はじめに
OpenVoiceとは?
OpenVoiceは、ボイスクローンができるAIモデルです。OpenVoiceは、以下の特徴を持っています。
- 正確なトーンカラーのクローニング
- 柔軟なボイススタイルコントロール
- ゼロショット学習
OpenVoice V2
OpenVoice V2は、2024年4月にリリースされました。V1と比べて、以下の特徴があります。
- より良いオーディオ品質
- ネイティブの多言語サポート
V2では、以下の言語がサポートされています。
- 英語
- 日本語
- フランス語
- スペイン語
- 中国語
- 韓国語
複数のイントネーション
英語はイントネーション別として、イギリス・アメリカ・インド・オーストラリアの4つのアクセントがサポートされています。
まずは試してみる
DOKにログインする
さくらのクラウドにログインしてください
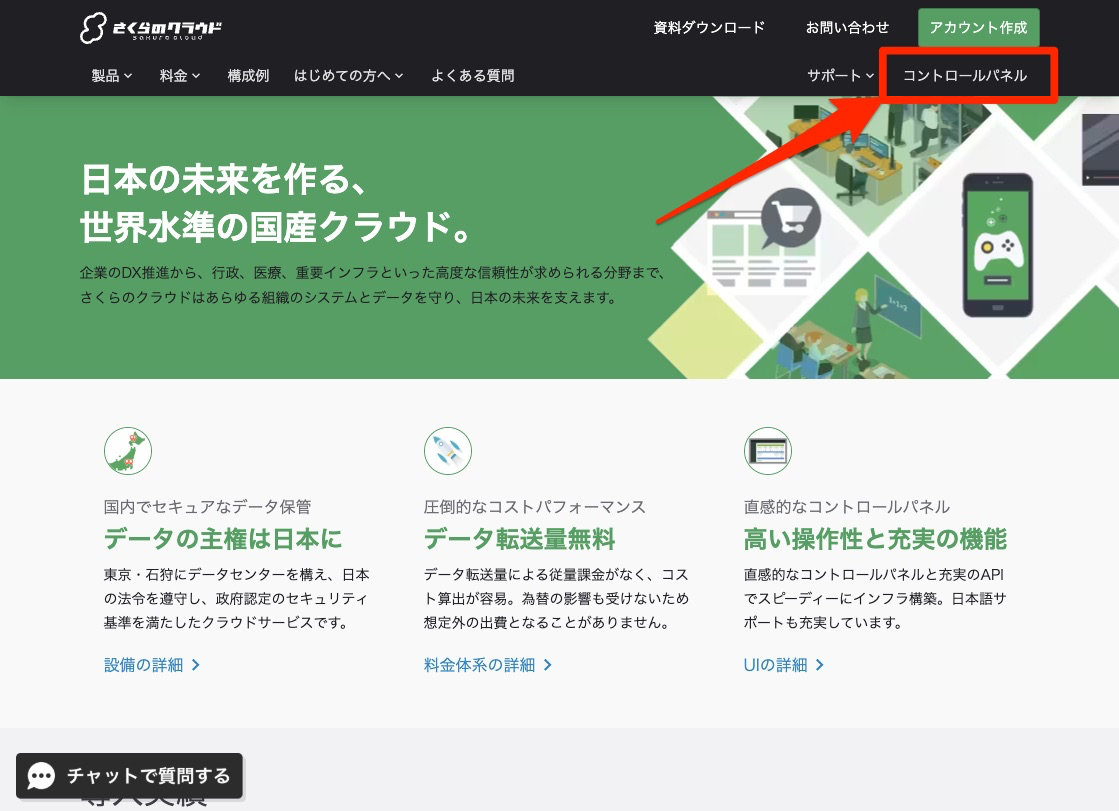
会員IDとパスワードを入力する
IDとパスワードは配布されているものをご利用ください

DOKを選択する
デザインがレスポンシブなので、DOKのアイコンが下にあるかも
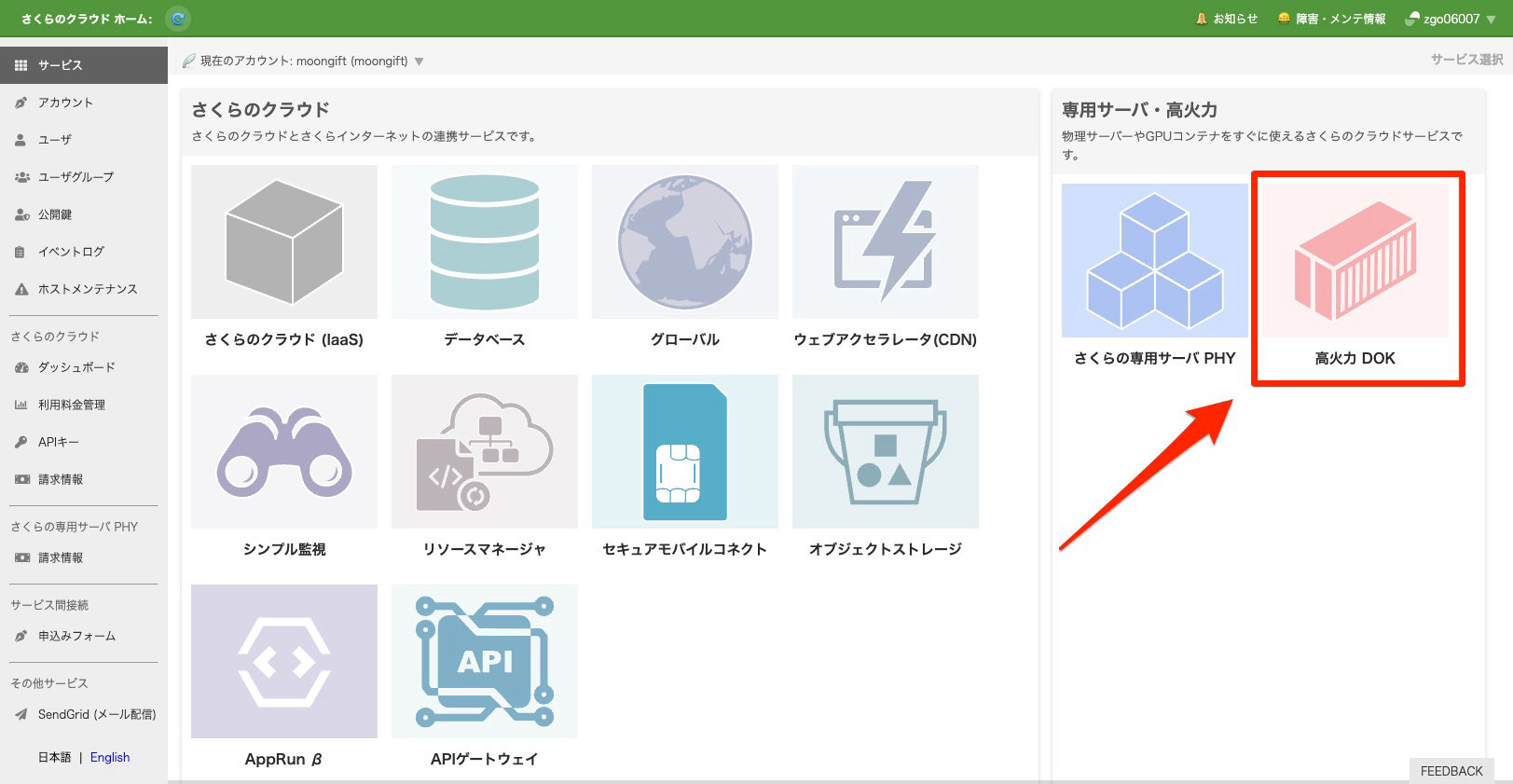
タスクを選ぶ

タスクの新規作成を選ぶ

以下の通りに入力
環境変数は + 追加 ボタンを押して追加してください。
- イメージ
dok-handson.sakuracr.jp/openvoice - 環境変数
- TEXT
Hello, everyone. We're holding the DOK hands-on, today. - LANG
EN
- TEXT
入力イメージ

入力が終わったら、 作成 ボタンを押してください
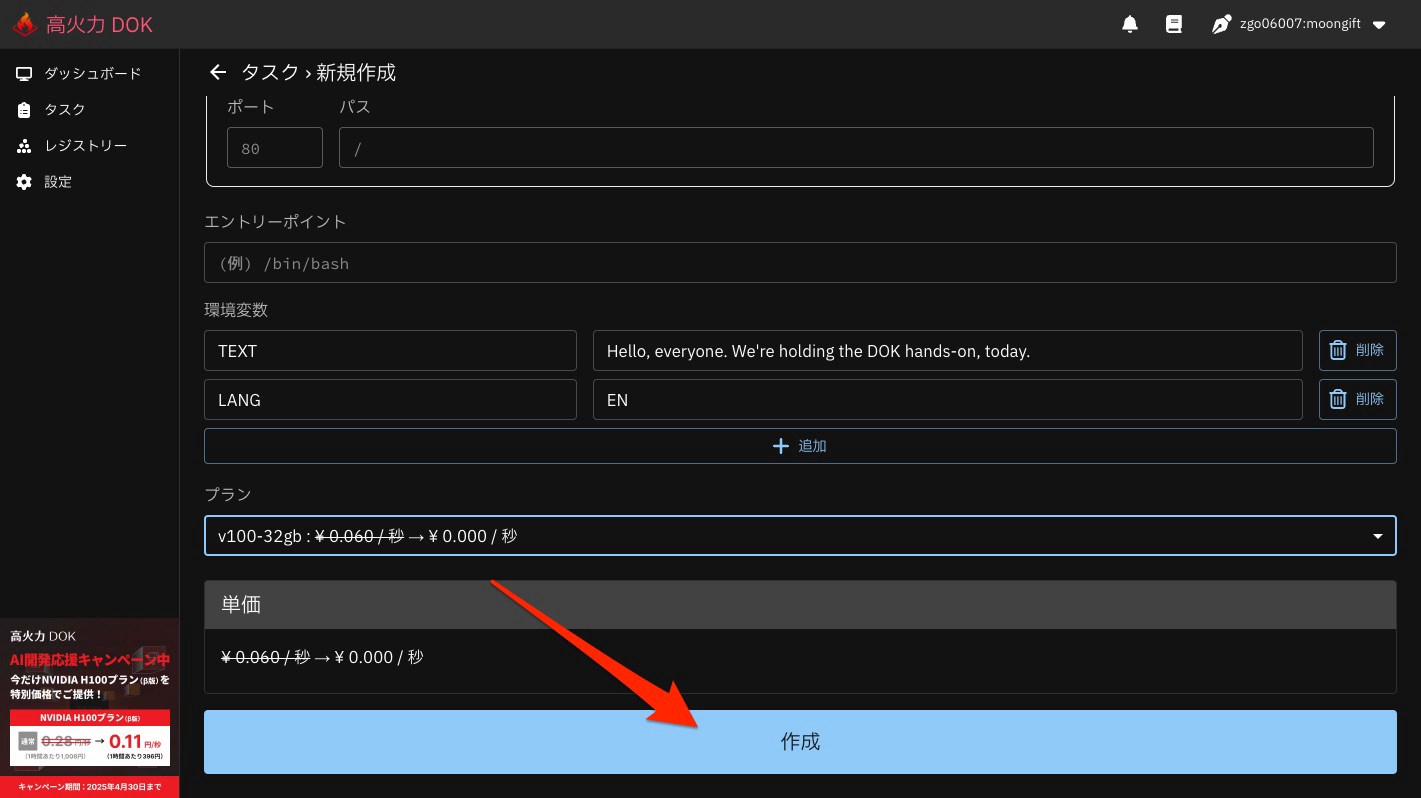
確認ダイアログが出るので、 作成 ボタンを押してください
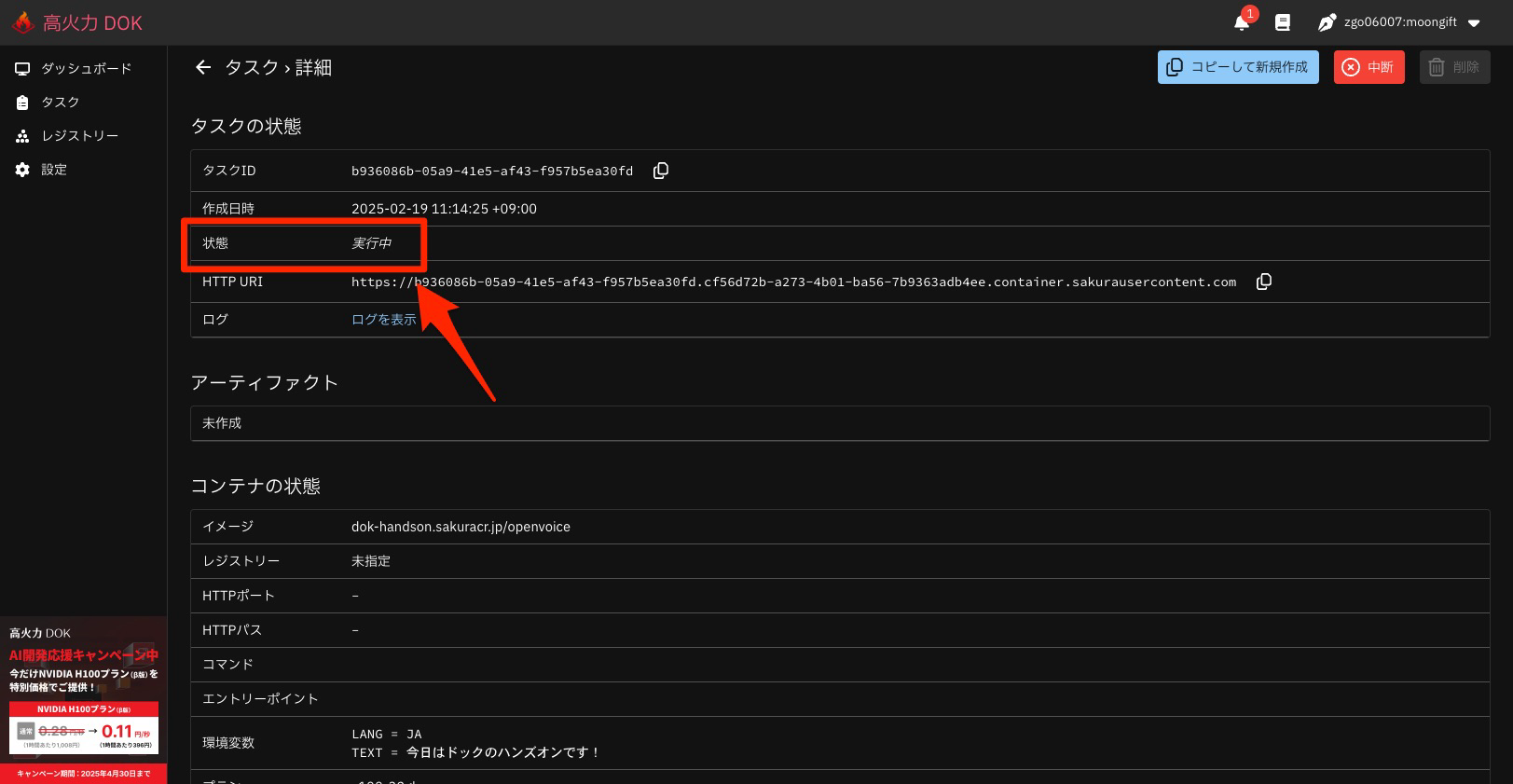
実行中の画面です。 状態 のところの文字で状況が判断できます。
DOKのタスクで行っていること
- Dockerイメージの取得
- コンテナの実行
- コンテナの破棄
メモ
- Dockerイメージの取得には、それなりに時間がかかります(10GB超えもざらなので…)
- コンテナ実行時にモデルを取得するものが多く、そこも時間がかかります
- HTTP URIは、タスク実行中にアクセスできるHTTPサーバーです
スクリプト側でリクエストを受け取って処理できます
実行完了後
実行完了すると、 アーティファクト の項目に ダウンロード が表示されます。

音声の確認
ダウンロードしたtar.gzファイルを解凍すると、MP3ファイルが確認できます。再生して、 Hello, everyone. We're holding the DOK hands-on, today. を話しているのを確認してください。
英語の場合、各イントネーションでのMP3ファイルが作成されます。

リファレンス音声を作る
自分の声をクローンする場合には、まずリファレンス(参考)になる音声データが必要です。
スマートフォンのボイスレコーダーで録音したり、Online Voice Recorder - マイクからの音声録音が利用できます。
音声を録音する
ある程度長い方が良いので、青空文庫のアクセスランキングから気に入った作品を読んでみてください(3〜4分程度)。
例: グリム兄弟 Bruder Grimm 楠山正雄訳 赤ずきんちゃん ROTKAPPCHEN
音声ファイルをアップロードする
音声ファイルを、HTTPアクセスできる場所に保存します
以下は、さくらのクラウドのオブジェクトストレージを利用する例ですが、ご自身で別なクラウドストレージを使ってもらっても大丈夫です
オブジェクトストレージを選択する
さくらのクラウドのホームに戻ります
オブジェクトストレージを選択

サイトを選択

バケットを選択
さらに バケットの追加 ボタンを押してください
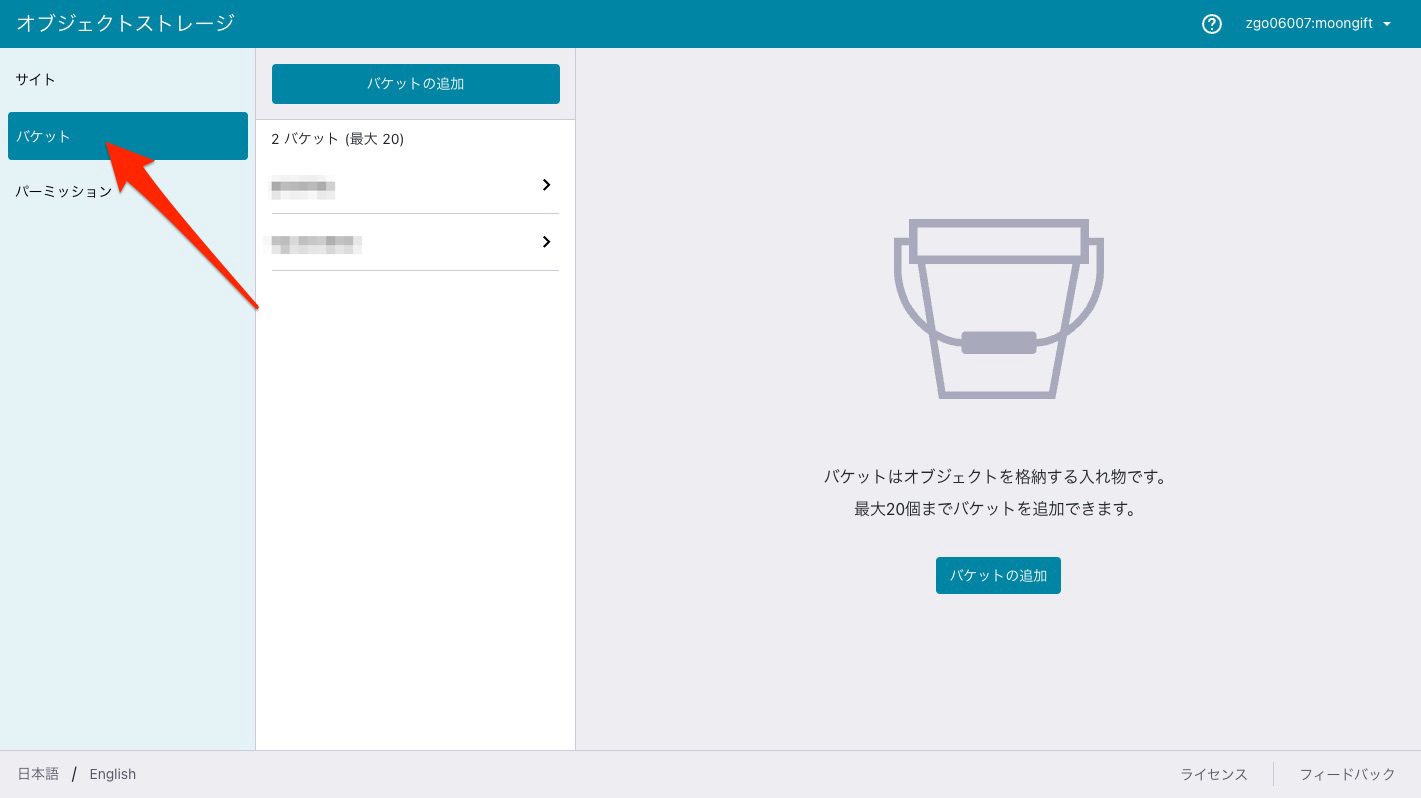
バケットの追加
分かりやすいものを設定してください

アップロード
作成したバケットを選んで、 アップロード ボタンを押します

アップロードする
public-read を付けておいてください

アップロードしたら、以下のURLでMP3ファイルにアクセスできるか確認してください。このURLをDOKの環境変数 REFERENCE として指定します。
https://s3.isk01.sakurastorage.jp/(バケット名)/(ファイル名).mp3
タスクのコピー
先ほど実行完了したタスクを開きます。
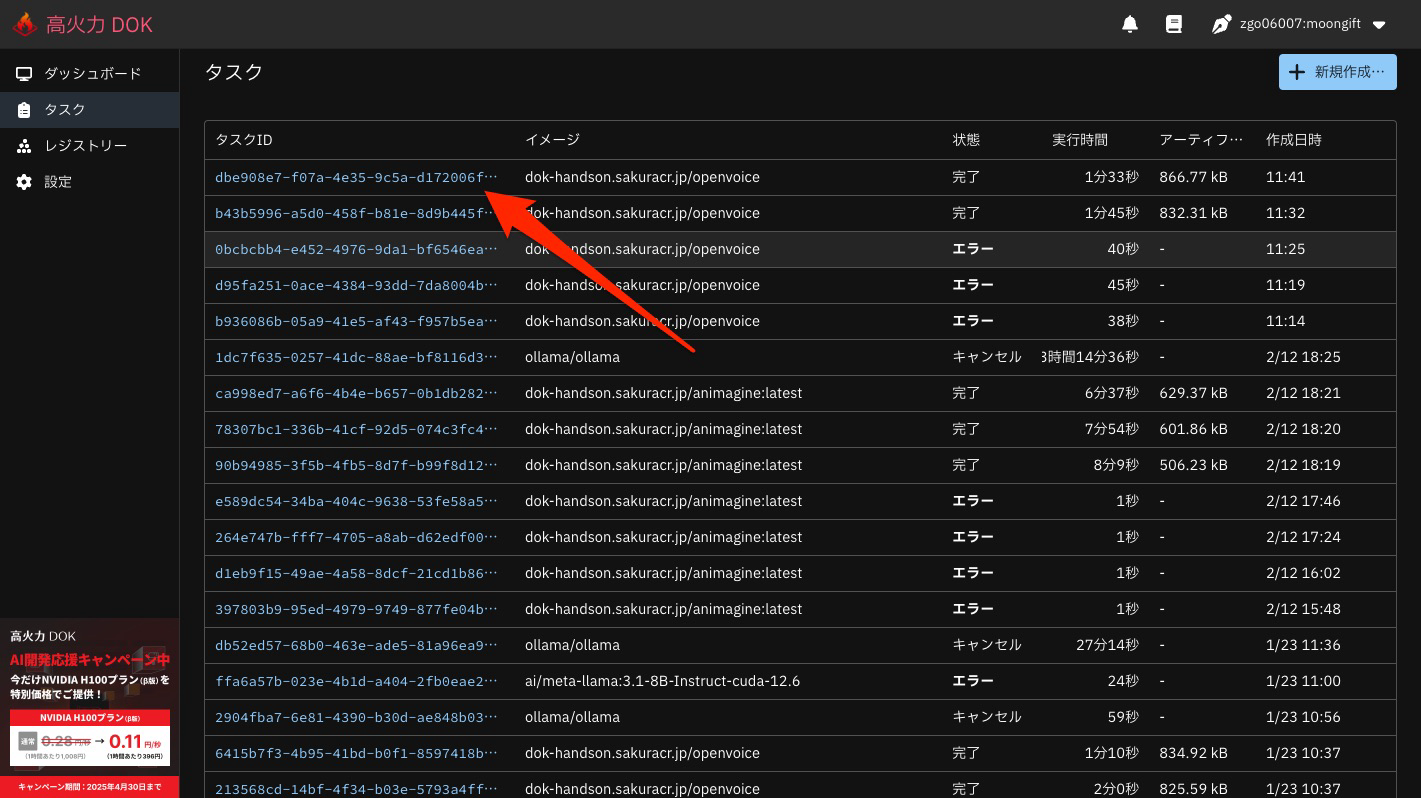
コピーする
コピーして新規作成 を押します

リファレンスを追加する
環境変数に REFERENCE を追加して、先ほどアップロードしたMP3ファイルのURLを設定してください

タスクを再実行する
タスクを再度実行して、自分の声のクローニングが成功しているか確認してください
一旦終了
ハンズオンの内容は以上になります。DOKの面白さとして「タスクをたくさん作成できる」点があります。ぜひタスクをコピーして、さまざまな条件で実行してください。
ここからの流れ
ここからはDockerイメージの作成を行います。作成には1時間以上かかると思われますので、ハンズオン実施中には終わらないはずです。
Dockerイメージの作り方
ここからはテクニカルな内容になります
必要なもの
- ターミナル
オプショナル
- Docker
- 手元にDocker環境がある方は、ローカルでも構築可能です
- Docker環境がない場合は、さくらのクラウドを利用できます
さくらのクラウドでサーバを立てる
さくらのクラウドのホームに戻り、 さくらのクラウド(IaaS) を選択します
追加ボタンを押す
サーバ の 追加 ボタンを押します

情報を入力する
サーバのスペックを以下のように設定してください
- 仮想コア
4 - メモリ
4GB - 新規ディスクを作成
- アーカイブ
Ubuntu Server 24.04.1 LTS 64bit - ディスクサイズ
100GB - インターネットに接続
- 管理者のパスワード
十分分かりづらいもの - ホスト名
分かりやすいもの(dokなど) - 公開鍵
必要であれば - サーバーの名前
分かりやすいもの(dokなど)
サーバを追加
作成 ボタンを押します
確認する
確認ダイアログが出るので、 作成 ボタンを押してください
サーバを確認
少し待つと、サーバが立ち上がります

サーバに接続する
サーバへは ssh で接続してください。ユーザー名は ubuntu です。
サーバ内での作業
ここからはサーバ内(またはローカル)での作業になります
Dockerのインストール
Dockerをインストールします
$ sudo apt-get update -y
$ curl -fsSL https://get.docker.com -o get-docker.sh
$ sudo sh ./get-docker.sh
Dockerを試す
今のコマンドが通れば、Dockerはインストールされています
$ sudo docker run hello-world
Hello from Docker!
:
For more examples and ideas, visit:
https://docs.docker.com/get-started/
ベースになるリポジトリ
ベースはmyshell-ai/OpenVoiceを利用し、この中に必要なファイルを作成していきます。
git clone https://github.com/myshell-ai/OpenVoice.git
cd OpenVoice
checkpoint のダウンロードと解凍
checkpointをダウンロードし、 checkpoints_v2 ディレクトリに解凍します。
$ wget https://myshell-public-repo-host.s3.amazonaws.com/openvoice/checkpoints_v2_0417.zip -O checkpoints_v2.zip
$ unzip checkpoints_v2.zip
$ rm checkpoints_v2.zip
Dockerfile の作成
ここからはDockerfileの中で行っていきます。リポジトリの中に Dockerfile を作成して、編集してください
ベースイメージ
ベースは FROM continuumio/miniconda3 です
FROM continuumio/miniconda3
conda の設定
condaの設定を行います
RUN conda create -n openvoice python==3.9
SHELL ["conda", "run", "-n", "openvoice", "/bin/bash", "-c"]
必要なライブラリのインストール
OpenVoiceはffmpegを使っているので、それをインストールします。 /opt/artifact はDOKのアウトプット先のディレクトリです
RUN apt-get update && \
apt-get install -y ffmpeg && \
mkdir /app /opt/artifact
必要なPythonライブラリのインストール
OpenVoiceのリポジトリのファイルをすべてコピーします。そして、OpenVoice用にMeloTTSをインストールします。argparseやboto3はCLI実行用です。
WORKDIR /app
COPY . .
RUN pip install -e . && \
pip install argparse && \
pip install boto3 && \
pip install git+https://github.com/myshell-ai/MeloTTS.git && \
python -m unidic download
docker-entrypoint.sh の準備
Docker実行の際に呼び出す docker-entrypoint.sh (内容は後述)を準備します
RUN chmod +x /app/docker-entrypoint.sh
# Dockerコンテナー起動時に実行するスクリプトを指定して実行
CMD ["/bin/bash", "/app/docker-entrypoint.sh"]
Dockerfile全体
Dockerfileの全体はGitHubリポジトリで確認してください
docker-entrypoint.sh の作成
docker-entrypoint.sh はDockerコンテナー起動時に実行するスクリプトです。ここでは環境変数をチェックして、 runner.py を呼び出します。
$ wget https://raw.githubusercontent.com/goofmint/Dok-OpenVoice-Handson/refs/heads/main/docker-entrypoint.sh
docker-entrypoint.shの内容
行っている処理はシンプルなので、内容はGitHubリポジトリで確認してください
runner.py の作成
runner.py は実際に処理を行うスクリプトです。まず必要なライブラリをインポートします。
import os
import torch
from openvoice import se_extractor
from openvoice.api import ToneColorConverter
from melo.api import TTS
import argparse
import nltk
import boto3
nltk.download('averaged_perceptron_tagger_eng')
パラメータの取得
docker-entrypoint.sh から渡されたパラメータを取得します。
arg_parser = argparse.ArgumentParser()
arg_parser.add_argument(
'--output',
default='/opt/artifact',
help='出力先ディレクトリを指定します。',
)
arg_parser.add_argument(
'--text',
default='',
help='読み上げる文章',
)
arg_parser.add_argument(
'--id',
default='',
help='タスクIDを指定します。',
)
arg_parser.add_argument(
'--lang',
default='JP',
help='読み上げる言語を指定',
)
arg_parser.add_argument(
'--reference',
default='resources/example_reference.mp3',
help='リファレンスの音声',
)
arg_parser.add_argument('--s3-bucket', help='S3のバケットを指定します。')
arg_parser.add_argument('--s3-endpoint', help='S3互換エンドポイントのURLを指定します。')
arg_parser.add_argument('--s3-secret', help='S3のシークレットアクセスキーを指定します。')
arg_parser.add_argument('--s3-token', help='S3のアクセスキーIDを指定します。')
args = arg_parser.parse_args()
オブジェクトストレージ用のオブジェクトを準備
S3_ではじまる環境変数があれば、それを使ってS3オブジェクトを作成します。
s3 = None
if args.s3_token and args.s3_secret and args.s3_bucket:
# S3クライアントの作成
s3 = boto3.client(
's3',
endpoint_url=args.s3_endpoint if args.s3_endpoint else None,
aws_access_key_id=args.s3_token,
aws_secret_access_key=args.s3_secret)
OpenVoiceの設定
OpenVoice/demo_part3.ipynb at main · myshell-ai/OpenVoiceの内容に沿って、OpenVoiceを準備します。
ckpt_converter = 'checkpoints_v2/converter'
device = "cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = args.output
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
reference_speaker = args.reference
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, vad=True)
from melo.api import TTS
src_path = f'{output_dir}/tmp.wav'
speed = 1.0
model = TTS(language=args.lang, device=device)
speaker_ids = model.hps.data.spk2id
音声の生成とアップロード
音声を生成し、アップロードします。たとえば EN を指定した場合、インド風英語やオーストラリア風英語など複数のキーが speaker_ids に入ってきます。
for speaker_key in speaker_ids.keys():
speaker_id = speaker_ids[speaker_key]
speaker_key = speaker_key.lower().replace('_', '-')
source_se = torch.load(f'checkpoints_v2/base_speakers/ses/{speaker_key}.pth', map_location=device)
model.tts_to_file(args.text, speaker_id, src_path, speed=speed)
save_path = f'{args.output}/{args.id}_{speaker_key}.wav'
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
# オブジェクトストレージにアップロード
if s3 is not None:
s3.upload_file(
Filename=save_path,
Bucket=args.s3_bucket,
Key=os.path.basename(save_path))
全体の処理
runner.py の全体の内容は GitHubリポジトリで確認してください
Dockerイメージのビルド
ここまでの内容で、Dockerイメージをビルドします
コンテナレジストリの用意
Dockerイメージを登録するコンテナレジストリを作成します。さくらのクラウドのホームで、さくらのクラウド を選択します。

左側のメニューの グローバル の中にある コンテナレジストリ を選択します。

追加 を押して、コンテナレジストリを作成します。最低限、以下の入力が必要です。
| 項目 | 設定 |
|---|---|
| 名前 | 分かりやすい、任意の名前を入力してください |
| コンテナレジストリ名 | ドメイン名に使われます。以下では、 EXAMPLE.sakuracr.jp として説明します |
| 公開設定 | Pullのみとします |
ユーザーの作成
コンテナレジストリを作成したら、作成したコンテナレジストリを一覧でダブルクリックします。

詳細表示にて、ユーザータブをクリックします。

追加 ボタンを押し、ユーザーを作成します。 YOUR_USER_NAME と PASSWORD は任意のものを指定してください。
| 項目 | 設定 |
|---|---|
| ユーザー名 | YOUR_USER_NAME |
| パスワード | YOUR_PASSWORD |
| ユーザ権限設定 | All |
Dockerイメージのビルド
EXAMPLE.sakuracr.jp の部分は、作成したコンテナレジストリのドメイン名に置き換えてください。また、 openvoice は任意の名前で大丈夫です(以下はその名称で読み替えてください)。
sudo docker build \
-t EXAMPLE.sakuracr.jp/openvoice:latest .
コンテナレジストリへのログイン
作成したコンテナレジストリにログインします。ログインIDとパスワードが求められるので、作成したものを入力してください。
sudo docker login EXAMPLE.sakuracr.jp
イメージのプッシュ
作成したイメージをコンテナレジストリにプッシュします。イメージサイズが大きいので、数十分かかります。
sudo docker push EXAMPLE.sakuracr.jp/openvoice:latest
DOKで実行する
リポジトリがプッシュできたら、一番最初に行ったようにDOKでタスクを実行します。
- イメージ
EXAMPLE.sakuracr.jp/openvoice - 環境変数
- TEXT
お疲れ様でした! - LANG
JP
- TEXT
お片付け
忘れずに停止・削除をお願いします
- さくらのクラウドのサーバ
- オブジェクトストレージ
DOKについては、特に作業はありません