みなさん、大分麦焼酎二階堂🍶のCMを見たことはありますか?
私がみた中でCMで印象に残ってるのはこちらのCMで「どうか、タイムマシンが発明されませんように。」というフレーズが強烈に印象に残っています。
公式のCMライブラリーを見てみると、いい感じにフレーズが区切られていて、これランダムに組み合わせても意味通じるんじゃね?と思い、二階堂メーカーというものを作ってみました。
下記にデプロイしていますので、アクセスしてみてください。(リロードするたびに内容が変わります。)
今回は二階堂メーカー実装に関するポイントを要所で紹介します。
仕様パート1
まずランダムの前提として、各篇の.library_textを1行区切りを1フレーズとしてランダムに組み合わせを行います。

ランダムと言っても単純にすべてのフレーズをごちゃ混ぜにして抽選するのではなく、各篇の上から1行ずつ組み合わせてランダムにすることにしました。
というのも仮に各偏の1行目が連続してしまうことや、終わりの方に冒頭1行目が出てくると、全体としてクオリティが低下しまうのでは?と思ったからです。
下図のような感じで組み合わせを行います。

細かい仕様は後に解説しますが、とりあえずこれだけ理解しておけば、上記サイトで遊べるかなと思います。
データ準備(Python)
公式サイトよりデータを取得するために、BeautifulSoupを使って各ページのコンテンツを取得しました。(いまだにBeautifulをタイポするのをなんとかしたい。)
インデント問題
.library_text内のテキストを取ってくる時に困ったのがインデントです。
下記のような感じでテキスト情報だけ取得した際に、ソース上のインデントもテキストとして見なされてしまいました。
data = requests.get("https://nikaido-shuzo.co.jp/library/cm2011_2.html")
html = BeautifulSoup(data.content, "html.parser")
library_text = html.select_one(".library_text").text
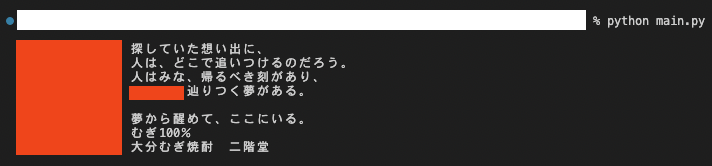
赤いところがインデント
インデントを除去しようと思って、ググって出てきたtextwrap.dedentを利用してみたところ、1行目のインデントしか削ってくれなかったです。参考記事いくつか見た中でヒアドキュメントの例しかなかったので、用途が違ったかも。
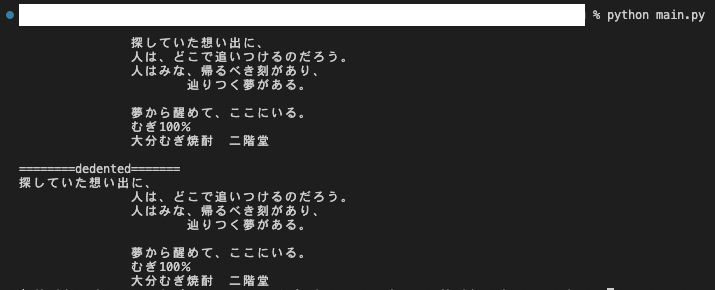
仕方ないので今回は空白にあたる文字は全て除去することにしました。
中には文中に空白があるものもありましたが、めんどくさいので一旦は気にしない方向で。
二階堂メーカーでは、.library_textの情報さえあればコンテンツとして完結するのですが、一応、コンテンツとして取れるものは取っておこうと思い、最終的には下記の様な構造になりました。
[
{
"id": 41,
"url": "https://nikaido-shuzo.co.jp/library/cm2022.html",
"title": "2022年「水のため息」篇",
"library_text": "どこにでもある風景。\nここにしかない風景。\n静けさは語りかけ、\n流れは\nささやきに変わる。\nむぎ100%\n大分むぎ焼酎二階堂\n",
"split_library_text": [
"どこにでもある風景。",
"ここにしかない風景。",
"静けさは語りかけ、",
"流れは",
"ささやきに変わる。",
"むぎ100%",
"大分むぎ焼酎二階堂"
],
"line_count": 7,
"locations": [
{
"img": "/images/library/2022/1.jpg",
"name": "福岡県朝倉市千手\n小石原川"
},
{
"img": "/images/library/2022/2.jpg",
"name": "福岡県朝倉市秋月\n野鳥川"
},
...省略
],
"movie": "https://www.youtube.com/watch?v=IU2lermMR4c"
},
...省略
]
各項目で補足
- id: 今後CMが増えたときにずれないように、新しい篇から値を大きく。
- library_text: 改行で区切る前の元テキスト。
- split_library_text: 今回の主役。
library_textを改行区切りで配列化したもの。 - line_count:
split_library_text.lengthで取得可能だが、処理として先に出力できるものはしておく。 - locations.name: 空の
p.nameがあるので、textがなければlocations.imgのみ。 - movie: 動画はない場合もある。
watch?v={id}となっている部分は、実際にはembed/{id}。
仕様パート2
line_countを入れた理由としては、生成するフレーズの行数を各篇のline_count範囲内でランダムに出力したかったためです。
サイトでリロードするたびに行数が変わるのは、単純にランダムな行数ではなく、この様な仕様となっています。
ここまでの仕様
- 各篇の
line_count範囲内で生成される行数を確定させる - 1.の行数内で各篇の上から1行ずつ組み合わせでランダムに生成
データ整理(👀✋)
データができた後、一通り内容を確認すると下記のことに気づきました。
-
line_countが4〜13・15行ある - たまに表記のゆれがある。
- 「麦100%」「むぎ100%」「むぎ100%」「むぎ100%。」etc...
- 「大分むぎ焼酎二階堂」「大分むぎ焼酎、二階堂」
- 末尾2行がセットになってる場合が大半
- 中でも「むぎ100%」が多い
- たまにセットが1行になってることがある。

1.について
15行のパターンが1つしかないことから、「1. 各篇のline_count範囲内で生成される行数を確定させる」で15行生成をするパターン引いた場合、末尾を必ず15行のものを使わないといけない(14行の篇もないので、実際は14・15行を利用する)ことになるので、2行結合して13行まで削りました。
2.について
味かなと思い、ノータッチの方向で。
3.について
今回は以下の様な理由から、末尾2行をセットとする仕様を採用しました。
なので、まずは各篇のsplit_library_textの末尾2行分を取ってきます。
- 公式に敬意を払い、公式の素敵なフレーズを崩したくない。
- セットになっていない場合でも、1行目からフレーズを重ねていった場合、必ず末尾が句点で終わることができる。
ちなみに3-2については手で2行に分けました。
仕様パート3(確定)
上記のため、最終的な仕様は下記のようになりました。
- 各篇の
line_count範囲内で生成される行数を確定させる(4〜13行) - どれかの篇から末尾2行取得する
- 1.の行数から
-2した行数内で各篇の上から1行ずつ組み合わせでランダムに生成
フロントエンド・API(Next.js)
今回、APIを作る前提だったのでNext.jsを採用しました。
エンドポイント
GET https://nikaido-maker.vercel.app/api/random
レスポンス例
{
"result": [
"どこにでもある風景。",
"会いたい人と会えない人。",
"ふるさとは、私の中に流れています。",
"麦100%。",
"大分むぎ焼酎、二階堂"
]
}
※Vercelの稼働状況を見て、APIを公開停止する可能性があります。
※フロントエンド側はAPIを叩いているわけではなく、APIと同じ関数を呼んでるだけなので、いくら更新してもAPI制限については心配ありません。
Mantine
CSS書きたくない!という思いから、大した画面を作るわけではないのにMantineを導入しました。結局ほとんどが自分でスタイル書かないといけなくて、Tailwind CSSにしとけばよかったなと後悔。
TODO: Tailwind CSSへ変更
まとめ
試していただくとわかると思うんですが、思ったより素敵なフレーズが誕生せず期待した結果が得られませんでした😨
ただ、こちらの7行目詩人 長田弘はこう書きました。が出てきたときに、ぐっと引き締まる感じがしました。
Pythonでディープラーニングを用いて解析すれば、もっと素敵な感じにできるんだろうなぁと思いながらも、専門外なので他の方へ託します。
最後に
GoQSystemでは一緒に働いてくれる仲間を募集中です!
ご興味がある方は以下リンクよりご確認ください。