はじめに
ディープラーニングの勉強を始めて1ヶ月。
基礎的なものは理解できた気がしてきたので、何かできないかと考えてみました。
そしてふと、この競艇の順位予想が思いつきました。
順位予想ができるという確信はありませんでしたが、ボートレースのデータのオープンソースが公開されていることがわかり、これはやってみるしかないと思いました。
参考にしたデータ元と特徴量
↓データ元のサイトは下記リンクから飛ぶことができます。↓
選手のデータから勝率まで細かく載っているので学習させるにはちょうどいい情報量だと思います。
今回学習させるデータの種類は以下の通りです。
- 艇番
- 年齢
- 体重
- 級別
- 全国勝率
- 全国2率
- 当地勝率
- 当地2率
- モーターナンバー
- モーター勝率
- ボートナンバー
- ボート勝率
とりあえずこの情報量で学習させていきます。
選手番号を使うことも考えましたが、それぞれを別カテゴリとしてしまうと、無駄な情報量が多くなってしまうので省くことにします。
年齢、体重などが成績に関わるか、と言われると競艇の知識がないのでそれはわかりませんが、一応特徴量として入れることにしました。
Keras
Kerasを用いたディープニューラルネットワークをつくりたいと思います。
バックエンドとしてTensorflowを使用しています。
KerasはGoogleの社員が開発設計したもので、Google開発のTensorflowとの互換性がいいのでとても使いやすいです。
さらにKerasは高校の数学ができればある程度開発を行うことができる(と設計者が言っていた)のでとっかかりやすいとおもいました。
参考文献は下記リンクに貼っておきます。
ソースコード
ライブラリのインポート
import pandas as pd
from sklearn.model_selection import train_test_split
import keras
from keras import models, layers, regularizers
from google.colab import files
-
DataFrameを扱うpandas
-
訓練データとテストデータに分割するtrain_test_split
-
ネットワークを構築するときに使うmodels, layers
-
正規化するためのregularizers
-
自分のPCからファイルをインポートできるfiles
データのインポート
uploaded = files.upload()
files.upload()で自分のPC内にあるファイルをインストールすることができます。
DataFrameの読み込み/要素の削除/欠損値を0で埋める
df = pd.read_csv('program_data.csv').drop(["Name", "Live", "Number"], axis=1).fillna(0)
df.head(3)
pd.read_拡張子()
指定したファイルをDataFrameとして受け取ることができます。
df.drop()
指定した行(axis=0)または列(axis=1)の要素を削除することができます。
(axisの順番が逆でした。間違い訂正済み)
df.fillna()
欠損値を任意の値で埋めることができます。
例えば今回の場合では、df.fillna(0)としてあげると欠損値(NaN)を0に変換して埋めてあげることができます。
しかし、欠損値は0で埋めれば良い。という話ではありません。
今回の場合は順位が1位の場合は1、それ意外は欠損値(NaN)というデータを扱っています。
1位を予測することが今回の目標なので、1位以外のテストラベルの値は0であった方が学習がしやすいと思い、0で埋めることにしました。
もし、学習させたい要素に欠損値があった場合、学習に支障を来さないために中央値であったり、平均値で補ってあげると良いと思います。
欠損値の算出
df.isnull().sum()
df.isnull()
各要素に欠損値(NaN)があるかを調べます。
そしてsum()によって加算することで、各要素にどれだけの欠損値(NaN)があるかがわかります。
OneHotEncodingで名義特徴量を変換する
df_dummies = pd.get_dummies(df["Rank"])
df_dummies.astype("float32")
pandasのget_dummies()
OneHotEncodingを簡単に行うことができます。
Rankは名義特徴量であるため、OneHotEncodingで情報を有益に使うようにする必要があります。
df.astype('float32')
DataFrameの変数型を変更することができます。
ディープラーニングにおいて、変数型をそろえるのは重要な部分となってきます。
不必要な要素の削除
df = df.drop('Rank', axis=1)
df.astype("float32")
OneHotEncodingしたので、Rankカラム(列)自体は必要なくなったので、削除します。
DataFrameの結合
df = pd.merge(df, df_dummies, how="left", left_index=True, right_index=True)
pd.merge(df1, df2)
DataFrameを結合することができます。
その他引数の設定によって細かく結合方法を指定することができます。
特徴行列と目的変数
X = df.iloc[:, 1:].values
y = df.iloc[:, 0].values
df.iloc(行, 列)
DataFrame.ilocからアクセスすれば、行と列の数字(インデックス番号)からDataFrameを取り出せます。
X:年齢、勝率などの学習させるためのデータを含む特徴行列
y;教師あり学習として使う目的変数
訓練・検証データとテストデータ
X_train, y_train, X_test, y_test = train_test_split(
X, y, test_size=0.2, random_state=0)
train_test_split()
データをトレーニングデータとテストデータに分割します。
test_size=0.2とすると、全体のデータの20%をテストデータとして使用する。という意味になります。
特徴行列の正規化
mean = X_train.mean(axis=0)
std = X_train.std(axis=0)
X_train -= mean
X_train /= std
y_train -= mean
y_train /= std
特徴行列が各要素ごとに別々の特徴量を持っている時、正規化する必要があります。
正規化の方法は以下の手順です。
- 特徴行列の平均値(mean)、標準偏差(std)を求めます。
- 特徴行列から平均値を引きます。
- その後、標準偏差で割ることで正規化が完了します。
これによって、特徴量の中心が0となり、標準偏差が1になります。
X_train(訓練データ)とy_train(テストデータ)の両方を正規化しておきます。
ニューラルネットワークの構築
model = models.Sequential()
model.add(layers.Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.001), input_shape=(X_train.shape[1], )))
model.add(layers.Dropout(0.49))
model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.49))
model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.49))
model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001)))
model.add(layers.Dropout(0.49))
model.add(layers.Dense(1, activation="sigmoid"))
ここからニューラルネットワークを構築していきます。
層を追加するときには、Denseを使用します。
活性化関数
最終層以外の各層に活性化関数(activation)としてReLU関数を使用しています。
最終層には出力結果を0から1で出力するシグモイド関数を使用しています。
正則化
kernel_regularizer = keras.regularizers.l2(0.001)**
過学習を防ぐためにL2正則化を行っています。
layers.Dropout()
こちらも過学習を防ぐための方法です。
ランダムに層の出力を0にして隠すことによって学習の偏りを防ぎ、より有益な学習を行うことができるようになります。
これでニューラルネットワークの層は完成しました!
コンパイルメソッド
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
続いてコンパイルメソッドに入ります。
optimizer:与えられたデータと損失関数に基づいてネットワークが自身を更新するメカニズム
loss:損失関数:訓練データでのネットワークの性能をどのように評価するのか、そしてネットワークを正しい方向にどのように向わせるのかを決める方法
metrics:モデルの評価をする評価関数
扱う問題によってコンパイルメソッドに何を選択するか、ということも変わってきます。
オプティマイザのrmspropに関してはどの問題でも基本的にちゃんと動いてくれる有能な役割をもつので
、最初にとりあえずこれを使ってみても良いかもしれません。
学習(訓練)
EPOCHS=1000
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(X_train,
X_test,
epochs=EPOCHS,
batch_size=512,
validation_split=0.2,
callbacks=[early_stop])
これで準備が完了したので、いよいよ訓練(学習)を開始させていきたいと思います。
訓練をするときには、**fit()**を使用します。
X_train:特徴行列
y_train:目的変数
epochs:訓練(のループ)を何回行うか指定することができます。
batch_size:任意の数のミニバッチを作成し。学習させる。
validation_split:検証用データを作成することができる。(今回の場合は0.2なので20%を検証データとして使う。)
callbacks:色々な種類があり、今回は過学習が起こる前に学習を強制終了させるEarlyStoppingを使用しています。
callbacks.EarlyStopping(monitor='', patience=10)
過学習を起こさせないために最適なエポックの数で強制終了させる役割を持ちます。
-
monitor:監視する値
-
patience:ここで指定したエポック数の間(監視する値に)改善がないと、訓練が停止します。
詳細はKeras Documentation callbacksを参考にしてください。
モデルの評価
score = model.evaluate(y_train, y_test)
print("loss : {}".format(score[0]))
print("Test score : {}".format(score[1]))
モデルの評価を行います。
score = model.evaluate(y_train, y_test)
score[0]:損失関数の値が入ります。
score[1]:テストの正解率が入ります
 正解率を約86%まで伸ばすことができました。
正解率を約86%まで伸ばすことができました。
Historyオブジェクト
history_dict = history.history
history_dict.keys()
model.fit()呼び出しがHistoryオブジェクトを返すことに注目してください。
このオブジェクトには、historyというメンバーがあります。
このメンバーは、訓練中に起きたすべてのことに関するデータを含んでいるディクショナリです。
出力

このディクショナリには、訓練中および検証中に監視される指標ごとに1つ、合計4つのエントリが含まれています。
損失値の図示
import matplotlib.pyplot as plt
#ドットは訓練データを表しており、折れ線は検証データを表しています
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
#”bo”は”blue dot”(青のドット)を意味する
plt.plot(epochs, loss_values, 'bo', label = 'Training loss')
#”b”は"solid blue line"(青の実線)を意味する
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
訓練データの損失値と検証データの損失値をプロットします。
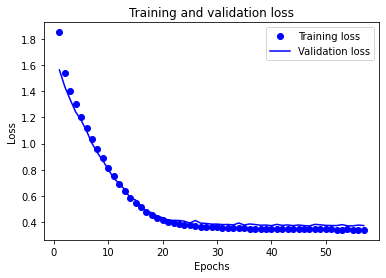
図より、過学習も防ぐことができており、損失値もエポックごとに減少していることから良いモデルになっていると思います。
正解率の図示
# 図を消去
# ドットは訓練データでの結果、折れ線は検証データでの結果
plt.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
次に、一旦図を消去し、訓練データと検証データの正解率をプロットしていきます。
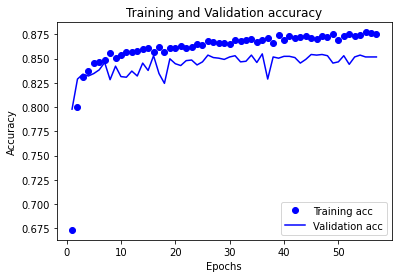
少し図に偏りがあったりしますが、基本的には80~85%の正解率を出すことができています。
まとめ
ディープラーニングを用いて正解率を約86%まで伸ばすことができました。
転覆などの事故でバイアスがかかるので、絶対的な正解率にするのは難しいようです。
余裕があれば、次回から2連単、3連単を予測するプログラムを作りたいと思います。
ソースコードの間違い、ご指摘などございましたらコメント欄にお願いします。