記事の対象読者
- 最低限Javaの知識がある
- WebアプリケーションのE2Eテスト自動化に興味がある人
動機
前職で関わっていた案件で本格的なTDD(テスト駆動開発)を経験し、その時にテストを自動化することのメリットやTDDのノウハウを学んだ。
現在関わっている案件は進め方がウォーターフォール的で、工程ごとにスケジュールが区切られている。
製造工程終了後にテスト期間がスケジュールされているため、テスト自動化が必須ではなかったが、ウォーターフォール型の開発スタイルでもTDDを実践するメリットはありそうだと感じたので、私が担当する機能においては部分的にTDDを取り入れて進めることにした。
私が以前関わっていたTDDの案件では、WebのテストをSelenideというJavaのフレームワークで実現していた。
今回の開発案件も言語がJavaだったので、環境構築が楽にできそうという理由からSelenideを使用することにした。
自分1人で何もない状態からE2Eテストの実行基盤を作ったのは初めてだったが、思ったよりも簡単にテスト自動化の環境を構築できたので、環境構築や基礎知識をまとめてJavaによるテストの自動化に興味がある人に向けて共有できればと思います。
この記事のゴール
- Selenideを使って簡単なブラウザ操作の自動化ができるようになること
本格的にE2Eテストを自動化しようと思うと、DB環境のセットアップを自動化する仕組みや、外部のAPIに対してモックを作成する必要出てくるが、この記事ではそのあたりは触れない。あくまでブラウザ操作による画面のテストができることを目指す内容とする。
また、単体テストの自動化についてもこの記事では言及しない。
※DBをセットアップする仕組みなどは別の機会に記事を作成できればと思いっています。
前提知識
E2Eテストを自動化するにあたって知っておくべき前提知識をざっとおさらい。
E2Eテスト
E2EはEnd-to-End略で、E2Eテストはユーザーが実際に使用することを想定したユースケースに対するテストのこと。
現場によっては結合テスト、システムテストなどと呼ばれることもあるかも。
この記事ではE2Eテストという呼び方で統一する。
テストの自動化
テスト自動化は、テストをプログラミング言語のコードで記述し、プログラムでテストを実現できるようにすること。
単体テストであればプログラミング言語ごとのxUnit系(JavaならJUnit、PHPならPHPUnitなど)のテスティングフレームワークを使うことが多い。
E2Eテストの場合、DB環境のセットアップやブラウザ操作(Webアプリの場合)をプログラムで制御して自動化する。
テストを自動化のメリットは色々あるが、リグレッションテストのコストを大幅に削減してデグレ防止しやすくなるのが大きなメリットの1つ。
TDD(テスト駆動開発)
ソフトウェア開発手法の一つで、アジャイル開発の文脈で登場することが多い開発手法。
実際に動くコード(プロダクションコード)より先にテストコードを書き、そのテストが成功するように実装をしていく開発手法。
一般には以下の手順で進める。
- 失敗するテストを書く
- テストが成功する最低限の実装をする
- リファクタリングする
- 1~3を繰り返す
一気に作ってまとめてテストするのではなく、あくまでのテストと実装を小さなサイクルを繰り返しながらイテレーティブに開発を進めていく。
TDDではテストコードが設計の役割も果たす形になる。
テストが成功する最低限のコードだけを実装していくため、余計なコードを書かずシンプルなコードにしやすくなる。
Selenium(セレニウム)
ブラウザ操作を自動化するためのツール、及びライブラリ。
様々なプログラミング言語でサポートされている。
Selenide(セレナイド)
Seleniumを拡張して作られたJavaのテスト用フレームワーク。
Seleniumを使用してテストするよりも使いやすくなっている。
Webアプリでは、非同期でデータを取得して画面に反映させることがよくある。
Seleniumを使ってテストを行う場合、非同期処理が終わっていないタイミングで検証の処理が走ると、データ取得が終わっていないことが原因でテストに失敗してしまう場合がある。
その場合、非同期処理が終わるまでの時間を考慮して待機時間を設けるなど、余計な制御をプログラムで実装する必要が出てしまう。
Selenideの場合、検証したい要素が見つからなかったとしても、一定時間は自動的にリトライしてくれる。そのため、待機時間などの余計な制御をあまり考慮せず、低コストでWebアプリのテストコードが書ける。
CSS セレクター
HTML要素を取得するための記述方法。
CSSでスタイルを適用する要素の指定や、JSでquerySelector, querySelectorAllなどのメソッドの引数として使用するもの。
例えば、id属性で要素を取得する場合は#id名、class属性の場合は.class名など。
Selenideでブラウザ操作する際にCSSセレクターを用いて要素を取得するので、CSSの最低限の知識が必要。
導入
ここからは環境構築。
SelenideはJavaのフレームワークなのでJava用の環境を構築する。
※テストコードはJavaで作成するが、テスト対象となるWebアプリケーションの開発言語は何でもよいです。プロダクトのコードベースとは別のコードベースとして作成するため、Webアプリの実装技術には依存しない。
導入手順の手順とする。
- Java実行環境を用意
- Mavenプロジェクトを作成(Gradleでも可)
- JUnitの依存関係を追加とテストディレクトリの作成
- Selenideの依存関係を追加
Javaの環境
Javaが実行できる環境(VS Code, Eclipse, IntelliJ IDEAなどのIDEを想定)があれば何でもよい。個人的に最近はIntelliJ IDEAを使う機会が多いので、この記事ではIntlliJ IDEAを想定して記載する。(ほかのIDEでも基本的に同じ手順でできるはずなので、適宜読み替えてください。)
Javaの環境がない場合は以下からCommunity版をダウンロードしてJavaのプログラムが実行できるようにしておく。
(JDKはプロジェクト作成時になければIntelliJ IDEA上からダウンロードできるので、別途用意する必要はない。)
※Ultimate版だと有償になるので注意。Ultimate版の下にCommunity版のダウンロードがある。
Mavenプロジェクトの作成
IDEでMavenプロジェクトを作成。
(※Gradleプロジェクトでもよいが、サンプルコードはMavenプロジェクトを前提に進める。Gradleの場合はpom.xmlをbuild.gradleのファイルに読み替えてください。)
以下を参考に適当に作成。
JUnitの導入
この記事ではE2Eテストを自動化するが、実行はJUnit上で実行する。
そのため、プロジェクトにJUnitを追加する。
pom.xmlに依存関係の追加し、テストコード用のディレクトリを作成する。
JUnitが正常に実行できるかも確かめておく。
以下を参考に。
Selenideの導入
以下のページを参照して依存関係(pom.xmlにdependency要素)を追加。
pom.xml
最終的にpom.xmlのdependenciesは以下のようになる。
※バージョンは記事執筆時点のものなので、適宜最新バージョンに読み替える。
<dependencies>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.11.0-M2</version>
</dependency>
<dependency>
<groupId>com.codeborne</groupId>
<artifactId>selenide</artifactId>
<version>7.5.0</version>
<scope>test</scope>
</dependency>
<!-- 以下略 -->
</dependencies>
環境構築はここまでで終了。
SelenideとTDD入門
ここからはステップ・バイ・ステップで簡単なWeb画面とともにテストコードを作成しながらSelenideの使い方を紹介する。
せっかくなのでTDDっぽくテストを作りながら少しずつ実装していく。
ゴール
この記事では以下のような簡単な計算ができるWebページの作成をゴールとする。
数値の入力項目2つと、演算子(+, -, *, /のいずれか)を選択できるプルダウンを用意する。計算ボタンを押すと、結果のエリアに計算結果が表示される。
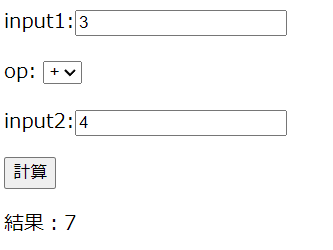
step1. HTMLの作成
まずはHTMLファイルを作成する。
ただし、今回はTDDの要領で進めていきたいので、まず中身の実装はせずに、ファイルだけを用意する。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Selenide-sample</title>
</head>
<body>
<!-- 中身は後から実装 -->
</body>
</html>
※なお、Webサーバー環境での構築はここでは扱いません。
手元で動かしながら試したい場合は、ローカルに適当なWebサーバー環境を用意し、作成したHTMLがhttp://localhostなどでアクセスできるよう適当に構築してください。
step2. Selenideのテストコード作成
ここからは実際にテストコードを作成する。テストもまずは最小限の状態で作成する。
完成系ではselect要素で演算子を選び、その演算子に対する演算結果を出力するが、ここではとりあえず演算子は無視してボタン押下で足し算結果が表示される想定でのテストを作成する。
testディレクトリの適当なパッケージに以下クラスを作成。
※パッケージ名などは環境に応じて適宜変更する。
package org.example;
import org.junit.jupiter.api.Test;
import static com.codeborne.selenide.Condition.exactText;
import static com.codeborne.selenide.Selenide.$;
import static com.codeborne.selenide.Selenide.open;
public class CalculationTest {
@Test
public void 足し算の結果が表示される() {
// 指定したURLでブラウザを開く
open("http://localhost");
// 要素を取得して値をセット
$("#num1").setValue("10"); // idの値がnum1の要素にvalue=10をセットする
$("#num2").setValue("20");
// 計算ボタンをクリック
$("#calc-btn").click();
// idがresultの要素のテキストが30になっているかの検証
$("#result").shouldHave(exactText("30"));
}
}
解説
動きとしては、1つ目のinput要素に10を入力し、2つ目のinput要素に20を入力する。
その後「計算」ボタンをクリックすることで結果の部分に30が表示されることを想定している。
Selenideクラスのopenメソッドは、引数にURLを渡すことで、新しいブラウザでその画面を起動する。
$メソッドは、引数にCSSセレクターを指定することで対象の要素を取得することができる。
ここでは各要素にid属性を指定する想定でidの値から要素を取得している。
今回はそれぞれの要素にid属性を指定する想定とし、#id名を指定して用を取得する。
id属性を付与する必要がないのであれば、name属性を使って、$("input[name='num1']")のように書くこともできる。
setValueメソッドでは、対象の要素のvalue属性に対して値をセットする。
clickメソッドは取得した要素にクリックの操作を行う。
shouldHaveはSelenideのアサーション機能で、対象の要素が引数で指定した状態になっているかどうかを検証する(この結果によってテストの合否が決まる)。
Condition#exactTextメソッドで、その要素のテキストが30と完全一致しているかどうかを検証する。
※shouldHaveメソッドはshouldBeメソッドの置き換えても同じ動作をします。
※exactTextメソッドは完全一致しているかどうかを表します。textメソッドを使用すると部分一致での検証もできます。
step3. テストの実行
テストコードを書いたら実行してみる。
IntelliJ IDEAで実行すると以下のような結果になる。
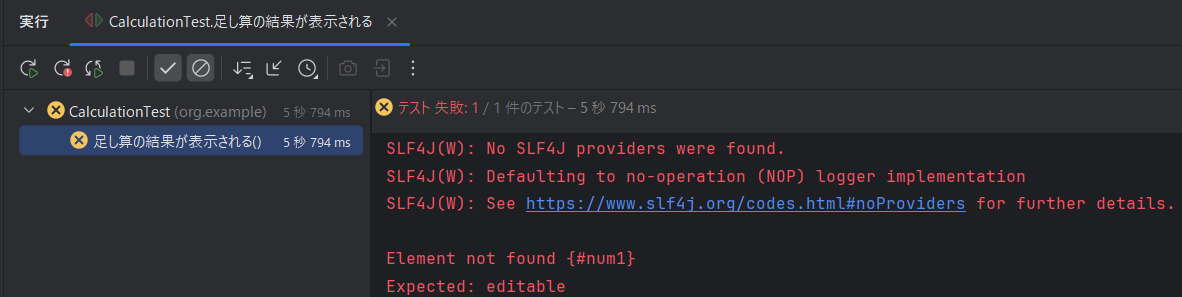
テストは失敗しており、原因はElement not found {#num1}とのことで、#num1の要素がないと言っている。
HTMLのbody部を何も作成していないため、テストが失敗するのは当然で、現状だと想定した通りの正しい挙動になる。
step4. HTMLのbody部を実装
テストコードをもとにHTMLの中身を作成する。
CSSやJavaScriptは本来別ファイルの方が良いかもしれないが、今回はSelenideの理解が目的なのでhtmlのファイル内にまとめて実装する。
とりあえず、ボタンが押されたらinput要素を取得し、足し算した結果が表示されるように簡単な実装を行う。
※詳細の解説は省略
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Selenide-sample</title>
<style>
form label, form button {
display: block;
margin-bottom: 1rem;
}
</style>
</head>
<body>
<form>
<label>
input1:<input id="num1" type="number">
</label>
<label>
input2:<input id="num2" type="number">
</label>
<button type="button" id="calc-btn">計算</button>
</form>
<div>
結果:<span id="result"></span>
</div>
<script>
'use strict';
document.getElementById('calc-btn').addEventListener('click', () => {
const num1 = document.getElementById('num1').value;
const num2 = document.getElementById('num2').value;
document.getElementById('result').innerHTML = num1 + num2;
})
</script>
</body>
</html>
step4. 再びテスト実行
画面を作成したので再びテストを実行する。
結果を見ると以下のようになった。
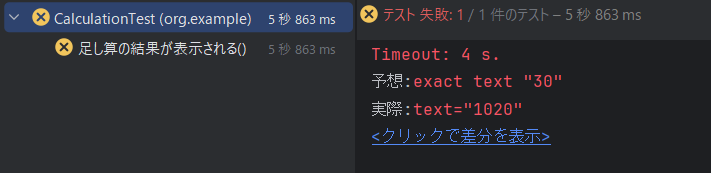
テストは失敗しており、30を予想していたが、実際には1020になっていたとのこと。
step5. 計算処理の修正
30を期待していたのに1020になっているということは、どうやら文字列として認識されて文字列結合されているように見える。
ということで、数値に変換して計算するようにJavaScript部分を修正する。
document.getElementById('calc-btn').addEventListener('click', () => {
const num1 = Number(document.getElementById('num1').value); // 数値に変換
const num2 = Number(document.getElementById('num2').value); // 数値に変換
document.getElementById('result').innerHTML = num1 + num2;
})
修正後に再度テストを実行すると、以下のようにテストに合格し、無事正常に動作した。
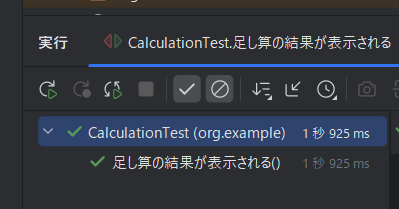
ブラウザ上で見ても以下のように正常に動作した。

step6. 演算子の追加
元々のゴールは演算子を選んで演算できるようにすることだったので、テストコードに演算子を選ぶ処理を追加する。
テストメソッドを以下のようにする。
@Test
public void 足し算の結果が表示される() {
open("http://localhost");
$("#num1").setValue("10");
$("#num2").setValue("20");
// 演算子を選択する
$("#operator").click(); // セレクトボックスをクリックする
$$("#operator option").find(text("+")).click(); // 「+」の選択肢をクリックする
$("#calc-btn").click();
$("#result").shouldHave(exactText("30"));
}
解説
ここでは新しく$$メソッドが登場。
$メソッドは、CSSセレクタで指定した要素を1つだけ取得する。
一方の$$メソッドは、指定したCSSセレクタに該当する要素全てを配列(厳密にはリスト)で取得する。
※JSのquerySelectorメソッドとquerySelectorAllメソッドの違いと同じ。
要素のindexを指定して$$("CSSセレクター").get(0)のようにも取得できるし、findメソッドで条件に合致する要素を絞って取得することも可能。
サンプルでは、複数あるoption要素の中でテキストに「+」が含まれる要素を取得してクリックし、選択された状態にしている。
step7. HTMLに演算子を追加
HTMLにselect要素を追加し、演算子を選べるようにする。
また、選んだ演算子によってその演算子で計算してもらうようにする。
ここでもまずは足し算の処理のみを実装しておく。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Selenide-sample</title>
<style>
form label, form button {
display: block;
margin-bottom: 1rem;
}
</style>
</head>
<body>
<form>
<label>
input1:<input id="num1" type="number">
</label>
<label>
op:
<select id="operator">
<option value="+">+</option>
<option value="-">-</option>
<option value="*">*</option>
<option value="/">/</option>
</select>
</label>
<label>
input2:<input id="num2" type="number">
</label>
<button type="button" id="calc-btn">計算</button>
</form>
<div>
結果:<span id="result"></span>
</div>
<script>
'use strict';
document.getElementById('calc-btn').addEventListener('click', () => {
const num1 = Number(document.getElementById('num1').value);
const num2 = Number(document.getElementById('num2').value);
// 演算子取得
const operator = document.getElementById('operator').value;
// 演算子毎の処理(とりあえず足し算のみ実装)
switch (operator) {
case '+' :
document.getElementById('result').innerHTML = num1 + num2;
break;
}
})
</script>
</body>
</html>
テストを実行すると正常に成功した。
※キャプチャは省略
step8. ほかの演算子のテストを作成する
足し算は正常に実行できたので、次は他の演算子の実装を行う。
次は引き算のテストメソッドを書く。
@Test
public void 引き算の結果が表示される() {
open("http://localhost");
$("#num1").setValue("10");
$("#num2").setValue("7");
$("#operator").click();
$$("#operator option").find(text("-")).click();
$("#calc-btn").click();
$("#result").shouldHave(exactText("3"));
}
テストコードを書き終えたらテストを実行し、失敗することを確かめる。
その後、テストが成功するようにHTML側を修正する。
ここまでくれば後は同じ。
他の演算子についても
- テストコード実装
- 失敗を確認
- HTMLを実装
- (リファクタリングできる箇所があれば)リファクタリング
の流れで進めていく。
Selenideの使い方まとめ
-
openメソッドでURLを指定してブラウザを起動できる -
$メソッドでCSSセレクターを指定して要素を取得できる -
$$メソッドで複数要素を配列で取得できる -
clickやsetValueなどのメソッドで要素を操作することができる -
shouldHaveやShouldBeで要素の状態を検証することができる
$メソッドで取得した要素はSelenideElementというクラスのオブジェクトとなっており、ほかにも様々な操作ができる。詳しくはSelenideの公式サイトや各クラスのリファレンスを参照ください。
Selenideの説明は一旦ここまで。
テストコードのドキュメント化
ここからはテストコードの書き方の話。
テストメソッドの認知負荷を下げる
個人的な意見だが、開発の設計ドキュメントは詳しく書きすぎない方が良い(最悪なくても良い)と思っている。
ドキュメントを詳細まで書きすぎてしまうと、仕様変更があった際にコードとドキュメントの両方を修正するのは非常にめんどくさく、メンテナンスコストが大きくなってしまう。
仮にコードとドキュメントに差異があった場合、どちらが正しいのか判断できずに無駄な確認作業が発生してしまう。
そのような理由から、設計ドキュメントは仕様変更があったとしても影響が少なくできる程度の記述量にした方が良いと思う。
同様の理由からコード内のコメントも必要以上に書かない方が良いと思っている。
ただ、システムを長期間運用する中で機能追加や改善が多く発生と予想される場合、テストが充実していた方が良いし、その場合テストコードがそのままドキュメントとして機能するのが理想であると思う(E2Eテストの場合は特に)。
とはいえ、上記のサンプルコードだとさすがにプログラム感が強く、ドキュメントと呼ぶには無理がある。
しかし、テストのステップ毎にメソッドを作成し、メソッド名を自然言語で定義すれば比較的認知しやすくなるのではないかと思う。
例えばこんな感じ。メソッド数は増えてしまうが、テストメソッドだけを見れば初見の人でも認知コストは低いと思われる。
@Test
public void 足し算の結果が表示される() {
トップページを開く();
数値の1つ目のを入力する(10);
数値の2つ目のを入力する(20);
演算子を選択する("+");
計算ボタンをクリックする();
計算結果を確認する(30);
}
private void トップページを開く() {
open("http://localhost");
}
private void 数値の1つ目のを入力する(int num) {
$("#num1").setValue(String.valueOf(num));
}
private void 数値の2つ目のを入力する(int num) {
$("#num2").setValue(String.valueOf(num));
}
private void 演算子を選択する(String operator) {
$("#operator").click(); // セレクトボックスをクリックする
$$("#operator option").find(text(operator)).click(); // 指定の演算子の選択肢をクリックする
}
private void 計算ボタンをクリックする() {
$("#calc-btn").click();
}
private void 計算結果を確認する(int result) {
$("#result").shouldHave(exactText(String.valueOf(result)));
}
Java 23の新機能
余談ですが、Java 23からJavaDocのコメントでマークダウンが使えるようになるという情報を見つけた。
JavaDocコメントをマークダウンとで書けるのは個人的には割と便利な機能じゃないかと思う。
マークダウンでテストシナリオを作成して、それをもとにAIにコードを生成させれば効率よく開発ができるのではないか。
- マークダウンのコメントでテストシナリオを記述
- コード生成AI(GitHub Copilotとか)でコメントからテストコードを生成
- テストを成功するようにコードを実装
- (ドキュメントが必要であれば)JavaDocとして出力したものをドキュメントとして扱う
こんな感じの流れで開発ができれば、かなり効率よく開発できそうな気がする。
テストメソッドのイメージはこんな感じでしょうか。
@Test
/// 足し算結果表示のテスト
///
/// - トップ画面を開く
/// - 1つ目の入力項目に"10"をセットする
/// - 2つ目の入力項目の"20"をセットする
/// - 演算子で"+"を選択する
/// - 計算ボタンをクリックする
/// - 結果に"30"と表示されている
public void 足し算の結果が表示される() {
open("http://localhost");
$("#num1").setValue("10");
$("#num2").setValue("20");
$("#operator").click();
$$("#operator option").find(text("+")).click();
$("#calc-btn").click();
$("#result").shouldHave(exactText("30"));
}
E2Eテスト自動化のメリット
リファクタリングへのハードルの低下
以前TDDで開発をしていたのはアジャイルの開発現場だったので、ウォーターフォールの開発でテストを自動化することにどれほどメリットがあるかは正直やってみるまでわからなかった。
実際にやってみると、ウォーターフォールの開発でもメリットはかなりあるなと感じた。
アジャイル開発の場合、細かくリリースを繰り返すという性質上、リグレッションテストを毎回手動で実施するのは現実的にコストがかかり過ぎるため、テストを自動化する方が明らかに合理的である。
ウォーターフォールの場合は一通りの機能を作り切ってからのリリースになるので、初めはアジャイルな開発に比べるとテストを自動化するメリットは少ないかもしれないとも思った。
しかし、リリースをしないとしても、開発期間中に自分が以前作ったコードをリファクタリングしたくなる場面は多くあった。
そのような時に、テストが自動化されていることでリファクタリングすることの心理的ハードルがグッと少なくなった。
テストがない状態だと、リファクタリングをしようと思うと影響範囲がどこまで及ぶのかを調査して、修正した後も一通りの機能を手動で確認する必要がある。
仮にテストがなかったとしたら、リファクタリングすることの負担と、リファクタリングすることのメリットを比較して、結局リファクタリングしないまま放置するケースも多くあったのではないかと思う。
しかし、テストがあればリファクタリング実施後にテストを実行すれば影響範囲がすぐにわかるため、コードを修正することの心理的な抵抗があまりなかった。
結果、ウォーターフォールの開発でもテストを自動化することでコードをきれいに保ちやすくなった。
開発速度が上がった
TDDのスタンスで開発をしていると、実際のコードとは別でテストコードも書かないといけないため、開発速度は低下すると思うかもしれない。
確かに、テストコードを書いている分開発工数が増えた部分はあるかと思うし、SelenideやCSSセレクターに慣れていない場合は学習コストもかかってしまう。
しかし、私の場合は機能によってはテストを書いておくことで開発速度が上がった部分もあった。
例えば、DBに更新を行うような機能。
普通に開発しようと思うと、テスト用のデータを手動で用意し、画面を動かした後にDBを確認して結果を確かめる。
その際、不具合があってデバッグが必要な場合はデータを手動で何度も修正しながらプログラムも修正していく必要がある。
TDDで開発をする場合、(今回は触れてないが)テストを実行するたびにDBの状態をリセットするようにしていたので、デバッグする際にDBを直接修正する必要がなく、結果的に開発速度が上がったように思う。
単体テストとE2Eテスト
この記事ではE2Eテストの自動化に焦点を当てて単体テストについては触れなかったが、TDDを本格的に導入しようと思うと、テストの割合としてはE2Eテストよりも単体テストの方を多くした方が良いとされている。
テストコードもプロダクションコードと同じように中長期的にメンテナンスしていく場合、E2Eテストで全てのパターンを網羅するのが良いわけではないということ。
E2Eテスト自動化を導入る場合は、そのことを念頭においてどこまでのパターンをE2Eテストとして自動化するか検討すると良いかと思う。
全体のまとめ
- E2Eテストは実際のユーザーの操作を想定したテスト
- TDD(テスト駆動開発)は、テストコードを先に書き、ステップバイステップで実装を進めていく開発手法
- Seleniumはブラウザを自動で操作する技術
- SelenideはSeleniumを拡張したJavaのテスト用フレームワーク
- テストコードを開発の設計ドキュメントに近づけるのが(個人的な)理想
- ウォーターフォールでもTDDはメリットが大きい
- リファクタリングへのハードルの低下
- (機能によっては)開発速度が向上する
- 本格的にTDDを導入する場合はE2Eのテストコードよりも単体テストのテストコードの割合を増やした方が良い
機会があればこの記事を引き継いだ形でDB周りのセットアップやアサートなどの記事もかければと思います。