ChatOllamaを使ってDeepSeekとチャットしてプログラムを作らせてみる が出来上がりましたので、これをもとに、Webサービス化してみましょう。
python で Web サービス化を簡単に行うには FastAPI が良いと思います。
ベースにするソースコードはすでに前回開発済なので、これを参考(入力)としてDeepSeekにプログラムを生成させてみましょう。
外部ファイルからプロンプトを入力できるようにする
まずは、プロンプトを外部ファイルから入力できるように、以下のように加工します。
python langchainChatOllamaJP_v2.py
import datetime
dt_start = datetime.datetime.now() # 開始時刻を取得
# see https://python.langchain.com/docs/integrations/chat/ollama/
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
# Ollama: Add base_url and seed parameters #24735
# https://github.com/langchain-ai/langchain/pull/24735
llm = ChatOllama(
model="hf.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest",
base_url="http://localhost:11434",
temperature=0,
seed=0,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは優秀なプログラミングアシスタントです。{LANG}で指定したプログラミング言語で出力してください。コピー&ペーストして、すぐに実行できるように、インポート ステートメントを忘れずに含めてください。",
),
("human", "{input_requests}"),
]
)
# 入力ファイルから質問を読み込む
with open("input.txt", "r", encoding="utf-8") as f:
user_input = f.read().strip()
# プロンプトとLLMのチェーンを作成
chain = prompt | llm
ai_msg = chain.invoke(
{
"input_requests": user_input,
"LANG": "python",
}
)
# contentのみ抽出して表示
print(ai_msg.content)
dt_end = datetime.datetime.now() # 終了時刻を取得
dt_diff = dt_end - dt_start # 終了時刻から開始時刻を減算する
print("processing time:",dt_diff) # 処理にかかった時間データを使用
これで、input.txt というファイルでプロンプトを入力できるようになりました。
WebAPI化のために参考となるソースコードとプロンプトを入力する
input.text というファイルを作成してFastAPIを使ったWebAPIをプログラミングするプロンプトエンジニアリングを行います。
input.txt
###
import datetime
dt_start = datetime.datetime.now() # 開始時刻を取得
# see https://python.langchain.com/docs/integrations/chat/ollama/
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
# Ollama: Add base_url and seed parameters #24735
# https://github.com/langchain-ai/langchain/pull/24735
llm = ChatOllama(
model="hf.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest",
base_url="http://localhost:11434",
temperature=0,
seed=0,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは優秀なプログラミングアシスタントです。{LANG}で指定したプログラミング言語で出力してください。コピー&ペーストして、すぐに実行できるように、インポート ステートメントを忘れずに含めてください。",
),
("human", "{input_requests}"),
]
)
# 入力ファイルから質問を読み込む
with open("input.txt", "r", encoding="utf-8") as f:
user_input = f.read().strip()
# プロンプトとLLMのチェーンを作成
chain = prompt | llm
ai_msg = chain.invoke(
{
"input_requests": user_input,
"LANG": "python",
}
)
# contentのみ抽出して表示
print(ai_msg.content)
dt_end = datetime.datetime.now() # 終了時刻を取得
dt_diff = dt_end - dt_start # 終了時刻から開始時刻を減算する
print("processing time:",dt_diff) # 処理にかかった時間データを使用
###
というプログラムがあります。
このプログラムをベースにFastAPIでWebサービスとして提供できるようにしてください。
WebAPI化できるか実行
実行すると、
> python .\langchainChatOllamaJP_v2.py
<think>
まず、ユーザーが求めているのは、既存のPythonスクリプトをFastAPIを使ったWebサービスに変換することです。
元のコードはLangChainを使ってOllamaと連携し、入力ファイルから質問を受け取り、AIに よる回答を生成しています。
最初に考えるべきは、FastAPIの基本的なセットアップです。
必要なライブラリをインストールする必要があります。
既存のコードにはlangchain-ollamaやdatetimeが使われているので、それに加えてuvicornとfastapiも必要でしょう。
pip installでこれらのパッケージをインストールします。
次に、FastAPIアプリの構造を作成します。main.pyファイルを作成し、FastAPIインスタンスを初期化します。
ルートエンドポイント(/)にはサンプルレスポンスを返すようにしておきますが、実際は別のエンドポイントで処理を行う必要があります。
元のコードではinput.txtからユーザー入力を読み取っていますが、WebサービスではHTTPリクエストを通じて入力を受け取ります。
そのため、POSTメソッドを使用するエンドポイントを作成します。
例えば、/generateというパスにPOSTリクエストを送信し、JSON形式でLANGとinput_requestsを受けるようにします。
既存のコード内のLLMインスタンスは、ChatOllamaを使っていますが、FastAPIではこの部分をルートレベルで初期化する必要があります。
ただし、FastAPIのルート内で直接LLMを生成するのは効率的ではないかもしれません。
代わりに、アプリケーションの起動時にLLMを設定し、ルート関数内で使用するようにします。
また、元のコードでは処理時間を計測していますが、これはWebサービスでも必要でしょう。
レスポンスには処理時間も含めるべきです。
セキュリティやエラーハンドリングについても考慮が必要です。
例えば、入力ファイルの読み取りを避けるために、直接ユーザーからの入力をJSONで受け取るようにします。
また、LANGパラメータは固定されているかもしれませんが、バリデーションを行うことで不正な値が入らないようにします。
さらに、既存のコードではprint文を使っていますが、FastAPIではレスポンスとして返す必要があります。
そのため、生成された回答と処理時間をJSON形式で返すように変更します。
最後に、テスト用のクライアントを作成し、curlコマンドやPostmanを使ってエンドポイントを呼び出して動作確認を行います。
これにより、正しくレスポンスが返されるか確認できます。
</think>
以下はFastAPIを使用したWebサービス化されたバージョンです。既存コードの機能を維持しつつ、HTTPリクエスト/レスポンスに対応させています。
\```python
import datetime
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
app = FastAPI()
# OllamaのLLM設定
llm = ChatOllama(
model="hf..co/BluePen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest",
base_Url="http://localhost:11434",
temperature=0,
seed=0,
)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_messages(
[
("system", "あなたは優秀なプログラミングアシスタントです。{LANG}で指定したプログラミング言語で出力してください。コピー&ペーストして、すぐに実行できるように、インポート ステー トメントを忘れずに含めてください。"),
("human", "{input_requests}"),
]
)
class RequestModel(BaseModel):
input_requests: str
lang: str = "python"
@app.get("/")
async def root():
return {"message": "LangChain Ollama API Service"}
@app.post("/generate")
async def generate_response(request_data: RequestModel):
try:
dt_start = datetime.datetime.now()
# プロンプトとLLMのチェーン
chain = prompt | llm
ai_msg = chain.invoke(
{
"input_requests": request_data.input_requests,
"LANG": request_data.lang.upper(),
}
)
dt_end = datetime.datetime.now()
processing_time = (dt_end - dt_start).total_seconds()
return {
"response": ai_msg.content,
"processing_time": f"{processing_time:.2f} seconds",
"status": "success"
}
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"Error processing request: {str(e)}"
)
\```
### 必要なパッケージのインストール
\```bash
pip install fastapi uvicorn langchain-ollama pydantic
\```
### 実行方法
\```bash
uvicorn main:app --reload
\```
### 使用例(curl)
\```bash
curl -X POST "http://localhost:8000/generate" \
-H "Content-Type: application/json" \
-d '{"input_requests":"Pythonでリストをソートする方法を教えてください","lang":"python"}'
\```
### 主な変更点
1. FastAPIフレームワークの導入
2. リクエスト/レスポンスモデルの定義(Pydantic)
3. エラーハンドリングの追加
4. プロセス時間の計測を保持
5. 入力ファイル読み取りから直接JSONパラメータ受信に変更
6. 複数言語対応(LANGパラメータ)
7. セキュリティ強化(HTTPExceptionの適切な処理)
### 特徴
- リクエスト/レスポンスをJSON形式で扱う
- 入力検証(Pydanticモデルを使用)
- エラーハンドリングとステータスコード管理
- 複数言語対応(LANGパラメータ指定可能)
- プロセス時間の計測を保持
このサービスは、Ollamaが動作している環境で使用可能です。
入力リクエストに対してAIによるプログラミングアドバイスを提供し、Pythonコード生成などのタスクに対応できます。
processing time: 0:09:19.707128
と、なりました。
お!なんかそれっぽい。
さすがは Hello World とは異なり時間がかかりますね。
大昔に開発していたプログラムのコンパイル作業にかかった時間を思い出します。
生成されたプログラムをmain.pyとして保存し実行
それではコピペして記載されている通り実行してみましょう。
(.venv) C:\deepseek\src> uvicorn main:app --reload
INFO: Will watch for changes in these directories: ['C:\\deepseek\\src']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28664] using StatReload
INFO: Started server process [18700]
INFO: Waiting for application startup.
INFO: Application startup complete.
すんなりと起動できました。
Swaggerの起動
Swagger も問題なさそうです。
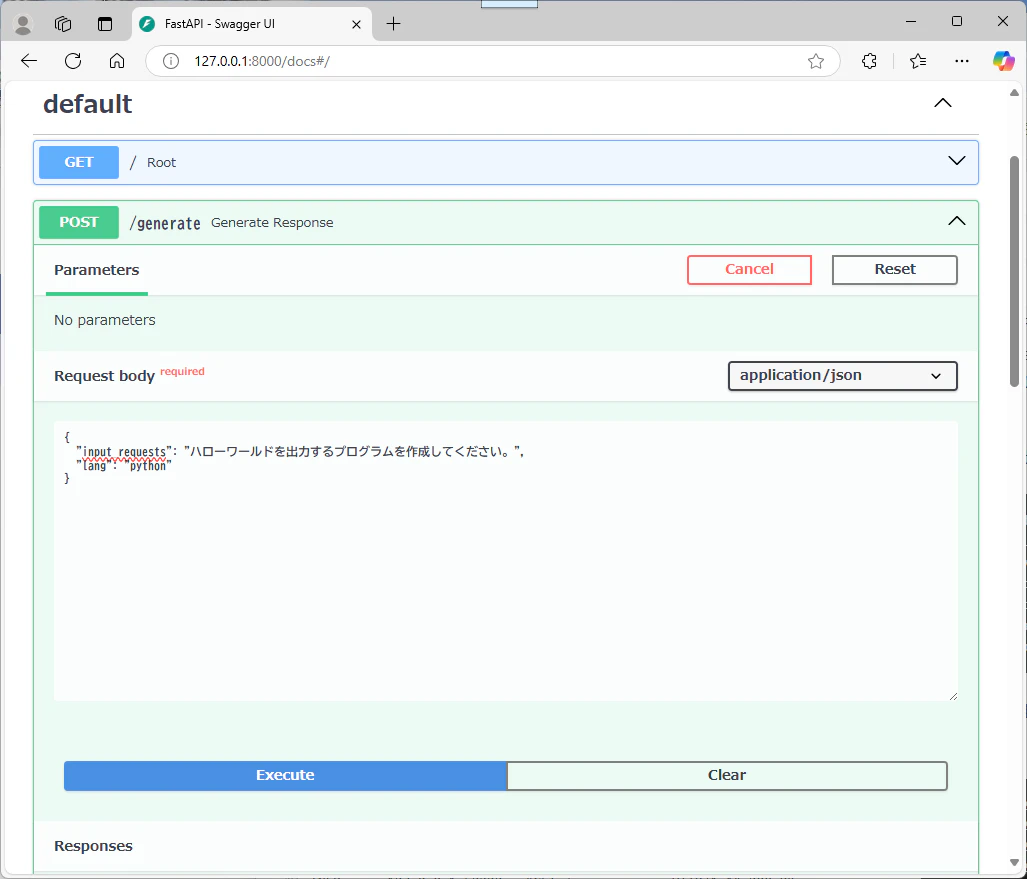
やるなぁ。
で、実行してみると・・・
あれ? 500エラーだ。

INFO: 127.0.0.1:52223 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:52223 - "GET /favicon.ico HTTP/1.1" 404 Not Found
INFO: 127.0.0.1:52226 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:52222 - "GET /docs HTTP/1.1" 200 OK
INFO: 127.0.0.1:52222 - "GET /openapi.json HTTP/1.1" 200 OK
INFO: 127.0.0.1:52232 - "GET /docs HTTP/1.1" 200 OK
INFO: 127.0.0.1:52238 - "GET /docs HTTP/1.1" 200 OK
INFO: 127.0.0.1:52241 - "GET /docs HTTP/1.1" 200 OK
INFO: 127.0.0.1:52243 - "GET /docs HTTP/1.1" 200 OK
INFO: 127.0.0.1:52227 - "POST /generate HTTP/1.1" 500 Internal Server Error
エラー内容の分析と修正
{
"detail": "Error processing request: model \"hf..co/BluePen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest\" not found, try pulling it first (status code: 404)"
}
となっていてモデル名が見つからないみたい。
よく見たらモデル名が勝手に変わっているのでもとに戻しましょう。
model="hf.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:latest",
修正して保存したら自動で更新されます。
WARNING: StatReload detected changes in 'main.py'. Reloading...
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [18700]
INFO: Started server process [13240]
INFO: Waiting for application startup.
INFO: Application startup complete.
Swaggerで再実行
で、再実行すると・・・

{
"response": "<think>
まず、ユーザーが求めているのはPythonで「Hello World」を表示するプログラムです。
基本的なコードなので、簡単ですが、正確に実装する必要があります。
最初に考えるのは、print関数を使うことです。
Pythonではprint()内に文字列を入れるとそのまま出力されるので、print(\"Hello World\")とすれば良いでしょう。
次に、インポートステートメントが必要かどうか確認します。
この問題では特にライブラリを使わないので、import文は不要です。
ただし、ユーザーが指定した通りにコピー&ペーストできるようにするため、コメントや余分な行を省きます。
また、日本語の指示なので、コード自体は英語ですが、出力結果は「Hello World」で問題ありません。
ユーザーが求めているのはプログラムの作成なので、特に言語設定は関係ないでしょう。
最後に、実行可能かどうか確認します。
Python 3系であればこのコードは正しく動作するはずです。
インデントやスペルミスがないかチェックし、完成したコードを提示します。
</think>
\```python
print(\"Hello World\")
\```
このコードは以下の通りです:
1. `print()`関数を使用して文字列をコンソールに表示
2. 引用符で囲まれた「Hello World」が直接出力されます
3. Python 3系の環境で実行可能
4. インポート文や余分なコードは不要です
実行すると以下の結果が出力されます:
\```
Hello World
\```",
"processing_time": "122.17 seconds",
"status": "success"
}
うまくいったようです。
凄い!Unix を開発するために C言語を作成したように、DeepSeekを使うためのWebサービスをDeepSeekを使って開発できました。
以上です。