Day3
最終日!
自分用参加・聴講メモ
※Keynoteは省略
Handling Risky Business: Cluster Upgrades
Lyftのクラスタ自動アップグレードの話
2017年からK8sを調査・構築して、2018年にはレガシーシステムを移行開始、2019年に(K8sが)急成長
OSセキュリティパッチ, バグフィックス, 機能追加などでK8sのバージョンアップは避けられない
目指すのはp95,99 latencyやCluster Healthなどを守ったアップグレード
(ということは、zero-downtimeは前提のようだ)
次のような流れでコード化して、クラスタ更新を自動化する
do
while
!is_cluster_updated() and
cluster_is_healthy() {
NODE = get_old_node()
kubectl cordon NODE
kubectl drain NODE
kubectl delete NODE
terminate(NODE)
}
それで作ったのがk8srotator(最初はv0)
GO言語で実装したOperator
FleezeとRotateの状態をもつ
Fleezeはクラスタアップグレードを停止する
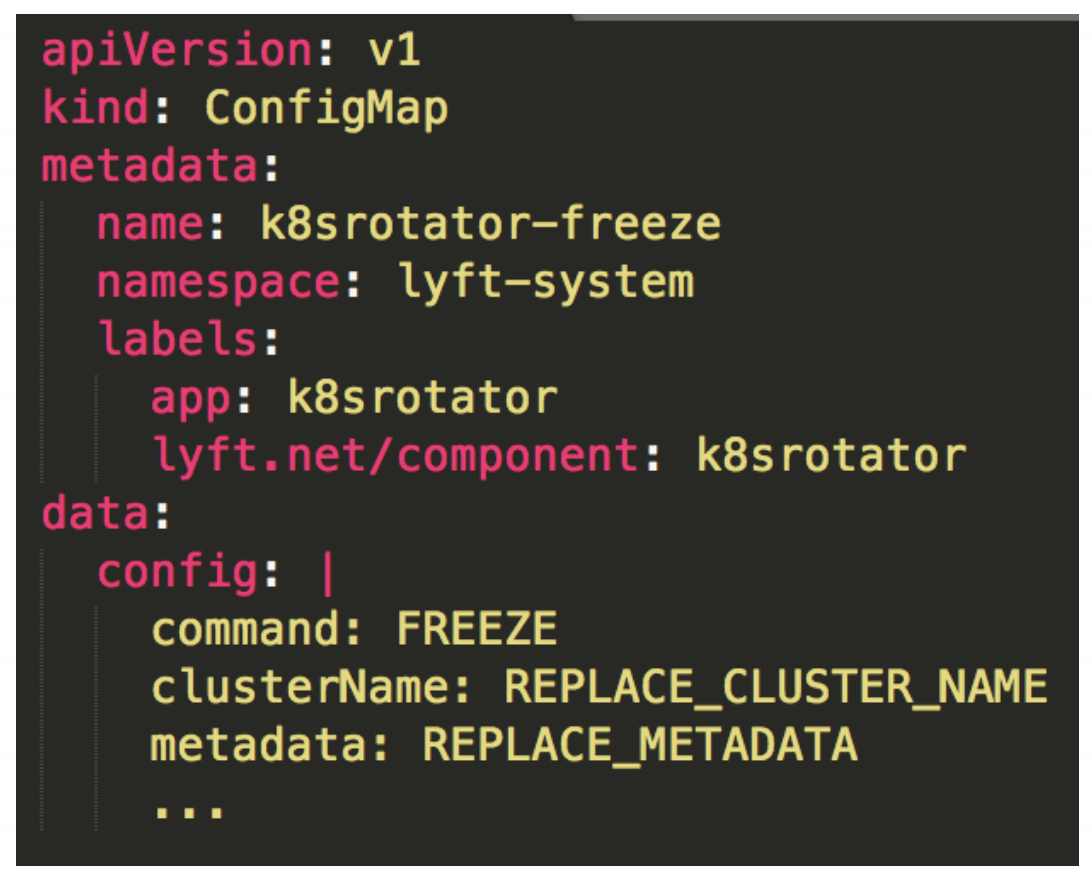
RotateはCluster Cycleをローテートする
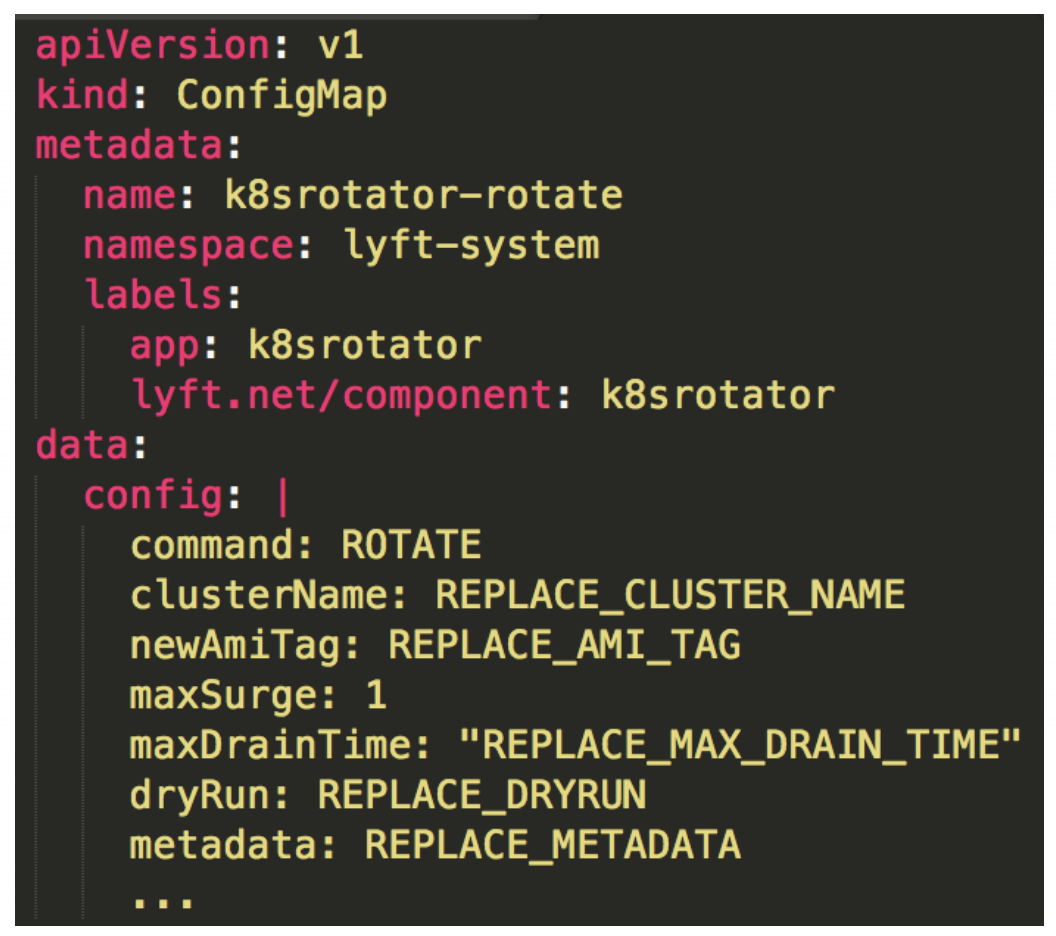
ローテーションの順番は資料に細かく書いてあるので、それを読んだ方がいい
簡単にいうと、Kubelet(Node)単位で、Old KubeletからNew KubeletへPodを移して、Drainしていく
K8srotator v1も登場
Cluster Healthを拡張, 特定ノードのフィルタリング, Cluster設定のカスタムなどを追加
取り込むべき障害シナリオは下記
・etcdがquorumを失う
・api-server, ingressの疲弊
・AWSのQuotaに当たる
・In-placeでのバージョン不整合
・ダメージコントロール
- Fleezeモードに切り替える
- User/ 管理者 / チームにアラート
・応急措置 - ログ・ステータス確認
- ローテートモードに戻す
今後やっていくとして、ML用のWorkloadの対応, Triggerの廃止, Multi Cluster, PDB, Custom Cluster Health, Node Terminateの順序化などがある
感想
Lyftでのクラスタアップグレードのお話で、クラスタ更新を自動で達成するためにOperatorを書くというアプローチが非常に面白かった
(TriggerベースでReconcile Modelではないので、たぶん厳密にはOperatorではない(似てるけど))
こうしたクラスタ自動更新のモチベーションは今のチームでもあって、非常に参考になった
今の日本だとクラスタ更新自動化を達成できている企業は限られていると思っているが、近いうちに同じモチベーションで様々な企業がこうしたクラスタ更新自動化に取り組んでいくのではないかな、という予感がしている
惜しむらくはKubeConでの世界のテックカンパニー各社が各社で別々の仕組みを構築していること。つまりデファクトスタンダードはない
ビジネスの特性によってWorkloadの特性も違うので、当然といえば当然かもしれないが...
公式からはkubeadm以上のものは出ない気がするので、もしやるならその選択になるのかもしれない
Am I Using It Right? Checking Best Practices on Live Kubernetes Clusters
DigitalOceanのClusterlintの話
Clusterlintというクラスタチェックツールを開発したようだ
best practices checker for Kubernetes clusters
https://github.com/digitalocean/clusterlint
DOKSというのがDigitalOceanのマネージドK8sサービス
Clusterlintで、K8sのベストプラクティスをチェックする
Clusterlint queries live Kubernetes clusters for resources, executes
common and platform specific checks against these resources and
provides actionable feedback to cluster operators.
とのこと
あとはClusterlintの使い方がメイン
Clusterlintの目指していることは
・マニフェストではなく、クラスタそのもののチェック
・プラットフォームごとの分析
・他のコードとの統合
ClusterlintはK8sからResourceを取得して、チェックし、結果をレポートする
次のように使う
clusterlint run -G aws
チェックするルールはコードで書く
実際にベストプラクティスに則っていないPodをデプロイし、チェックするデモもありました。
DigitalOceanの商用にはこのClusterlintを組み込んでいるらしい
最後には、他のLintツールにも触れていました
感想
YAML LinterはOSSで見かけることがあったものの、Clusterそのものをチェックする、というアプローチは初めてだったので興味深かった。
ベンダロック感も少し感じたが、利用者がコードを書いて、それでチェックできるのであれば良い選択肢かもしれない
The Gotchas of Zero-Downtime Traffic /w Kubernetes
Graceful Trafficでzero-downtimeを実現する話
前半はNginx + NodeJSのアプリを元に、説明
Podのシャットダウンは、kube-apiserverがDeleteを受信
PodはTerminatingステータスになる
全てのコンテナのPID 1がSIGTERMを受信する → (Termination Grace Period Seconds) → 全てのコンテナのPID 1がSIGKILLを受信する
Gotcha #1 CMD vs ENTRYPOINT
ENTRYPOINTでsh -c nginxを使うと、shにSIGTERMが送られる
Gotcha #2 STOPSIGNAL
Docker RuntimeだとSTOPSIGNALでSIGTERMを書き換えできる
Gotcha #3 Readiness / Liveness Probe
LivenessはプロセスがOKかどうかを確認
Readinessはプロセスが応答を受けられるかを確認
Gotcha #4 PreStop
preStopが動いている or SIGTERMが送られた時、Applicationは通信を受け続けている
(ServiceのEndpointが非同期で更新されるため)
重要なのは、ほとんどの場合のグレースフルシャットダウンの定義で、プログラムはKubernetesの期待に沿っていない。
新しい通信を受け付けないように、/bin/sleepも必要になる
(おそらく、新しい「sleep」LifeCycleHookを入れた方が良いのでは、と)
Gotcha #5 Deployment
replicasが1の時はRollingUpdateのmaxUnavailableを0にしておく
DefaultではmaxUnavaliableが1になっている(apps/v1betaで修正)
apps/v1を使っていることを確認しよう
Gotcha #6 Deployment
.spec.strategy.minReadySecondsと.spec.strategy.progressDeadlineSecondsの時間の間に、アプリケーションのウォームアップが完了するようにする
そして.spec.strategy.rollingUpdate.maxSurgeがキャパシティを超えないようにする
Gotcha #7 SideCar
AppがDBに接続するためのプロキシをSideCarとしている場合、preStop hookの間に競合しないように、同期またはスケジューリングするべき
まとめ
- entrypointはシグナルをハンドルすべき
- STOPSIGNALが必要になるかもしれない
- Liveness / Readiness Probeは異なる間隔を設定する
- 接続を受け付けないように、preStopではSleepを入れる
- apps/v1 Deploymentを使う
- RollingUpdateの間にウォームアップを行う
- SideCarのシャットダウンを同期させる
感想
アプリケーションで502,503を発生させずにいかに(ローリング)アップデートさせるか、という点に焦点をあてたセッションで非常にためになりました。
結局、リクエスト停止はsleepが最善なのか……
すでに取り組めていること、考えたことすらなかったことのどちらもあるので、もうGracefulについて考え直そうかな…
Evolving the Kubernetes Ingress APIs to GA and Beyond
Ingressの現状はNginx Ingress ControllerやHAProxy Ingress Controllerのようなプロダクトが出ている
v1ではIngressClassというモデルにクリーンアップする
backendをdefaultBackendにリネーム
パスが正規表現だが、Nginx/HAProxyでは合わないことも
v1ではPathTypeが追加される(詳しくは資料内の表を参考に)
PathTypeでPrefixも許容される
HostnameのWildcard
*.foo.comで「bar.foo.com」はOK。「baz.bar.foo.com」「foo.com」はNG
IngressClassはControllerとParameterをフィールドに持つ
v1betaではIngressBackendにserviceNameを持っているが、v1ではServiceBackendやServiceBackendPortなどの構造体が増える
v1 API Timelineとして、v1.18でIngress v1をRelease予定
v1.19でextension/v1beta1から取り除かれる。networking.k8s.io/v1beta1もv1.2xで取り除かれる
早期設定デザインは“self-service” oriented
現在は実装がたくさん...
より良いResource管理モデルの構築や、携帯性を保ちながら現在のLoadBalancing機能をサポートするのがゴール
※あくまで以下のAPIは提案ステージ。これからも変わっていく予定
Ingressはセルフサービスモデル
IngressClassがインフラプロバイダによって開発される
GatewayClassもインフラプロバイダが開発する
GatewayはLBのインスタンスのこと
RouteとServiceをApplicationエンジニアなどが定義する
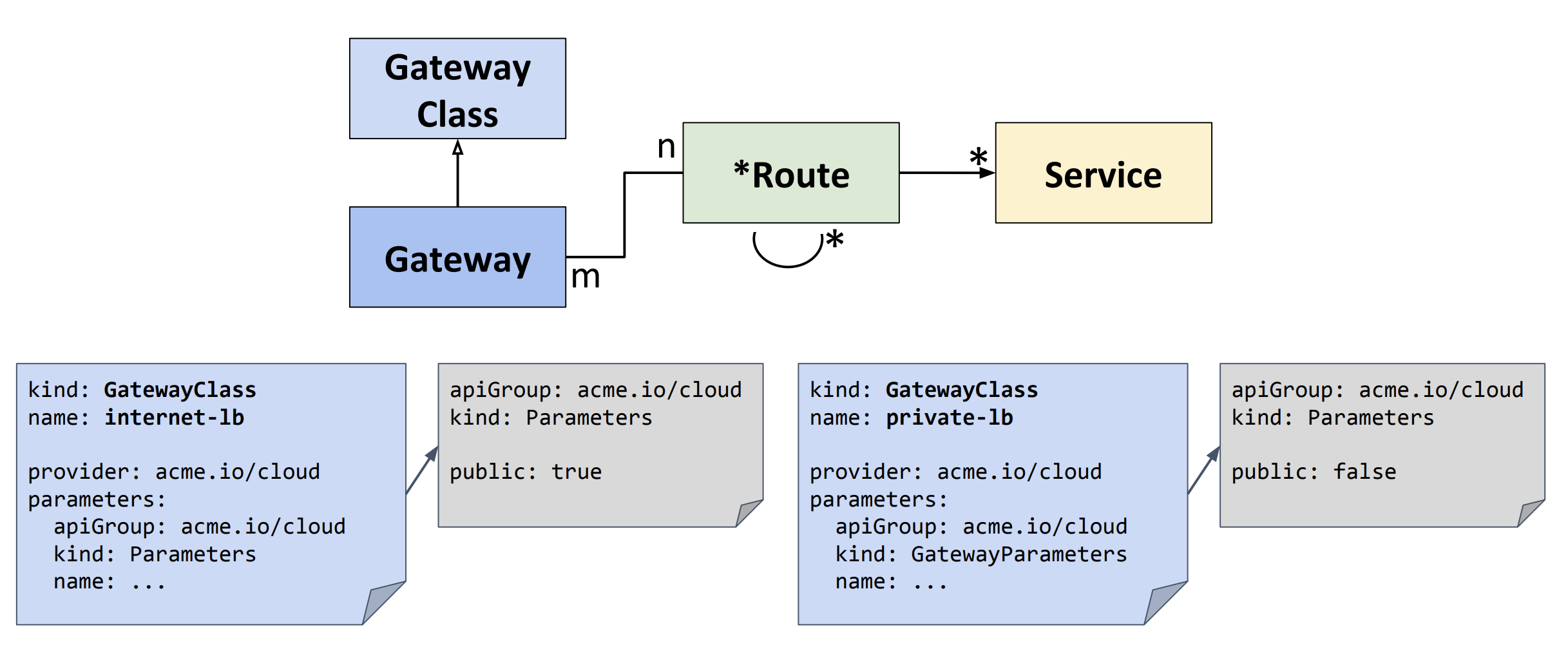
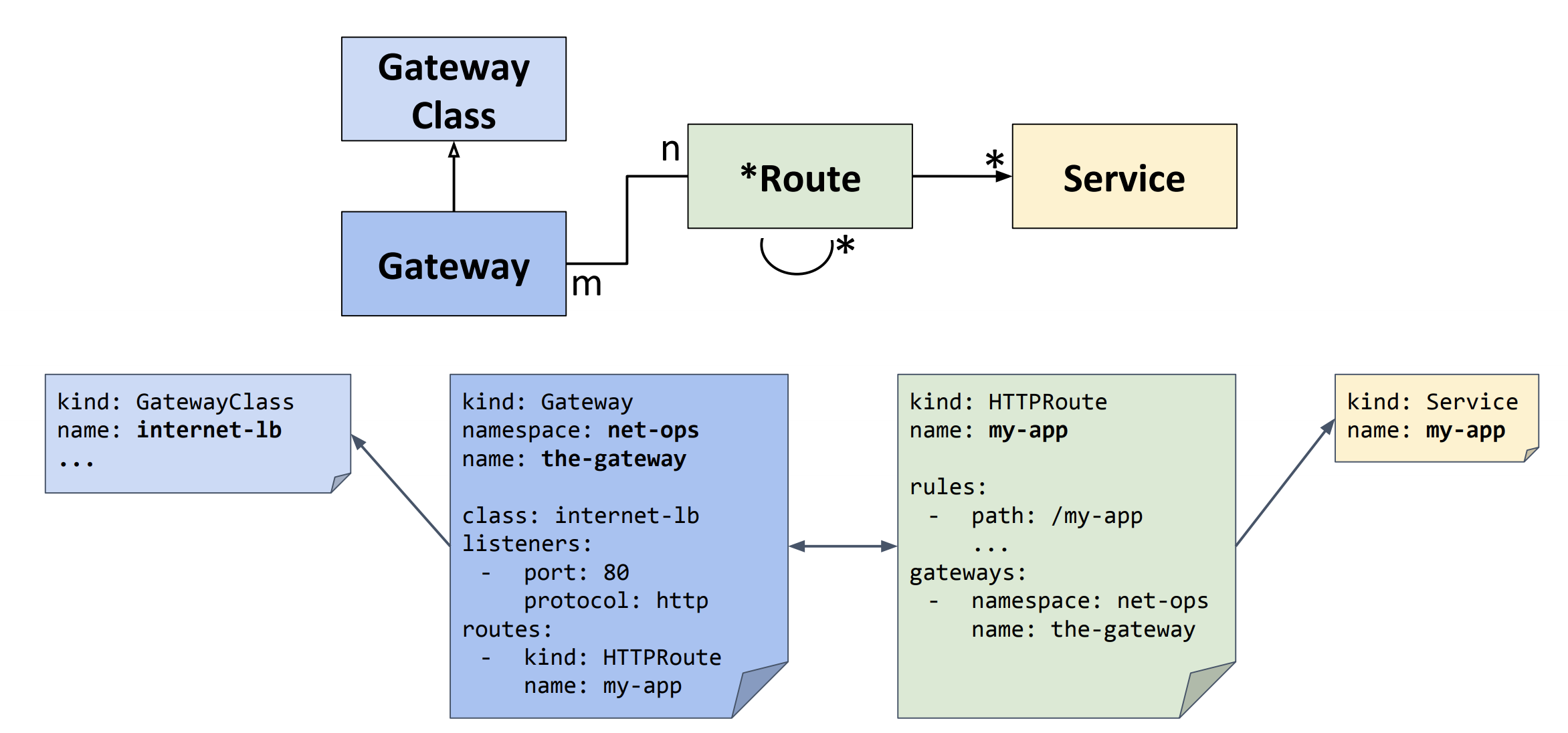
RBACモデルでUSERがどういったROLEで、どのRESOURCEをどうVERBするのか、という記述ができるようにした
API Resourceのデザインや実装はこれから(Help Wanted!)
感想
IngressをGAに持って行こうという話で、まずはv1の拡張。
そしてv2でモデルを綺麗にするという話でした。
モデルを綺麗にすることでResourceが増えて、より複雑性は増しますが、ようやくそれでプロバイダー関係なく綺麗にまとまるのならアリかなと個人的には思いました。
Resourceが分割されることで、インフラプロバイダ•クラスタ管理者•アプリ開発者の役割が分割されて適正化されることに期待です。
(でもv2の実装はまだまだ先のよう)
Tutorial: Mastering Multi-version CRDs: From YAML to a Serious Development Project
CRDの応用機能は多数ある(Defaulting, Pruning, Conversion, etc...)
今回はConversionが主役
KubernetesのオブジェクトにはVersion XXのオブジェクトという考え方はない(裏側でバージョンの違いをConversionして互換性を保っている)
今回は機能の説明をしながら、実際のConversion, Admissionのソースに手を入れていくチュートリアル形式
こちらにソースがあるので、気になる人は読むと良いかも
(Programming Kubernetesを読んでいれば理解できると思う)
ClusterはMinikubeやKindなどでv1.16のクラスタを用意して、リポジトリに用意してあるYAMLをApplyすれば良い
チュートリアルリポジトリ:
https://github.com/jpbetz/Ko
感想
Programmin Kubernetesの著者の一人によるMulti Version CRDのチュートリアルという、すごく豪華なセッションでした。
CRDはv1.16でGAになりましたが、「今後CRDに他の応用機能が追加される予定がありますか?」と聞いたところ、Deep Dive Into API MachineryのKEP2つとUnionTypeのKEPが予定に入っているとのこと
CRDにはBreaking Changeがなさそうで安心した