突然の本番障害
AWS ECSにデプロイしていたWebアプリケーションが、いきなりアクセスできなくなった。
顧客からシステムにアクセスできないとの連絡があり、実際の画面にアクセスしようとすると、504エラーが発生し、以下のような画面が表示された。

対象のWebアプリでは「ステージング」と「本番」の2環境が用意されている。
上記のエラーが起きたのは本番の環境。
ステージング環境にアクセスしてみると、問題なくアクセスすることができた。
よりによって本番環境だけでアクセスできないエラーが発生してしまった。
ステージング環境と本番環境のインフラ構成は基本的に同じであり、両環境ともエラーが発生する直近でインフラ構成の変更などはしてない。
プログラムの中身は、ステージング環境にリリース前のプログラムがデプロイされており、ステージングの方がいくらか新しい状態になっている。
調査
ステージング環境と本番環境でビルドされているプログラムに差異はあるものの、事象が発生したタイミングやエラーの内容的にプログラムが原因ではなさそう。
エラーメッセージ的にはネットワークに原因がありそうだが、VPCの構成はステージング環境と同じであり、前述した通り構成の変更なども行っていない中で突然アクセスができなくなったので、VPCやロードバランサに原因があるとも考えにくい。
アプリのデプロイ先がECSになっているので、とりあえずECSマネジメントコンソール上で本番環境のECSタスクの状態を確認。
すると、1つのタスクを除いて複数のタスクが起動に失敗している。
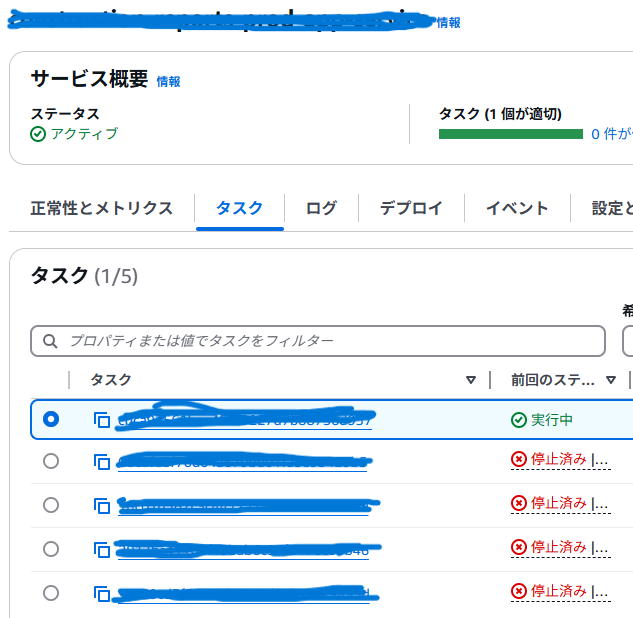
エラーになっているタスクの詳細を見てみると、以下のようなメッセージが。
タスクの停止時刻: 2025-XX-XXT00:00:00.000Z
CannotPullContainerError: pull image manifest has been retried 1 time(s):
failed to resolve ref xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxxxx-app-prod@sha256:xxxxxxxxxxxxxxx:
xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxxxx-app-prod@sha256:xxxxxxxxxxxxxxx:
not found
どうやら、ECRからイメージを見つけることができずプルできていないらしい。
ただ、ネットワーク構成などは変えておらず、ステージングは正常に動作しているため、ネットワークの問題でプルができなくなったとは考えにくい。
ECRを確認したところ、イメージそのものは存在している。
だとすれば、指定されたダイジェストのイメージがECRのライフサイクルポリシーによって削除された結果、イメージが存在しない状態になった可能性が高そう。
その場合、現時点でECR上に存在する最新のイメージで再デプロイしてしまえば、エラーは解消されそうだと予想。
ということで、ECSの本番環境でデプロイを実施。
デプロイ完了後にWebアプリへアクセスすると、504エラーは消えて正常に画面が表示された。
ということで、Webアプリにアクセスできない障害はとりあえず解消した。
原因
ビルドの問題
エラーの内容は、ECR上にイメージが見つからなずプルできないというものでした。なぜそのようなことになってしまったかというと、ビルドの仕組みに問題があった。
ビルドとデプロイに関する構成はざっくり以下のようなイメージ。

ビルドは以下の流れで行われる。
- CodeBuild上からボタン押下でビルドを手動実行
- 最新のコードをリポジトリからクローンし、イメージビルドを実行
- ビルドされたイメージをステージングと本番環境それぞれのECRにプッシュする
デプロイは、ECRのマネジメントコンソール上から手動でサービスを更新する。
問題は、ビルド時にステージング環境と本番環境の両方のリポジトリにイメージをプッシュしていたこと。
ECRのライフサイクルポリシーでは、プッシュされたイメージの履歴を10個まで保持する設定になっていた。しかし、本番環境のデプロイをしばらく行わないまま、ビルド&ステージング環境デプロイを繰り返した結果、ビルド回数が10回を超えたところで本番環境のECS(のサービス)が参照しているイメージの履歴がなくなってしまった。
その結果、イメージのプルができず、タスク起動に失敗していた。
なぜ504エラー?
イメージがプルできなくなった原因は分かったが、それによってなぜ「504 Gateway Time-out」のエラーが出るのかがよく分からなかった。
詳細を調べた結果、以下の結論におちついた。
- 何らかのきっかけでタスクの置き換え・再起動が発生
- ヘルスチェックの失敗、あるいはスケーリングによるタスクの起動が起きた
- ECRにイメージがなくプルに失敗
- リトライするが、全て失敗し、稼働中のタスクがなくなる
- 正常なターゲットがなくなり、ロードバランサからリクエストを転送できず、Timeoutが返される
- また、起動中のタスクに負荷が集中した結果、リクエストを転送できず、Timeoutが返される
という事みたいです。
対策
ECRライフサイクルの見直し
ECRでイメージの履歴を10個まで保持するようにしていたので、単純にその数を増やすことで同じ事象の発生を抑えることはできそう。
最も簡単にできる回避策ではあるけれど、根本的な解決策とまではいかない。
長期間、本番リリースがないままに開発が進行してりまうと、再発のリスクがある。
本番デプロイの頻度を増やす
10個まで履歴を保持できるイメージが参照できなくなったということは、本番デプロイをしない間にビルド&ステージング環境デプロイを10回以上実行したという事。
差異が大きくなる前にさっさとリリースすればよいのでは?と思う人も多いことでしょう。私自身、リリース頻度もっと上げてもいいのでは?と思う。
ただ、顧客(エンドユーザー)側の都合と、一緒に開発をしている会社の都合も関わってくるため、リリースに対する考え方を変えるのは意外と難しそう。
書籍「ソフトウェアファースト」によると、米テクノロジー企業の本番環境へのデプロイ頻度が以下のようにまとめられていた。
- Amazon:23,000回/日
- Google:5,500回/日
- ネットフリックス:500回/日
- メタ:1/日
- X(旧Twitter):3/週
そもそも会社の規模や文化も違うし、サービスの特性なども異なるので単純比較はできません。
到底真似できるものでもないけれど、スピード感を持ってソフトウェアの価値を高めるには、このくらい高頻度でリリースができるくらいに、リリースを手軽なものにすることが重要なんだろうなと思う。そういったアジャイルな思想が世の中全体にもうちょっと浸透していけば良いなと思った。
ビルドを環境毎に分ける
今回の障害における一番の原因は、ビルド時にステージング環境と本番環境、2環境のECRにまとめてプッシュしていたことだと思う。
ステージングはステージング用のビルド、本番は本番用のビルド、のように環境毎にビルドを分けることが一番根本的な解決策のような気がする。
イメージのタグ付け
現在、ビルド時のイメージにタグ付けをしていないため、プッシュする度にlatestとなる。
タグ付けを工夫することで確実に不要なイメージだけが消えるような仕組みを作ることで、回避できそう。
なぜビルドをまとめてしまったのか
ビルドをステージングと本番環境で分けてしまうのが本事案の最も効果的な解決策だと思われる。
ただ、そもそもなぜビルド環境構築時にステージングと本番環境を分けずに作ってしまったのかを知らなければ、いつか同じミスを繰り返してしまうかもしれない。
ということで、そもそもなぜビルドを統一してしまったのかを深掘りしたい。
結論から言うと、ビルドを1つにまとめてしまった真相は分からない。
インフラ構築は前任のインフラ担当者が全て構築しており、前任者は本番稼働の前にチームを離れてしまった。
引継ぎはしたものの、各インフラ構成の「意図」までは聞いていなかったので、なぜこのような構成にしたのか、本当のところは分からない。
ということで、以下は私なりの推測になります。
可能性1. イメージプルのリクエスト制限緩和のため
ビルドのスクリプトは、ざっくり以下のような流れになっている。
- Docker Hubのアカウント認証
- ソースコードのクローン
- Dockerビルド
- ビルド時に、Docker Hubから公式イメージをプル
- ECRにイメージをプッシュ
ここで問題になるのは、Docker Hubからのイメージのプルの制限。
Docker Hubからのイメージプルは、匿名ユーザーの場合、あるいは、認証済みであっても無償アカウントの場合、ダウンロードできる数に制限がある。
ビルドの最初にDocker Hubのアカウント認証を行っているものの、こちらは無償アカウントであるため、無制限にはプルできない。
仮に、ステージング環境のみのビルドを実行した場合にプルの制限に引っかかってしまった場合、本番環境用のビルドがしばらくできなくなってしまうので、そのリスク回避のために、1回のプルで両環境にビルドをするようにした、という説が1つ。
とはいえ、この記事を書いている時点で無償アカウントの場合は6時間で200プルまで可能らしいので、対象システムのビルド頻度を考えるとステージングと本番環境を分けたところで制限にかかるリスクは低そうである。
可能性2. 環境差異を減らすため
ステージングと本番環境でビルドを独立した別々のものにした場合、ステージングへのビルドとデプロイをすっ飛ばして、本番環境のみへのビルド&デプロイができてしまう。
仮に本番環境にのみビルド&デプロイをしてエラーが起きてしまった場合に、開発が進んでいるとステージングで同じ環境を作ってエラーを再現するのが面倒になってしまう。
そのようなリスクを避けるたるためにステージングと本番環境で差異をなくそうとした、というのが2つ目の説。
ただ、ステージングをすっ飛ばして本番環境をデプロイするのは開発者のリテラシー的に問題ある気もするので、このようなリスクを考えてビルド環境を作る担当者はあまりいないような気もする。
可能性3. 特に理由はない
前任者の方が、今のビルド構成だと上記のようなエラーが起きる可能性を認識していたのかどうかは分からない。
正直、レアケースな障害のような気はしており、このような障害が起きることを認識していなかったのではないかという気がしている。
ステージング環境と本番環境でビルドスクリプトの中身が異なるのはプッシュ先のECRリポジトリくらいなので、スクリプトをまとめて簡潔に作りやすいこの形で作った、というのが真相な気もしている。
以上の3つが、私の中での説。
真相は分からないけれど、いずれにしても、エラー発生時の影響度を考えるとビルド環境を分けるメリットの方が大きである。
CodeBuildのビルドプロジェクトそのものを分けるのか、1つのビルドスペックの中で分岐するのか、環境毎にビルドを分ける方法は色々ありそうだが、やり方は何にせよ、どんなシステムであっても、複数環境が用意されている場合はビルドが分かれる仕組みを作る方が無難なように思う
まとめ
- ECSにアプリをデプロイしている場合、タスクの起動に失敗すると504エラーが発生する場合がある
- ECSのタスクで起動しているコンテナのイメージがECR上にないとタスク起動に失敗する
- 解決策としては、ECRライフサイクルの見直し、リリース頻度の見直し、ビルドプロセスに見直し、など