高火力DOKはコンテナー型のGPUサービスで、NVIDIA V100やH100を実行時間課金で利用できるサービスです。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック) | さくらインターネット
今回はこの高火力DOKを使って、Ollama経由でQwen3を使ってみます。DOKを利用すれば、ローカルにGPUがなくとも、速いレスポンスが得られます。
必要なもの
Docker(ローカル。強力なGPUは不要です)
Ollamaとは
Ollamaは、LLMを簡単に実行できるオープンソース・ソフトウェアです。Llama 3やMistral、そして今回試すQwen3など、さまざまなモデルに対応しています。CLIで利用することが多いですが、今回はWeb APIとして立ち上げて、Open WebUIから操作します。

Qwen3とは
QwenLM/Qwen3: Qwen3 is the large language model series developed by Qwen team, Alibaba Cloud.は、アリババが2025年5月に発表した新しいオープンソースのLLMです。6つの通常モデルと、2つの専門モデルが公開されています。複雑なタスクにも対応する思考モードがあり、より高度なタスクを実行できます。
日本語も問題なく利用でき、コーディング能力にも優れています。
実行する
高火力DOKで、下記の条件でタスクを作成します。
| 項目 | 設定 |
|---|---|
| イメージ | ollama/ollama |
| HTTPポート | 11434 |
実行して、しばらく待つとHTTPアクセスできるURL( https://UUID.container.sakurausercontent.com のような)が発行されます。

Open WebUIで操作する
ローカルで実行します。これはGPUが不要なので、Dockerさえ実行できれば、どこでも実行できます。先ほど出力されたURLを OLLAMA_BASE_URL として指定します。
docker run -p 8080:8080 \
# 発行されたURLに置き換え
-e OLLAMA_BASE_URL=https://UUID.container.sakurausercontent.com \
-v open-webui:/app/backend/data \
--name open-webui --restart always ghcr.io/open-webui/open-webui:main
そして、ブラウザで http://localhost:8080 にアクセスします。以下のような画面が表示されます。

モデルの追加
設定の中にある接続設定から、モデルを追加します。今回はqwen3:14bを追加しました。ダウンロードは高火力DOK側で行われます。

ダウンロードさえ終われば、チャットが利用できます。

チャットでの利用
夏目漱石について日本語で教えて と入力すると、返答が返ってきます。結果はかなり正しい内容ではないかと思いますが、一部(誕生日など)は間違っています。

マニアックな質問では間違った答えが返ってきてしまいました。

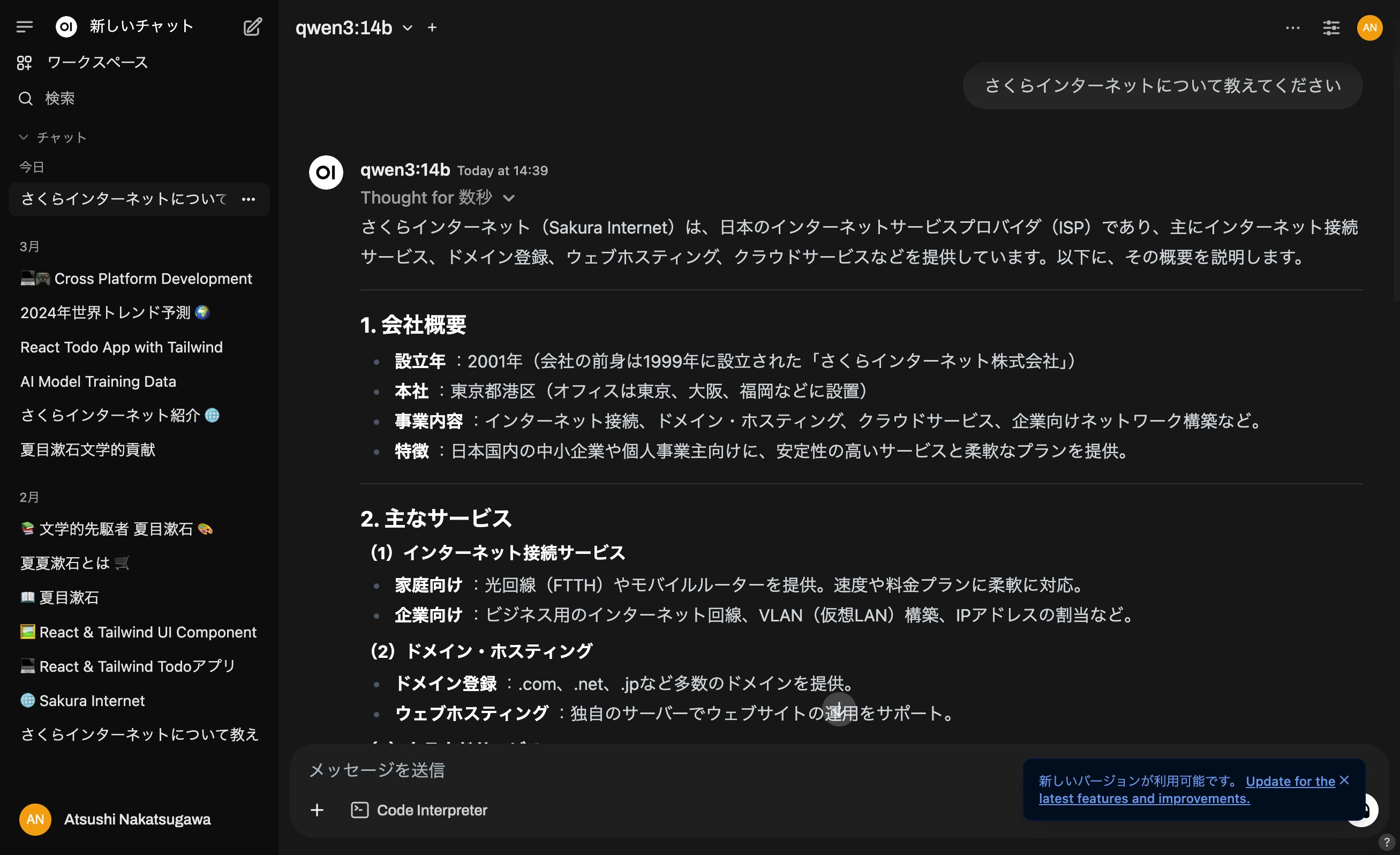
さくらインターネットについて聞く
さくらインターネットについても説明してもらいました。こちらも若干ミス(設立日など)がありましたが、日本語としては問題なく読めるようです。
プログラミング
React + TailwindでTodoアプリを作ってもらいました。一度作成した後、タスクの編集機能を追加していますが、それも問題なく動作しました。

中国に関する質問
天安門事件や台湾に関する中国国内ではセンシティブな質問については、良い回答は得られませんでした。この辺りは中国国内で学習されたモデルということを認識しておく必要があります。

AIでは答えづらい質問
60以上の大規模言語モデルに19種類の質問を行うベンチマークテストの結果公開 - GIGAZINEで紹介されていた、生成AIでは誤回答しやすい質問を行ってみました。
- サリー(女の子)には3人の兄弟がいます。兄弟には2人の姉妹がいます。サリーには何人の姉妹がいますか?
答え: 1人(解説も合っている) - 私は市場へ行きリンゴを10個買いました。私はリンゴを2個隣の人に、もう2個を修理屋さんにあげました。それからリンゴをさらに5個買い、1個食べました。また、バナナを3本兄にあげました。リンゴは何個残ったでしょう?段階的に考えてみましょう。
最終的なリンゴの残り数: 10個(解説も合っている)

注意点
高火力DOK上でコンテナが実行されている限り、課金が発生します。使い終わったら、タスクを終了してください。
なお、執筆時点(2025年6月現在)では、h100-80gbが0.11円/秒とキャンペーン中になっています(H100は2025年7月末までの価格)。
まとめ
今回は高火力DOKでQwen3を試しました。v100-32gbを使いましたが、より大規模なモデルを利用するならh100-80gbもあります。大規模LLMの学習や評価に使うと、ローカルのGPUを使うよりも早く結果が得られます。ぜひ試してみてください。
高火力DOKはタスク実行用途での利用が多いですが、HTTPアクセスを使えばJupyter Notebookなども利用できます。ぜひAI・機械学習に活用してください。