された画面から、「プライベート・エンドポイント・アクセスのみ」を選択し、Computeインスタンスを立てたVCNにあるプライベートサブネットを選択して「更新」します。
更新が完了したら、mTLS認証をTLS認証に変更します。ネットワークの項目の中の「相互TLS(mTLS)認証」の部分にある、「編集」をクリックします。

「相互TLS(mTLS)認証が必要」のチェックを外して、「保存」をクリックします。
コンピュートの設定で利用するので、このデータベースへの接続文字列をメモしておきます。まず、「Autonomous Databaseの詳細」の、「データベース接続」を選択します。
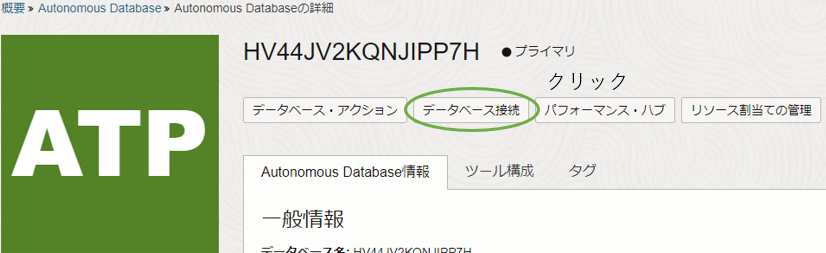
「データベース接続」の詳細画面が表示されるので、「接続文字列」の項目までスクロールし、「TLS認証」の項目を「相互TLS」から「TLS」に変更します。
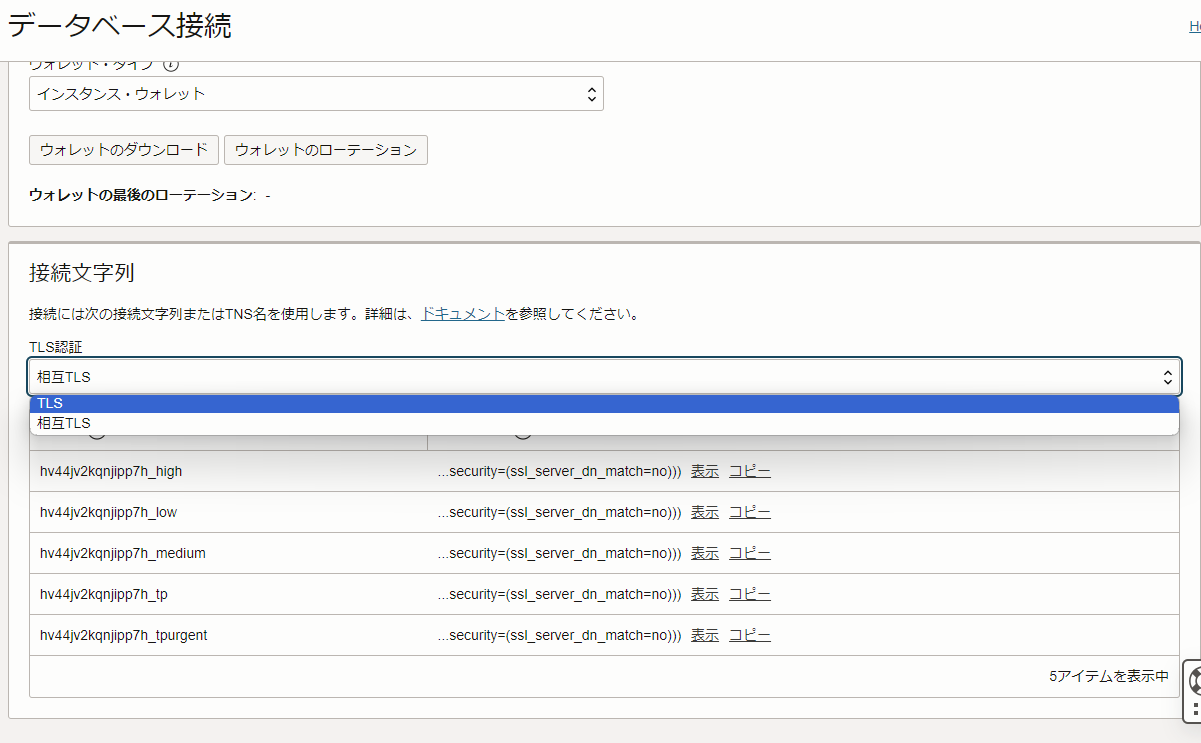
変更後、表示されるTLS名と接続文字列のうち、一番上に表示されているものをコピーしてメモしておきます。
以上でAutonomous Database側の設定は終了です。なお、最初にパブリックアクセスでプロビジョニングしたのは、コンソール画面からユーザーの作成やデータの挿入を行うためです。最初からプライベートアクセスでプロビジョニングすると、コンソールからはデータベースアクションが行えないため、それ用のインスタンスを用意する必要があります(もしくはWebAPIサーバのインスタンスからアクセスする)。
Cache with Redisの設定
Redisの設定は特に必要ありません。ネットワークはプライベートサブネットを選択し、他の項目はデフォルトのままプロビジョニングします。
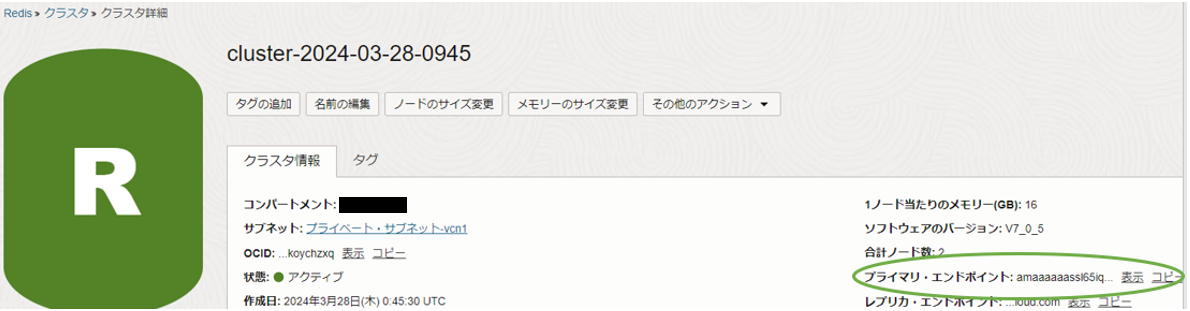
作成したRedisクラスターの詳細画面に移動し、「プライマリ・エンドポイント」の値をコピーしてメモしておきます。
Computeインスタンス(WebAPIサーバ)の設定
dockerを手動でインストールするのは面倒なので、以下のcloud-initスクリプトを指定してインスタンスをプロビジョニングします。
#cloud-config
# パッケージのアップデートとアップグレードを行います
package_update: true
package_upgrade: true
# 必要なパッケージをインストールします
packages:
- apt-transport-https
- ca-certificates
- curl
- software-properties-common
# Dockerをインストールするためのコマンドを実行します
runcmd:
# Dockerの公式GPGキーを追加します
- curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# Dockerのリポジトリを追加します
- add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# パッケージインデックスを更新し、Dockerをインストールします
- apt-get update
- apt-get install -y docker-ce docker-ce-cli containerd.io
# Dockerを起動し、システム起動時に自動で起動するように設定します
- systemctl start docker
- systemctl enable docker
インスタンスがプロビジョニングされたら、以下を実施します。
- インスタンスにSSHし、適当なディレクトリで
git clone https://github.com/sogawa-yk/simple-webapi-with-redis.gitを実行して、スクリプトをダウンロード -
cd simple-webapi-with-redisを実行してダウンロードしたディレクトリに移動 - 作成したDBの認証情報をcert.jsonという名前で作成し、適切に記述する
-
sudo docker build -t simple-webapi-with-redis:latest .を実行してdockerイメージをビルド -
sudo docker run -p 80:8000 simple-webapi-with-redis:latestを実行してコンテナを起動
3の手順について、cert.jsonは以下のように記述します。
{
"oracle_database": {
"con_str": "<メモしておいた、DBの接続文字列>",
"user": "<作成したDBユーザ名>",
"password": "<作成したDBユーザのパスワード>"
},
"redis": {
"host": "<メモしておいた、作成したRedisのプライマリ・エンドポイント>"
}
}
ローカルPCの設定
ローカルPCで行う作業は、
- スクリプトファイルの中の、
request.shをダウンロード -
request.shの中の、IPアドレスを自身のWebAPIサーバのパブリックIPに置き換える
の2つです。
パブリックIPの書き換えについて補足すると、request.shの中にある、flush_urlと、urlの値を、自身のWebAPIサーバのIPアドレスに置き換えます。
検証
ここからはクライアントPCにダウンロードした、request.shを編集して行っていきます。
10プロセス並行で、DBに作成したテーブルの全データ(100万件)をselectしたとき
キャッシュなし
request.shの、urlをurl="http://<WebAPIのIP>/all-data-nocache"に書き換え、requestCountを10、concurrentTasksを10に設定し、実行します。
私の環境では、クエリの実行に136秒かかりました。
キャッシュ有り
request.shの、urlをurl="http//<WebAPIのIP>/all-data-cache"に書き換え、requestCountを10、concurrentTasksを10に設定し、実行します。
私の環境では、クエリの実行に95秒かかりました。キャッシュを使った場合の方が40秒ほど(1.4倍ほど)早いようです。
10000プロセス並行で、DBに作成したテーブルの一部のデータ(100件)をselectしたとき
キャッシュなし
request.shの、urlをurl="http//<WebAPIのIP>/conditional-data-nocache"に書き換え、requestCountを10000、concurrentTasksを10000に設定し、実行します。
私の環境では、クエリの実行に222秒かかりました。
キャッシュ有り
request.shの、urlをurl="http//<WebAPIのIP>/conditional-data-cache"に書き換え、requestCountを10000、concurrentTasksを10000に設定し、実行します。
私の環境では、クエリの実行に62秒かかりました。キャッシュを使った場合の方が160秒ほど(3.5倍ほど)早いようです。
10プロセス並行で、DBに作成したテーブルの全データをソートした結果をselectしたとき
PRODUCTSテーブルの、PRICE列とSTOCK_QUANTITY列の値で降順にソートした結果でかかる時間を比較します。ソートは比較的重い処理なので、キャッシュの効果が期待できそうです。
キャッシュなし
request.shの、urlをurl="http//<WebAPIのIP>/sorted-all-data-nocache"に書き換え、requestCountを10、concurrentTasksを10に設定し、実行します。
私の環境では、クエリの実行に165秒かかりました。
キャッシュ有り
request.shの、urlをurl="http//<WebAPIのIP>/sorted-all-data-cache"に書き換え、requestCountを10、concurrentTasksを10に設定し、実行します。
私の環境では、クエリの実行に104秒かかりました。キャッシュを使った場合の方が60秒ほど(1.6倍ほど)早いようです。
1プロセスずつ、10回、DBに作成したテーブルの全データをソートした結果をselectしたとき
キャッシュなし
request.shの、urlをurl="http//<WebAPIのIP>/sorted-all-data-nocache"に書き換え、requestCountを10、concurrentTasksを1に設定し、実行します。
私の環境では、クエリの実行に131秒かかりました。
キャッシュ有り
request.shの、urlをurl="http//<WebAPIのIP>/sorted-all-data-cache"に書き換え、requestCountを10、concurrentTasksを1に設定し、実行します。
私の環境では、クエリの実行に97秒かかりました。キャッシュを使った場合の方が30秒ほど(1.3倍ほど)早いようです。
1プロセスずつ、10回、DBに作成したテーブルの100件のデータをソートした結果をselectしたとき
キャッシュなし
request.shの、urlをurl="http//<WebAPIのIP>/sorted-100-data-nocache"に書き換え、requestCountを10、concurrentTasksを1に設定し、実行します。
私の環境では、クエリの実行に2秒かかりました。
キャッシュ有り
request.shの、urlをurl="http//<WebAPIのIP>/sorted-100-data-cache"に書き換え、requestCountを10、concurrentTasksを1に設定し、実行します。
私の環境では、クエリの実行に1秒かかりました。
キャッシュを使った場合の方が1秒早いですが、使わない場合と大差はありませんでした。これは、ひとつ前の実験で全データをソートした結果をselectしているため、DBのバッファキャッシュにデータが残っていたためだと考えられます。
まとめ
検証結果をテーブルにまとめると以下のようになりました。
| 検証パターン | キャッシュなし | キャッシュ有り |
|---|---|---|
| 10プロセス並行で、DBに作成したテーブルの全データ(100万件)をselectしたとき | 136秒 | 95秒 |
| 10000プロセス並行で、DBに作成したテーブルの一部のデータ(100件)をselectしたとき | 222秒 | 62秒 |
| 10プロセス並行で、DBに作成したテーブルの全データをソートした結果をselectしたとき | 165秒 | 104秒 |
| 1プロセスずつ、10回、DBに作成したテーブルの全データをソートした結果をselectしたとき | 131秒 | 97秒 |
| 1プロセスずつ、10回、DBに作成したテーブルの100件のデータをソートした結果をselectしたとき | 2秒 | 1秒 |
いずれもキャッシュを用いたほうが高速であることが分かりました。selectするデータが少量で、たくさんのプロセス(ユーザー)からのアクセスがある場合、最もキャッシュの効果が発揮されるようです。