今回はテーブルデータから2値分類をするTransformerモデルを実装します。
使用するモデルはFTTransformerです。
実行環境
- WSL2
- CUDA 12.1.0
- Python 3.9.14
- pytorch 2.4.0+cu121
ライブラリのインストール
pip install rtdl_revisiting_models tqdm sklearn numpy matplotlib
実行コード
import torch
import torchvision
from tqdm import tqdm
from rtdl_revisiting_models import FTTransformer
from sklearn.metrics import accuracy_score
import scipy
import numpy as np
import matplotlib.pyplot as plt
- 学習の設定
# GPUを使用
device = torch.device('cuda')
# epoch数
n_epochs = 5
# batchサイズ
batch_size = 32
- データの準備
今回はMNISTを使います。(訓練データを小さくして学習時間を短くしています。)
#訓練データ
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
download=True,
)
train_dataset = torch.utils.data.TensorDataset(
train_dataset.data.reshape(train_dataset.data.shape[0], -1).float().to(device),
(train_dataset.targets % 2 == 0).float().unsqueeze(1).to(device),
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
train_dataloader = list(train_dataloader)[:50]
#検証データ
valid_dataset = torchvision.datasets.MNIST(
root='./data',
train=False,
download=True,
)
valid_dataset = torch.utils.data.TensorDataset(
valid_dataset.data.reshape(valid_dataset.data.shape[0], -1).float().to(device),
(valid_dataset.targets % 2 == 0).float().unsqueeze(1).to(device),
)
valid_dataloader = torch.utils.data.DataLoader(
valid_dataset,
batch_size=batch_size,
shuffle=False
)
- 評価関数
今回は評価指標としてAccuracyを使用します。
def evaluate(model, dataloader):
with torch.no_grad():
model.eval()
y_pred = []
y_true = []
for batch, label in tqdm(dataloader):
y_pred.append(model(batch, None))
y_true.append(label)
y_pred = torch.cat(y_pred).squeeze().cpu().numpy()
y_true = torch.cat(y_true).squeeze().cpu().numpy()
y_pred = np.round(scipy.special.expit(y_pred))
score = accuracy_score(y_true, y_pred)
return score
- モデルの定義
# FTTransformer
model = FTTransformer(
n_cont_features=train_dataset.tensors[0].shape[1],
cat_cardinalities=[],
d_out=1,
**FTTransformer.get_default_kwargs(),
).to(device)
# 最適化アルゴリズム
optimizer = model.make_default_optimizer()
# Loss関数
loss_fn = torch.nn.BCEWithLogitsLoss()
- 学習
# 損失や評価値の初期化
train_losses = []
valid_losses = []
train_metricses = []
valid_metricses = []
for epoch in range(n_epochs):
# 訓練データでパラメータ更新
train_loss = 0
for batch, label in tqdm(train_dataloader):
model.train()
optimizer.zero_grad()
loss = loss_fn(model(batch, None), label)
train_loss += loss.cpu().item() * batch.shape[0]
loss.backward()
optimizer.step()
train_loss = train_loss / train_dataset[:][0].shape[0]
# 評価データで損失の計算
valid_loss = 0
for batch, label in tqdm(valid_dataloader):
with torch.no_grad():
model.eval()
loss = loss_fn(model(batch, None), label)
valid_loss += loss.cpu().item() * batch.shape[0]
valid_loss = valid_loss / valid_dataset[:][0].shape[0]
# 訓練データと評価データでの評価指標の計算
train_metrics = evaluate(model, train_dataloader)
valid_metrics = evaluate(model, valid_dataloader)
# 評価結果の追記
train_losses.append(train_loss)
valid_losses.append(valid_loss)
train_metricses.append(train_metrics)
valid_metricses.append(valid_metrics)
print(
f'epoch={epoch+1}',
f'train_loss={train_loss}',
f'valid_loss={valid_loss}',
f'train_metrics={train_metrics}',
f'valid_metrics={valid_metrics}',
)
- 評価結果の可視化
plt.figure()
plt.plot(range(len(train_losses)), train_losses, label='train', color='C0')
plt.plot(range(len(valid_losses)), valid_losses, label='valid', color='C1')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('loss')
plt.legend()
plt.show()
plt.close()
plt.figure()
plt.plot(range(len(train_metricses)), train_metricses, label='train', color='C0')
plt.plot(range(len(valid_metricses)), valid_metricses, label='valid', color='C1')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('accuracy')
plt.legend()
plt.show()
plt.close()
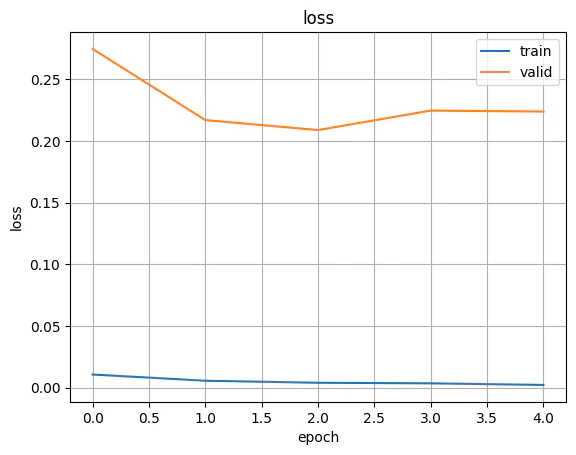
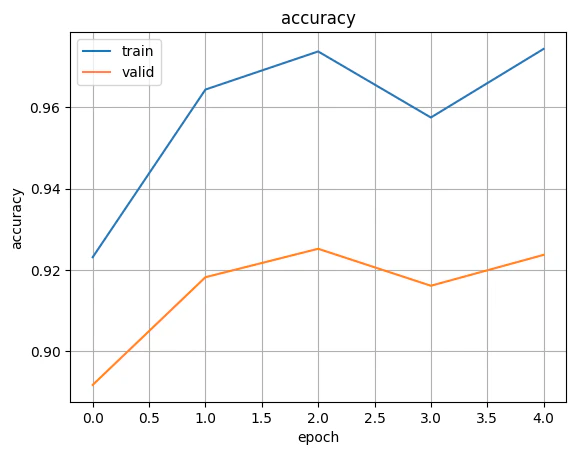
終わりに
簡単なMNISTとはいえ流石Transformerですね。すぐに高い精度に到達しました。