概要
webサービスを公開するにあたって必ず使われることになるのがブラウザです。ブラウザがユーザーにwebページを表示する仕組みを理解することで、フロントエンド開発に役立てたり、ページ表示までのレスポンスの改善などに役立てていきたいと思い、今回ブラウザのレンダリングの仕組みの基本事項についてまとめました。
レンダリングの流れ
ユーザーがwebブラウザにURLを入力すると、ブラウザはURLを元に指定のサーバーにTCP/IPプロトコルに基づいてリクエストを送ります。その後サーバはクライアントに対してレスポンスします。以降のレスポンスとして受け取るHTML,CSS,Javascriptをどう処理して画面に表示するのかをレンダリングと定義して、その処理の流れについてみていきます。(この工程はcritical rendering pathと呼ばれています)
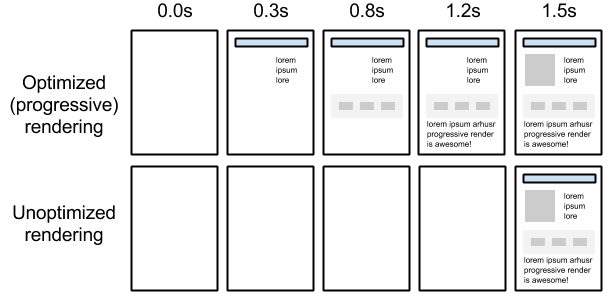

ブラウザがWebページをレンダリングする仕組みは上のような一連の流れになっています。以下でその一つ一つの工程の内容をみていきます。
オブジェクトモデルの構築
ブラウザはページを描画する前に、DOMとCSSOMツリーを構築する必要があります。
このDOMとCSSOMツリーを構築する工程は「オブジェクト構築モデル」といいます。
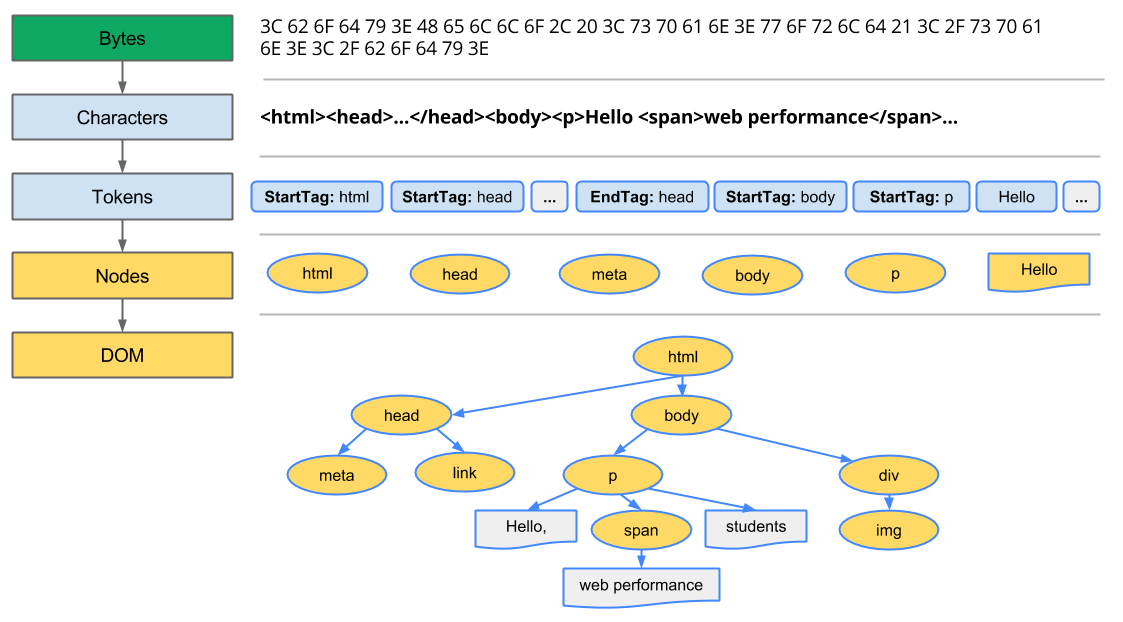
バイト→文字列→トークン→ノード→オブジェクトモデル(DOM/CSSOM)
という流れでオブジェクトモデルは構築されます。
DOMツリーの構築
変換
ブラウザはディスクやネットワークからHTMLのバイトを読み取り、utf8などの文字コードに応じて<html>や<head>のような文字列に変換します
トークン化
取得した文字列をトークンに変換します。W3C HTML5 standardによって規則が定められています。

字句解析
トークンは<html>や<head>といったオブジェクトに変換されます。

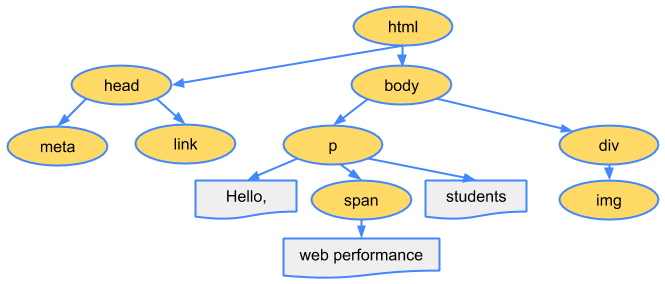
DOMの構築
字句解析で作られたオブジェクトはオリジナルのマークアップの定義に基づいた親子関係をもつ木構造に整形されます。
<html>オブジェクトは<body>オブジェクトの親で、<body>は<p>の親でといったようなHTMLのマークアップでみる構成になります。
この最後のプロセスの最終的な成果物が描画するページのDOMとなります。
CSSOMツリーの構築
ブラウザでDOMを構築している際にドキュメントのheadタグで外部のcssスタイルシートを参照しているlinkタグに遭遇すると、ブラウザはページのレンダリングにこのリソースが必要であると解釈してこのリソースに対するリクエストを即座にディスパッチし、CSSを受け取ります。
ブラウザがCSSを解釈して処理できるようにするために、受けとったCSSをHTMLのDOMツリー構築の時と同じように処理していきます。
レンダリングツリーの構築
DOMツリーとCSSOMツリーを組み合わせることでレンダーツリーを作ります。レンダーツリーは個々の要素のレイアウトの計算し、またピクセルを画面に描画するプロセスである「ペイント」の工程が必要とする値を生成します。
レンダーツリーの生成
DOMツリーとCSSOMツリーを合成してレンダーツリーを生成します。ページの描画に使われる全てのDOMと個々のオブジェクトに使われるCSSをそれぞれ組み合わせます。
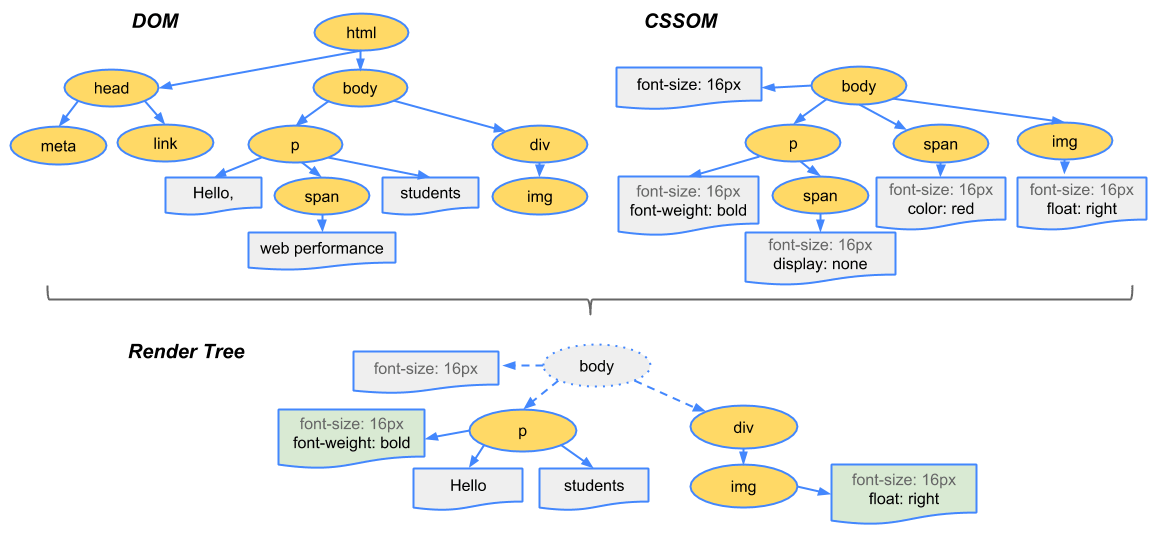
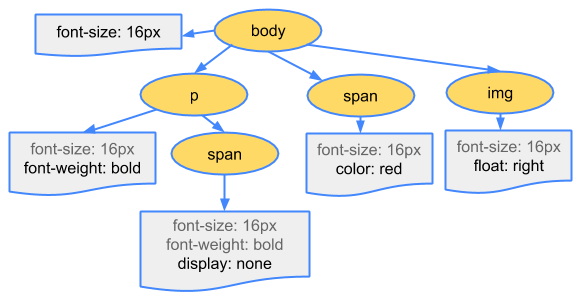
レンダーツリーを構築するために、ブラウザは大まかに以下の工程に従います
-
DOMツリーのルートからはじめて、個々のノードをトラバースしていきます
- scriptタグなど画面の描画に直接関係ないいくつかのノードは除かれます
- いくつかのノードはCSSにより
display noneなどど非表示に指定されたものも除かれます(上の図の例でいうと<span>にあたります
-
それぞれのノードに対応したCSSOMをみつけて適用します
-
CSSが適用された表示可能になったノードを除きます
これらの工程によりページの描画に必要な全てのノードとスタイル情報を含んだレンダツリーが作成されます。
レイアウト
レンダリングツリーの構築まででどの要素が描画されてどんなスタイルが適用されるかが決まりました。この次に、デバイスのviewport内でそれら要素の厳密な位置やサイズを算出するレイアウトの工程が行われます(リフローとも言われます)
ページ上での個々の要素の正確なサイズや位置を求めるために、レンダーツリーのルートからブラウザはトラバースします。
ex)
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>
上のページのコンテンツは2つのネスとされたdiv要素をもち、最初のdivはviewportの横幅の50%に位置し、2つ目のdivは親要素のdivの50%の位置となります。

レイアウトプロセスで出力されるものを「ボックスモデル」といいます。ボックスモデルはviewport内での個々の要素の正確な位置とサイズを算出し、相対的な値を画面上でのピクセルの絶対値に変換します。
ペイント
最後に、レイアウトプロセスで得ることができた個々の要素のサイズと位置情報を最終的な正確なピクセル値へと変えるペイント(又はラスタライゼイション)の行程が行われます
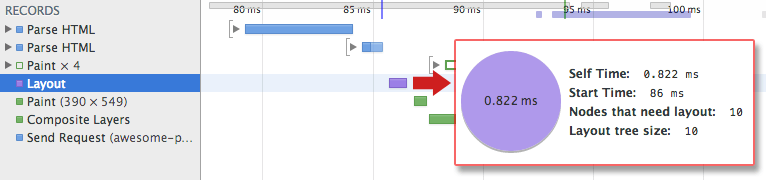
【Chrome DevToolsでの処理の経過の様子】
https://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction
レンダーツリーの構築、レイアウト、そしてペイントの各工程に要する時間はドキュメントのサイズ、適用されたスタイルそしてデバイスによって様々です。
それぞれの工程の合計時間を最小化することでクリティカルレンダリングパスを最適化することができます。
その他
レンダリングエンジンとJavaScriptエンジン
ブラウザにはレンダリングエンジンとJavaScriptエンジンという2つのエンジンが動作しています。
レンダリングエンジン
HTMLやCSSなどを解析し、実際の画面に描画するためのもの。
レンダリングエンジンによってHTMLやCSSの解釈に差があるためデザインがブラウザによって崩れるという問題があります。
JavaScriptエンジン
JavaScriptを実行するためのエンジン。
【主なブラウザと各種エンジン】
| ブラウザ | レンダリングエンジン | JavaScriptエンジン |
|---|---|---|
| Google Chrome | Blink | V8 |
| Safari | Webkit | Nitro |
| IE | Trident | Chakra |
| Microsoft Edge | Blink | V8 |
| Mozilla Firefox | Gecko | SpiderMonkey |
| Opera | Blink | V8 |
Microsoft Edgeの新しいversion(Chromiumベース)が来年の1月15日にリリース予定です。
https://forest.watch.impress.co.jp/docs/news/1216492.html
まとめ
ブラウザレンダリングの仕組みを各工程ごとにみることで、ページライフサイクルのイベントがどの工程で発生するのかをきちんと理解できるようになりました。レンダリングの仕組みの知識を元に、ブラウザの開発ツールを駆使して開発時にデバッグやパフォーマンスのボトルネックの分析、改善に役立てていきたいと思います。