twitter で評判だった「Linux のしくみ」を最近買いました。前評判通り、実際に動くコードを用いて実験ベースで Linux の仕組みを説明してくれる良い本で、これは非常にお勧めできるなと思いました(6〜7割よみつつ、今いろんな箇所の実験を手元でやってみています)。
第4章 プロセススケジューラの部分では、プロセスに対して、論理CPU がどのように割り当てられるのか説明しつつ、それが本当に正しいのかを、コードを使って実験してみることにより示していました。だいたいの内容を読み、まぁそうですよね...と納得しつつも、実際に手元マシンで実験してみたことはなかったので、今回自分の手を動かしてやってみることにしました。
実験内容
- 複数のプロセスを生成して、それぞれのプロセスにおいてループを回して、ユーザーモードの負荷をかけたとき、どのように各プロセスが実行されるかを観察する
- 測定の際は、複数の論理CPUにまたがって実行されないよう
tasksetコマンドで実行する論理 CPU を指定する
- 測定の際は、複数の論理CPUにまたがって実行されないよう
- 本のコードは、わりと真面目に良い感じの実験結果が得られるような処理やエラー処理が丁寧に書かれていた
- が、少々長くて写経が面倒だったので、本質的なふるまいはかわらないように適当にコードを書いて実験してみた
- もしかしたら実験結果に影響を与えるような箇所があるかもしれないので、気づいた方はご指摘ください
- エラー処理とか、事前の見積もり処理などのコードをごっそり省いて動けばいいやみたいな感じで書いた、かなり雑なコードなので、みなさんコピペして実行しないでください
- もしコピペするとしても内容を確認して、どうでもいいサーバーで実行してください(事故っても責任とりません)
# include <stdio.h>
# include <stdlib.h>
# include <unistd.h>
# include <time.h>
# define LOOP_COUNT 100000UL
# define NSEC_PER_SEC 1000000000UL
static inline void loop()
{
long i;
for(i = 0; i < LOOP_COUNT; i++);
}
static inline void print_progress(long elapsed_time_nsec, int pid, int progress)
{
printf("%ld\t%d\t%d\n", elapsed_time_nsec, pid, progress);
}
static inline long diff_nsec(struct timespec before, struct timespec after)
{
return (after.tv_sec * NSEC_PER_SEC + after.tv_nsec) - (before.tv_sec * NSEC_PER_SEC + before.tv_nsec);
}
static inline void child_function(int id, struct timespec before)
{
struct timespec after;
int i;
for (i = 0; i < 100; i++) {
clock_gettime(CLOCK_MONOTONIC, &after);
print_progress(diff_nsec(before, after), id, i);
loop();
}
clock_gettime(CLOCK_MONOTONIC, &after);
print_progress(diff_nsec(before, after), id, 100);
}
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stdout, "Usage: %s nproc\n", argv[0]);
exit(1);
}
int nproc = atoi(argv[1]);
if (nproc < 1) {
fprintf(stdout, "Argument: invalid nproc %s nproc\n", argv[0]);
exit(1);
}
struct timespec before;
clock_gettime(CLOCK_MONOTONIC, &before);
int i;
for (i = 0; i < nproc; i++) {
pid_t pid = fork();
if (pid < 0) {
fprintf(stdout, "error\n");
exit(1);
} else if (pid == 0) {
// child process
child_function(i, before);
exit(0);
}
}
// parent process
int j;
for (j = 0; j < nproc; j++) {
wait(NULL);
}
printf("\n");
exit(0);
}
実験結果
- 次のような感じで、論理CPU を指定し、プロセス数を1, 2, 4 のバリエーションで実行してみました
taskset -c 0 ./test 1
taskset -c 0 ./test 2
taskset -c 0 ./test 4
- わりと綺麗な結果がとれたので、出力をいい感じに整形し gnuplot でグラフ化してみました
プロセス数 1
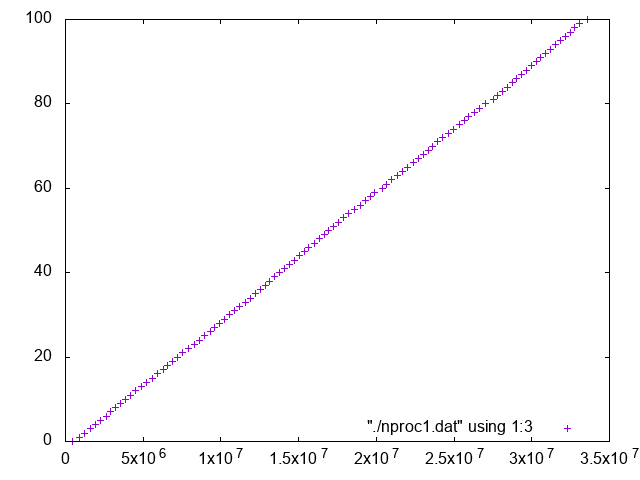
throughput: 1 process / 33615570 nsec = 29.748 process / sec
latency(id=0): 3.36x10^7 nsec
プロセス数 2
throughput: 2 process / 64405632 nsec = 31.053 process / sec
latency(id=0): 5.31x10^7 nsec
latency(id=1): 5.40x10^7 nsec
latency(ave.): 5.36x10-7 nsec
プロセス数 4

throughput: 4 process / 130027521 nsec = 30.762 process / sec
latency(id=0): 8.67x10^7 nsec
latency(id=1): 10.9x10^7 nsec
latency(id=2): 8.71x10^7 nsec
latency(id=3): 10.8x10^7 nsec
latency(ave.): 9.77x10^7 nsec
測定結果のまとめ
- 雑に1回しか計測してないのでざっくりとした傾向しかでないですが、以下のように表にまとめられる
| プロセス数 | スループット (process/sec) | 平均レイテンシ (x10^7 [nsec]) |
|---|---|---|
| 1 | 29.748 | 3.36 |
| 2 | 31.053 | 5.36 |
| 4 | 30.762 | 9.77 |
- 論理CPUを使い切っている場合には、プロセス数を増やしてもスループットは変わらない
- 実際のプロセスは I/O wait など色々あり、色々
- グラフ化することによりコンテクストスイッチが発生している様子が実際目に見える
- ラウンドロビンで均等に割り振られている(
niceなどで優先度操作をしなければ...) -
niceは デフォルトを 0 として、 [-20, 20] の範囲でプロセスに優先度をつけ、CPU時間はそれに応じて割り振られる
- ラウンドロビンで均等に割り振られている(
- プロセス数を増やすとレイテンシは悪化する
本に書いてあった内容について、雑な実験でそれっぽいことが確認できた
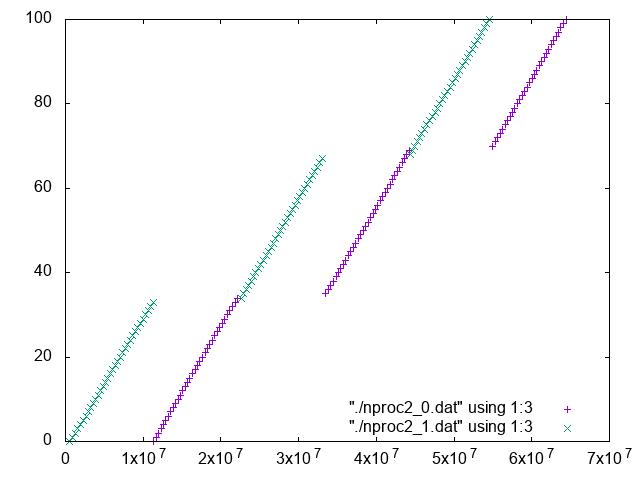
論理CPU が複数ある場合
以下のような環境で実験してみる(この実験結果は前の実験に使ったマシンとは異なるもので実験しているので、スループットやレイテンシは比較しないでください)
$ grep proc /proc/cpuinfo
processor : 0
processor : 1
processor : 2

- 複数のプロセスが同時に進捗しているのがわかる
さいごに
- 「Linux のしくみ」 おすすめできる
- 買った人は読みつつも自分で実験してみたりすると楽しい
- これ読んだ後に詳解システム・パフォーマンスとか読むとバランス的に良さそう
- Linux のしくみは、詳解システム・パフォーマンスを読む上での橋渡しになるような内容が書かれている気がします