最近文章をEmbeddingして遊ぶのにハマっています。
今回は文章をEmbeddingしてできた多次元ベクトルを視覚的に分かりやすいように2次元平面上にプロットします。
環境
- WSL2
- DockerのUbuntu22.04コンテナ
- Python 3.12.3
使ったもの
Embeddingモデル
intfloat/multilingual-e5-large
文章を1024次元へ埋め込みしてくれるモデル。
無料かつローカルで動作します。
MITライセンス。
それほど重くないのに結構いい感じにEmbeddingしてくれる。
多分CPUでも十分早い。
多次元ベクトル→2次元ベクトルの圧縮
- PCA
- MDS(ユークリッド距離)
- MDS(コサイン距離)
下準備
pip install sentence_transformers pandas scikit-learn
pip install matplotlib matplotlib-fontja
コード
必要なもののインポート
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from sklearn.manifold import MDS
from sklearn.metrics.pairwise import cosine_distances
import matplotlib.pyplot as plt
import matplotlib_fontja
文章の用意
今回はQiitaのトレンド記事のタイトルを20件ほど持ってきました。
texts = [
'AWS から OCI に移行してコストを約半額にした話',
'人類は気づいていた。この勉強の仕方が1番早いということを。',
'なぜsortコマンドはuniq機能を含んでいるのか?(Unix哲学はどこ行った!?)',
'AWS LambdaをDocker化する際の注意点と学びの備忘録',
'Dockerのコンテナイメージを1/10以上軽量化してみた',
'Git GUIツールについて',
'VMware Workstation Pro と VMware Fusion Pro の個人利用版が無償になったので使ってみた (2024 年 5 月)',
'【TypeScript】デスクトップアプリ、作りたくね?',
'自社製品のUIデザインを改善した話【Pleasanter】',
'M5Stack CoreMP135に早速最新のLinux 6.9を移植した & Arch Linuxもついでに',
'【AWS】S3のストレージクラスを変更してコストカットする',
'GPT-4o モデルに curl コマンドで画像をプロンプトとして送信する方法',
'初海外カンファレンス, NervesConf US 参加記:飛行機編',
'NRQL(New Relic Query Language)を実行するUIのUXが改善され、より使いやすくなりました!',
'New Relicでログ解析してますか?しっかり使って、楽するところは楽しませんか?',
'PLATEAUでSTYLYの都市XRを作る!',
'カスタマーサクセスなら見ておくべき4つの先行指標',
'【個人開発】プレゼントして欲しいものを謎解きで伝えることができるアプリを開発しました',
'Docker composeのコマンドの挙動も図解にして覚えやすくしてみた',
'Dockerユーザー必見!データ消失を防ぐマウント方法ガイド',
]
E5でのEmbedding
model = SentenceTransformer('intfloat/multilingual-e5-large')
vectors = pd.DataFrame(model.encode(texts), index=texts)
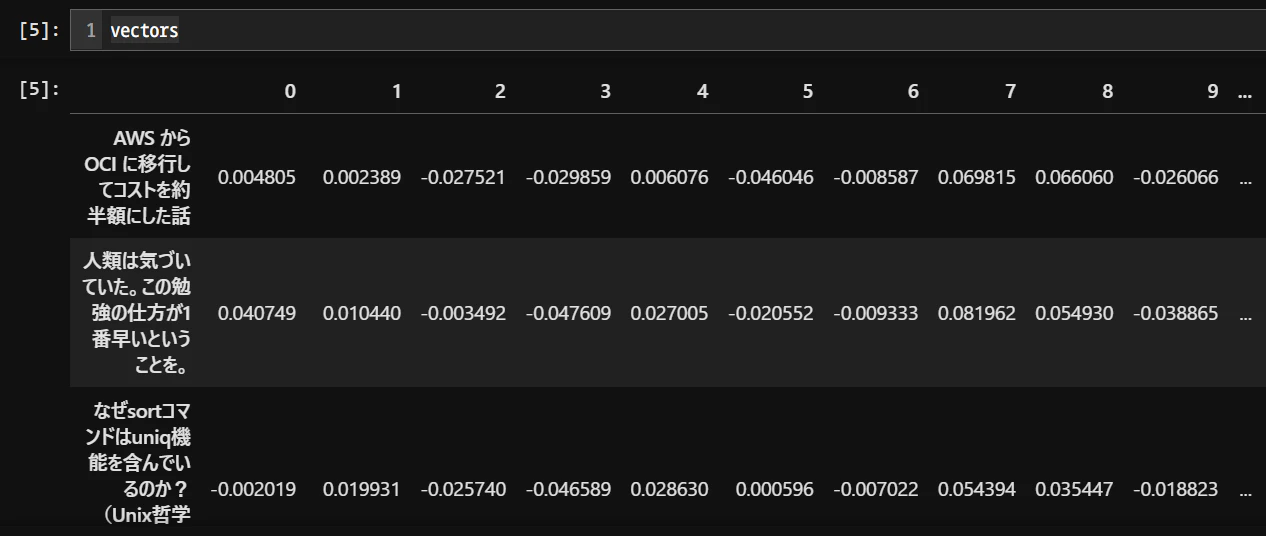
こんな感じに縦方向は文章、横方向は1024次元ベクトルになります。
PCAで圧縮
pca = PCA(n_components=2, random_state=0)
pca_vectors = pd.DataFrame(pca.fit_transform(vectors), index=texts)
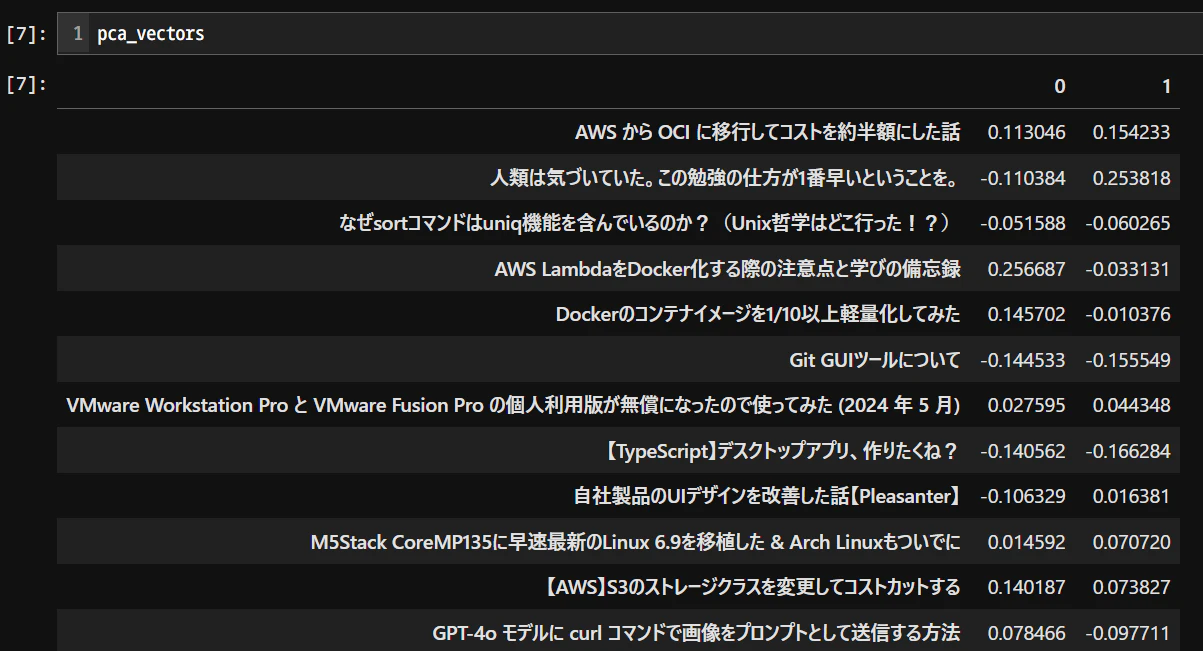
二次元ベクトルになっていますね。
PCA結果の可視化
plt.figure()
plt.scatter(pca_vectors[0], pca_vectors[1], s=10, color='r')
for text, pos in pca_vectors.iterrows():
plt.text(*pos, text, ha='center', size=6)
plt.title('PCA')
plt.grid()
plt.show()
plt.close()
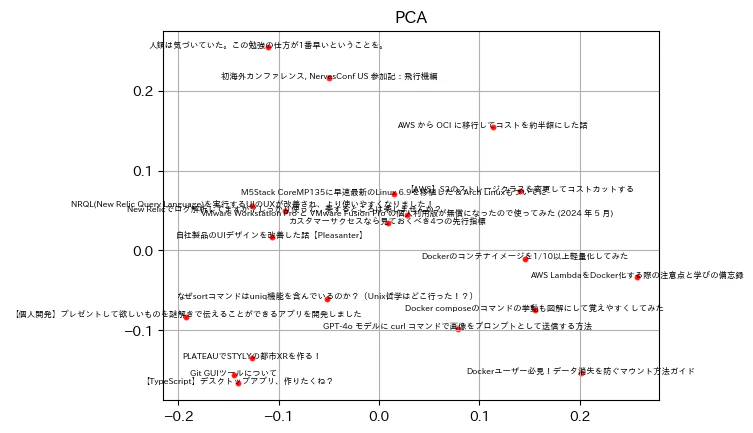
なるほど。
MDS(ユークリッド距離)で圧縮
mds = MDS(n_components=2, dissimilarity='euclidean', random_state=0)
mds_vectors = pd.DataFrame(mds.fit_transform(vectors), index=texts)
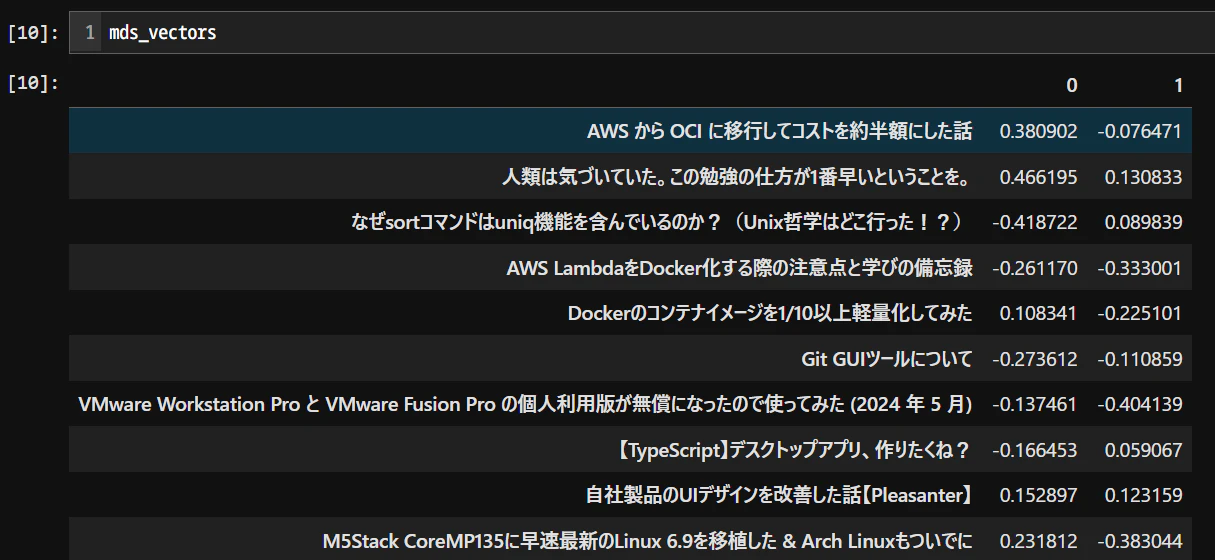
MDS(ユークリッド距離)結果の可視化
plt.figure()
plt.scatter(mds_vectors[0], mds_vectors[1], s=10, color='r')
for text, pos in mds_vectors.iterrows():
plt.text(*pos, text, ha='center', size=6)
plt.title('MDS euclidean')
plt.grid()
plt.show()
plt.close()
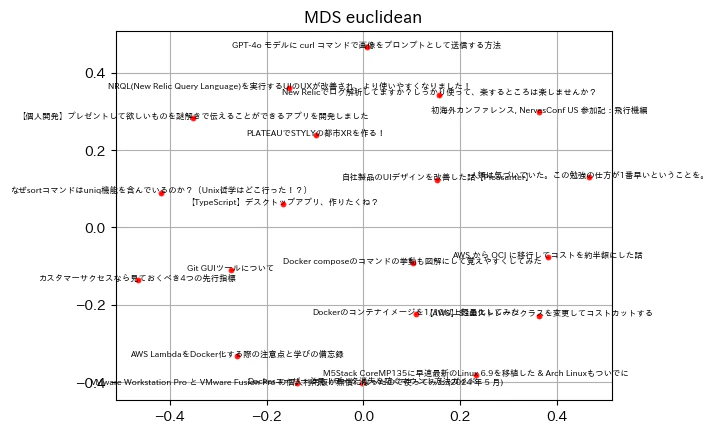
たまたまだと思いますが、PCAより散らばっていて見やすくなっているように感じますね。
MDS(コサイン距離)で圧縮
scikit-learnのMDSモジュールでユークリッド距離以外の距離をもとにMDSをする場合、事前に自分で距離を計算しておく必要があります。
今回はコサイン距離を求めておきます。
pd.DataFrame(cosine_distances(vectors), index=texts, columns=texts)

こんな感じで、コサイン距離はベクトル同士が似ていると小さな値、似ていないと大きな値になります。
同一のベクトル間の距離(対角成分)は0になります。
これをもとにMDSを求めます。
既に距離は求められているのでdissimilarityの値を'precomputed'とします。
mds_cosine = MDS(n_components=2, dissimilarity='precomputed', random_state=0)
mds_cosine_vectors = pd.DataFrame(mds_cosine.fit_transform(cosine_distances(vectors)), index=texts)

MDS(コサイン距離)結果の可視化
plt.figure()
plt.scatter(mds_cosine_vectors[0], mds_cosine_vectors[1], s=10, color='r')
for text, pos in mds_cosine_vectors.iterrows():
plt.text(*pos, text, ha='center', size=6)
plt.title('MDS cosine')
plt.grid()
plt.show()
plt.close()
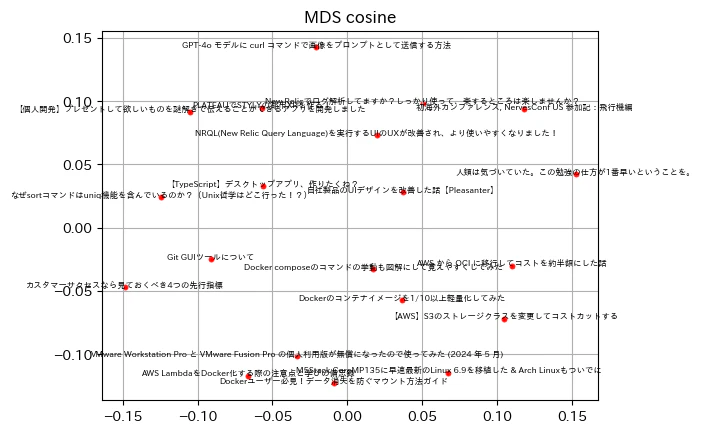
下半分にはDockerとかAWSとかのツールにまつわること、右上にはポエムっぽいことが分布していて良い感じですね。
おわり
個人的にはコサイン距離を使ったMDSが一番良いと思いました。
ベクトルといえばコサイン類似度ですし。