前文
実務の現場でもしばしば見かけ、困惑させられるクエリが以下のようなもの。
FROM TABLE_A
INNER JOIN (
SELECT * FROM TABLE_B WHERE col2 = 100
) B
ON TABLE_A.col1 = B.col1
何故わざわざサブクエリを使うのか。これは以下と同等であり、その方が記述もすっきりする。
FROM TABLE_A
INNER JOIN TABLE_B
ON TABLE_A.col1 = TABLE_B.col1
AND TABLE_B.col2 = 100
集約(GROUP BY)等を行っていない、単純な SELECT文を内包するサブクエリの結合はテーブル同士の直接結合と同じであり、サブクエリ化する必然性などない。
それなのに、わざわざサブクエリを使用して書く人は、まずTABLE_Bを絞り込み、それからTABLE_Aと結合した方が速い、という考えに基づいているらしい。
アルゴリズムとしては正しい。しかし、この場合に限って言えばそれは徒労。
結論をまず書いてしまうと、明示的に絞り込む形で記述しなくても、オプティマイザが自動で判断しそう処理してくれるから。
サブクエリの副作用
それよりも気になるのは、速度を気にする割にはサブクエリのコストは考えないのか、という点。
サブクエリはインデックスが利かないという副作用がある。勿論サブクエリの中のクエリは単なるSELECT文なので、インデックスが設定されていれば作用する。しかしサブクエリとしてパッケージされた物に対して外から見てインデックスは機能しない。
ON句で指定される列が、元のテーブルではインデックスが設定されていも、サブクエリの外には引き継がれない。
何故なら、サブクエリ(や共通テーブル式)はローカルのビューとも言えるから。ビューはインデックスが利かない。
折角絞り込むように明示的にクエリを書いても、サブクエリによってインデックスが利かなくなったら本末転倒。結合処理がやばたにえんで、結果として逆に遅くなるのでは、という考え方もできる。(実はこれも杞憂なのだが)
ビューに関してはマテリアライズドビューのようなインデックスが利くタイプのものが拡張機能として追加さている DB も多いとか、SQL Serverならテーブル値関数という鼻血が出るほど便利な仕組み、ビューの代替が用意されているとか、話すと長いので割愛。
サブクエリに話を戻す。
サブクエリが必ず遅いとは限らない。例えばサブクエリを使用した結合で典型的なケースの一つが、集約した結果の結合。
FROM TABLE_A
INNER JOIN (
SELECT col1, col2 FROM TABLE_B GROUP BY col1, col2
) B
ON TABLE_A.col1 = B.col2
そのような仕様を実装する場合、集約を直接結合することはできない。何故ならテーブル結合の構文にそのような物は無いから。
サブクエリ内で集約しその結果を結合するしかない。これは必要なサブクエリ。
そして集約の性質上、サブクエリ内のレコード数は少ないことが期待できる。
そうであれば結合はオンメモリで行われるだろうし、ハッシュ結合等で高速に処理されることが期待できる。
というかオンメモリで行われる程度の量であれば、今時のコンピュータなら何でもない。
問題はサブクエリ内のレコードがオンメモリ処理できないような量である場合。
そうなると内部的には一時テーブルが作られ、そこにサブクエリの結果が流し込まれ、その一時テーブルを使用した結合が行われる。この時、一時テーブルに自動で最適なインデックスも設定される、などという虫の良いことは行われない。
それなりの量のレコードを持った、インデックスが設定されていないテーブルを結合しようとしたら、そりゃ遅いわなという当たり前の話。
だから、サブクエリがボトルネックとなっているクエリの場合、手動で一時テーブルを作成し、結合が高速で行われるようにインデックスも設定した上で一時テーブルにサブクエリの中身を流し込む。
そして、その一時テーブルをクエリ本体では結合を行う、という手法がチューニングの定番の一つとなっている。
実際、そうしたチューニングを行い、見違えるほどスピードが改善され感動した、という人も多いのでは。
因みに細かい話として、
1. 一時テーブル作成(インデックスも設定)
2. 一時テーブルにレコード投入
より、以下の方が速いとされている。
1. 一時テーブル作成
2. 一時テーブルにレコード投入
3. 一時テーブルにインデックス設定
前者はレコード追加毎にインデックスの再作成が発生するが、後者は最後にまとめてドンでインデックスを作成しているから。
というノウハウもセオリーとしてあるが、これについては個人的な経験則として、速度は変わらない場合が殆どという印象。
速度に変化が現れるかどうかは、レコード量や設定するインデックスに依存すると思われ。
ただ、速くなる場合は確かにあるので、一応気を付けておいた方が賢明。
また、こうした話をすると、サブクエリ内がどれぐらいの量(レコード数)でパフォーマンスの低下が発生するのか、と聞いてくる人がいる。閾値はどれぐらいなのか、ですな。
しかし、一般論として数字を挙げるのは無理っしょ。
何故なら、それは DBサーバのメモリの搭載量(DBエンジンが使用することが可能なメモリ量)や、取得するテーブルのレコード長に依存するから。ケースバイケースとしか言いようがない。
だから、あるハードウェア環境では高速に動作するクエリでも、別の環境では遅いことも当然あり得るし、そもそもそこまで言い出したら DB自体のチューニングも関わってくる。だから DB って難しい。
やっと本題
話が大きく逸れたが、サブクエリはボトルネックとなる可能性があるので、特別な理由がない限りは使用しないことが望ましい。
安直にサブクエリを使う人はそこら辺を分かっているのかな、という話。
しかし、冒頭で取り上げた例では、実はサブクエリの問題は発生しない。
実際に動かし実行プランを確認していく。
環境
| SQLServer | SQLCMD | SSMS |
|---|---|---|
| 2017 | 14.0.1000.169 | v18.2 |
| 各種設定はデフォルト。 |
絞り込みクエリ
FROM句で指定するテーブルはfrom_table、結合するテーブルはjoin_tableとして作成。
IF OBJECT_ID (N'dbo.from_table', N'U') IS NOT NULL
DROP TABLE dbo.from_table;
GO
CREATE TABLE from_table (
key1 int
, val varchar(10)
, CONSTRAINT PK_from_table PRIMARY KEY CLUSTERED (key1)
);
GO
IF OBJECT_ID (N'dbo.join_table', N'U') IS NOT NULL
DROP TABLE dbo.join_table;
GO
CREATE TABLE join_table (
key1 int
, key2 int
, val varchar(10)
, CONSTRAINT PK_join_table PRIMARY KEY CLUSTERED (key1, key2)
);
GO
両テーブルに 100,000レコード投入。
;WITH cte_asci(seq, n) AS (
SELECT 1, 65
UNION ALL
SELECT seq + 1, IIF(n = 90, 65, n + 1) FROM cte_asci
WHERE seq < 100000
)
INSERT INTO from_table
SELECT seq, CHAR(n) FROM cte_asci
OPTION (MAXRECURSION 0)
;
;WITH cte_asci(seq, n) AS (
SELECT 1, 97
UNION ALL
SELECT seq + 1, IIF(n = 122, 97, n + 1) FROM cte_asci
WHERE seq < 100000
)
INSERT INTO join_table
SELECT (seq - 1) / 3 + 1, (seq - 1) % 3 + 1, CHAR(n) FROM cte_asci
OPTION (MAXRECURSION 0)
;
GO
以下 4種類の検証クエリを実行し、実行プランを表示、確認する。
1. 今回問題としてるサブクエリを使用した結合
2. サブクエリを使用しない通常の結合
3. 2.の ON句で指定している定数は WHERE句で指定しても同等というクエリ
4. 一旦積結合してからの WHERE句での絞り込み
SET SHOWPLAN_TEXT ON;
GO
-- 1. サブクエリ結合
SELECT *
FROM from_table
INNER JOIN (
SELECT * FROM join_table WHERE key1 = 10000
) t
ON from_table.key1 = t.key2
;
-- 2. 素直にテーブル結合
SELECT *
FROM from_table
INNER JOIN join_table
ON join_table.key1 = 10000
AND join_table.key2 = from_table.key1
;
-- 3. WHERE句で絞り込み
SELECT *
FROM from_table
INNER JOIN join_table
ON join_table.key2 = from_table.key1
WHERE join_table.key1 = 10000
;
-- 4. 積結合を WHERE句で絞り込み
SELECT *
FROM from_table
CROSS JOIN join_table
WHERE join_table.key1 = 10000
AND join_table.key2 = from_table.key1
;
GO
SET SHOWPLAN_TEXT OFF;
GO
取得されるデータ構成は以下。
-
join_tableテーブル 100,000レコードの内、key1 = 10000を満たすのは 3レコード - 結合結果も 3レコード
1> SELECT * FROM join_table WHERE key1 = 10000;
2> GO
key1 key2 val
----------- ----------- ----------
10000 1 t
10000 2 u
10000 3 v
(3 行処理されました)
1>
2> SELECT *
3> FROM from_table
4> INNER JOIN (
5> SELECT * FROM join_table WHERE key1 = 10000
6> ) t
7> ON from_table.key1 = t.key2
8> ;
9> GO
key1 val key1 key2 val
----------- ---------- ----------- ----------- ----------
1 A 10000 1 t
2 B 10000 2 u
3 C 10000 3 v
(3 行処理されました)
前述 4種類の検証クエリ実行結果は以下。
StmtText
--------------------------------------------------------------------------------------------------------------------------------------
SELECT *
FROM from_table
INNER JOIN (
SELECT * FROM join_table WHERE key1 = 10000
) t
ON from_table.key1 = t.key2
;
(1 行処理されました)
StmtText
----------------------------------------------------------------------------------------------------------------------------------------------------
|--Hash Match(Inner Join, HASH:([MyDB].[dbo].[join_table].[key2])=([MyDB].[dbo].[from_table].[key1]))
|--Clustered Index Seek(OBJECT:([MyDB].[dbo].[join_table].[PK_join_table]), SEEK:([MyDB].[dbo].[join_table].[key1]=(10000)) ORDERED FORWARD)
|--Table Scan(OBJECT:([MyDB].[dbo].[from_table]))
(3 行処理されました)
StmtText
------------------------------------------------------------------------------------------------------------------------------------
SELECT *
FROM from_table
INNER JOIN join_table
ON join_table.key1 = 10000
AND join_table.key2 = from_table.key1
;
(1 行処理されました)
StmtText
----------------------------------------------------------------------------------------------------------------------------------------------------
|--Hash Match(Inner Join, HASH:([MyDB].[dbo].[join_table].[key2])=([MyDB].[dbo].[from_table].[key1]))
|--Clustered Index Seek(OBJECT:([MyDB].[dbo].[join_table].[PK_join_table]), SEEK:([MyDB].[dbo].[join_table].[key1]=(10000)) ORDERED FORWARD)
|--Table Scan(OBJECT:([MyDB].[dbo].[from_table]))
(3 行処理されました)
StmtText
------------------------------------------------------------------------------------------------------------------------------------
SELECT *
FROM from_table
INNER JOIN join_table
ON join_table.key2 = from_table.key1
WHERE join_table.key1 = 10000
;
(1 行処理されました)
StmtText
----------------------------------------------------------------------------------------------------------------------------------------------------
|--Hash Match(Inner Join, HASH:([MyDB].[dbo].[join_table].[key2])=([MyDB].[dbo].[from_table].[key1]))
|--Clustered Index Seek(OBJECT:([MyDB].[dbo].[join_table].[PK_join_table]), SEEK:([MyDB].[dbo].[join_table].[key1]=(10000)) ORDERED FORWARD)
|--Table Scan(OBJECT:([MyDB].[dbo].[from_table]))
(3 行処理されました)
StmtText
----------------------------------------------------------------------------------------------------------------------------------
SELECT *
FROM from_table
CROSS JOIN join_table
WHERE join_table.key1 = 10000
AND join_table.key2 = from_table.key1
;
(1 行処理されました)
StmtText
----------------------------------------------------------------------------------------------------------------------------------------------------
|--Hash Match(Inner Join, HASH:([MyDB].[dbo].[join_table].[key2])=([MyDB].[dbo].[from_table].[key1]))
|--Clustered Index Seek(OBJECT:([MyDB].[dbo].[join_table].[PK_join_table]), SEEK:([MyDB].[dbo].[join_table].[key1]=(10000)) ORDERED FORWARD)
|--Table Scan(OBJECT:([MyDB].[dbo].[from_table]))
(3 行処理されました)
完全に一致。
どうクエリを書こうが、[MyDB].[dbo].[join_table].[key1]=(10000)で絞り込んだ上でHash Match(Inner Join~を行っている模様。
詳細を表示したい場合はSET SHOWPLAN_ALL ON;だが、CUI環境では見辛いので SSMS上で確認。
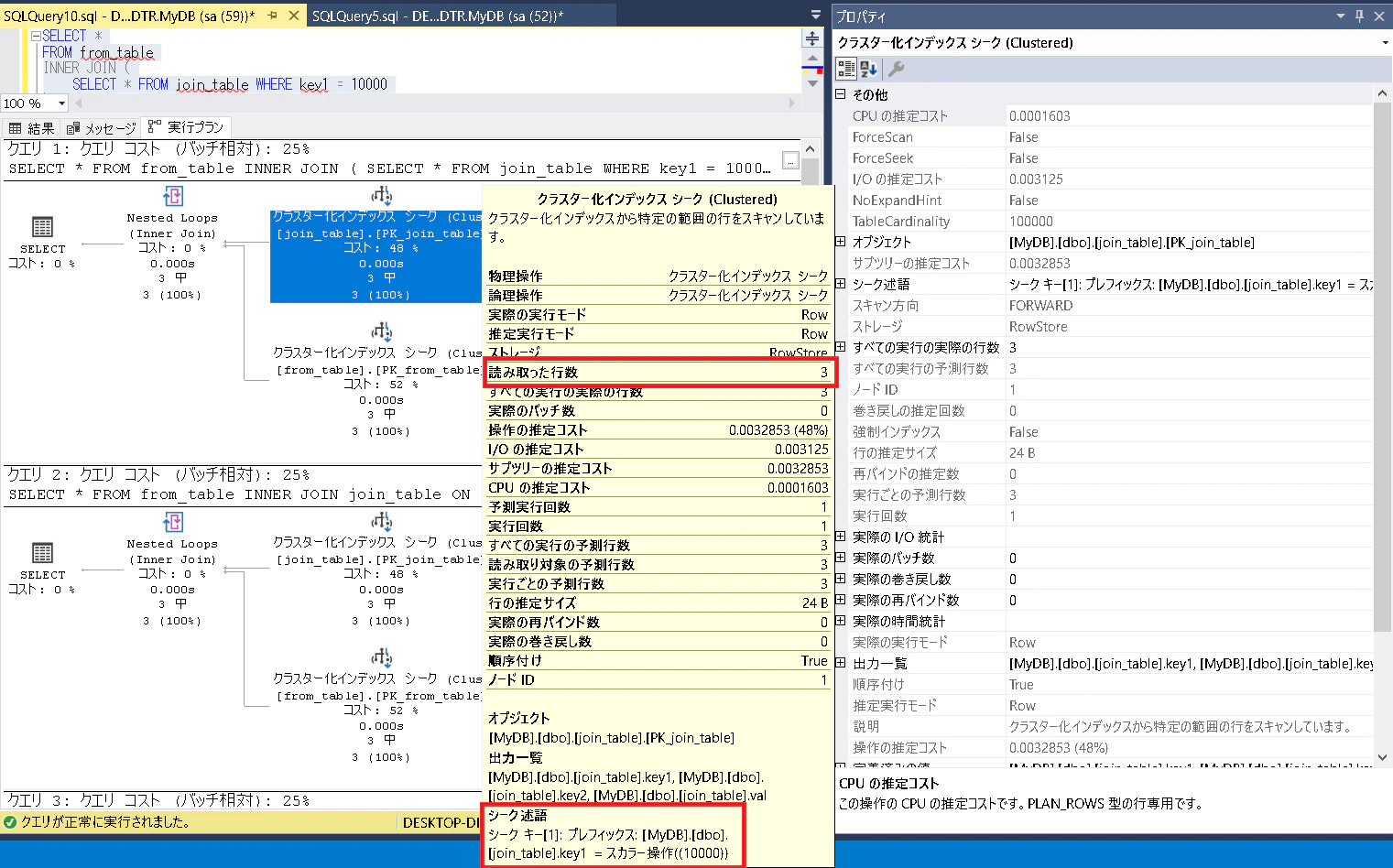
key1=10000で 3レコードに絞り込んだ上で結合していることが分かる。
つまり、わざわざサブクエリを使用して絞り込まなくても、普通にテーブル結合するだけでも、オプティマイザが自動で判断し絞り込みを行った上で結合してくれる。
また興味深いのが、3、4番目のクエリ。
3番目はクエリ上でみれば、まずINNER JOINで結合した上でWHERE句で絞り込む。
4番目は積結合(総当たりで結合)した上で、WHERE句で結合条件に合致し、且つ、key1=10000を満たすレコードを絞り込む。
であるが、いずれも実際は先に絞り込みを行っていることになる。
そもそも 4番目はまず馬鹿正直に積結合を行うと 100,000 × 100,000 = 10,000,000,000、100億レコードが生成されてしまうことになる。これはやばたにえん。積結合は爆発的にレコード数が増加するからね。
もはや COUNT句では算術オーバーフロー エラーが発生するレベル。
1> SELECT COUNT(from_table.key1)
2> FROM from_table
3> CROSS JOIN join_table
4> ;
5> GO
メッセージ 8115、レベル 16、状態 2、サーバー *******-*******、行 1
expression をデータ型 int に変換中に、算術オーバーフロー エラーが発生しました。
COUNT_BIGならいけた。
1> SELECT COUNT_BIG(from_table.key1)
2> FROM from_table
3> CROSS JOIN join_table
4> ;
5> GO
--------------------
10000000000
(1 行処理されました)
テーブル結合を行う時、事前にレコードを絞り込むことができればその方が効率的であることは自明であり、オプティマイザはそれを選択してくれると。
つまり、クエリとしてどう書かれているか、ではなく、結果としてどうしたいかを元にクエリを最適化しれくれるということが分かる。
但し、これはSQL Server上での検証結果であり、DB によっては動作が異なることも十分あり得ることに注意。
IN句最適化の嘘と本当
クエリのパフォーマンスチューニングでぐぐるとよく出てくるのがIN句の最適化。
例えば、WHERE句で指定する条件が<列> IN (1, 3, 9)で、以下のようにデータ構成に偏りがある場合。

この場合、出現頻度が高い順に、<列> IN (9, 3, 1)と指定した方が速い、という理屈。
更に言えば、IN句は(<列> = 9 OR <列> = 3 OR <列> = 1)と展開されるので、出現頻度が高いものから突合した方がヒット率が上がり速いと。
一見もっともらしい理屈だが、実際のところどうか。
前節で使用した検証テーブルを流用する。確認クエリは以下。IN句はIN (9999, 9998, 9977, 9, 8, 7)としている。
SET SHOWPLAN_TEXT ON;
GO
SELECT *
FROM from_table
WHERE key1 IN (9999, 9998, 9977, 9, 8, 7)
;
GO
SET SHOWPLAN_TEXT OFF;
GO
実行結果は以下。PK(インデックス)あり、なしの 2パターンで確認した。
-- PKあり
StmtText
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|--Clustered Index Seek(OBJECT:([MyDB].[dbo].[from_table].[PK_from_table]), SEEK:([MyDB].[dbo].[from_table].[key1]=(7) OR [MyDB].[dbo].[from_table].[key1]=(8) OR [MyDB].[dbo].[from_table].[key1]=(9) OR [MyDB].[dbo].[from_table].[key1]=(9977) OR [MyDB].[dbo].[from_table].[key1]=(9998) OR [MyDB].[dbo].[from_table].[key1]=(9999)) ORDERED FORWARD)
(1 行処理されました)
-- PKなし
StmtText
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|--Table Scan(OBJECT:([MyDB].[dbo].[from_table]), WHERE:([MyDB].[dbo].[from_table].[key1]=(7) OR [MyDB].[dbo].[from_table].[key1]=(8) OR [MyDB].[dbo].[from_table].[key1]=(9) OR [MyDB].[dbo].[from_table].[key1]=(9977) OR [MyDB].[dbo].[from_table].[key1]=(9998) OR [MyDB].[dbo].[from_table].[key1]=(9999)))
(1 行処理されました)
インデックスが設定されていればClustered Index Seekが実行されることから、SQL ServerではIN句でもインデックスが有効であることが分かる。
余計な修飾が多くて見辛いので整理するとそれぞれ以下。
-- PKあり
SEEK:(key1=7 OR key1=8 OR key1=9 OR key1=9977 OR key1=9998 OR key1=9999)
-- PKなし
WHERE:(key1=7 OR key1=8 OR key1=9 OR key1=9977 OR key1=9998 OR key1=9999)
IN句で指定された要素は昇順でソートされた上で OR で連結していることが分かる。
B-tree等の探索アルゴリズムでは、データの並び順をソートする必要がある。探索アルゴリズムを見たらソートと思えという格言もある(嘘)。
SQL ServerのIN句展開でソートする仕様も、採用している探索アルゴリズム上、必要なものと考えられる。実際のところどうなのかは内部処理の話なので想像の域を出ないが。
何にしても、そのような仕様である以上、IN句で指定する要素の順番を意識して指定することは無意味である。というか、素直に最初から昇順で書いた方がソート処理も軽くなるという理屈も成り立つ。(計測が不可能なレベルの差でしかないだろうけど)
そもそも、IN句で指定する要素の並び順で速度が変わる場合とは、IN句そのものが遅いということであり、インデックスが効いていればそんなことは起こりにくい。
つまり、インデックスが設定されていないか、そもそもIN句にインデックスが効かない仕様の DB では。
昔のOracleのIN句ではインデックスが利かなかったそうで、IN句を分解し、UNION ALLで結合する等々、今となっては冗談としか思えないようなテクニックもあったらしい。
IN句で指定する要素の並び順を最適化する、というテクニックも、そうした前時代的な化石と考えた方が良さそう。
少なくともSQL Serverでは無意味。そう、クエリは書いた通りに動くとは限らない。