背景
機械学習で最も重要なものと聞かれたら、何を思い浮かべますか?「最新のモデル!」と答える人も多いでしょう。それも確かに重要ですが、実はそれ以上に大切なのが良質な学習データです。質の高いデータがあれば、たとえモデルが最新でなくても十分な成果を上げることができます。しかし、どれだけ優れたモデルを使ったとしても、学習データの質が悪ければ期待する成果は得られません。
とはいえ、学習データの準備は決して簡単ではありません。データの収集には手間がかかり、さらにアノテーション作業は非常に時間がかかる地道な作業です。
そこで今回は、アノテーション作業を少しでも効率化する方法をご紹介します。YOLO-WorldとCVATを活用することで、アノテーション作業をスムーズに進める方法を解説します。
cvatとは
cvatは高機能なラベリングツールです。
CVATの詳細については、クラスメソッドさんが公開しているこちらの記事が非常にわかりやすく参考になります。
YOLO-Worldとは
YOLO-Worldは2024年に発表された物体検出モデルです。通常のyoloシリーズとは異なり、オープンボキャブラリー物体検出を特徴としています。この機能により、カスタムデータによる学習なしに、自然言語を使って柔軟に物体を検出することが可能です。以下はGitHubの記載から引用した説明です:
YOLO-World is the next-generation YOLO detector, with a strong open-vocabulary detection capability and grounding ability.
百聞は一見にしかずということで、Hugging Face上で公開されているデモを是非試してください!
自動アノテーションの手法について
今回使用するサンプルコードはこちらです:
今回のお題
今回は、画像内の道路標識を自動でアノテーションする方法を解説します。
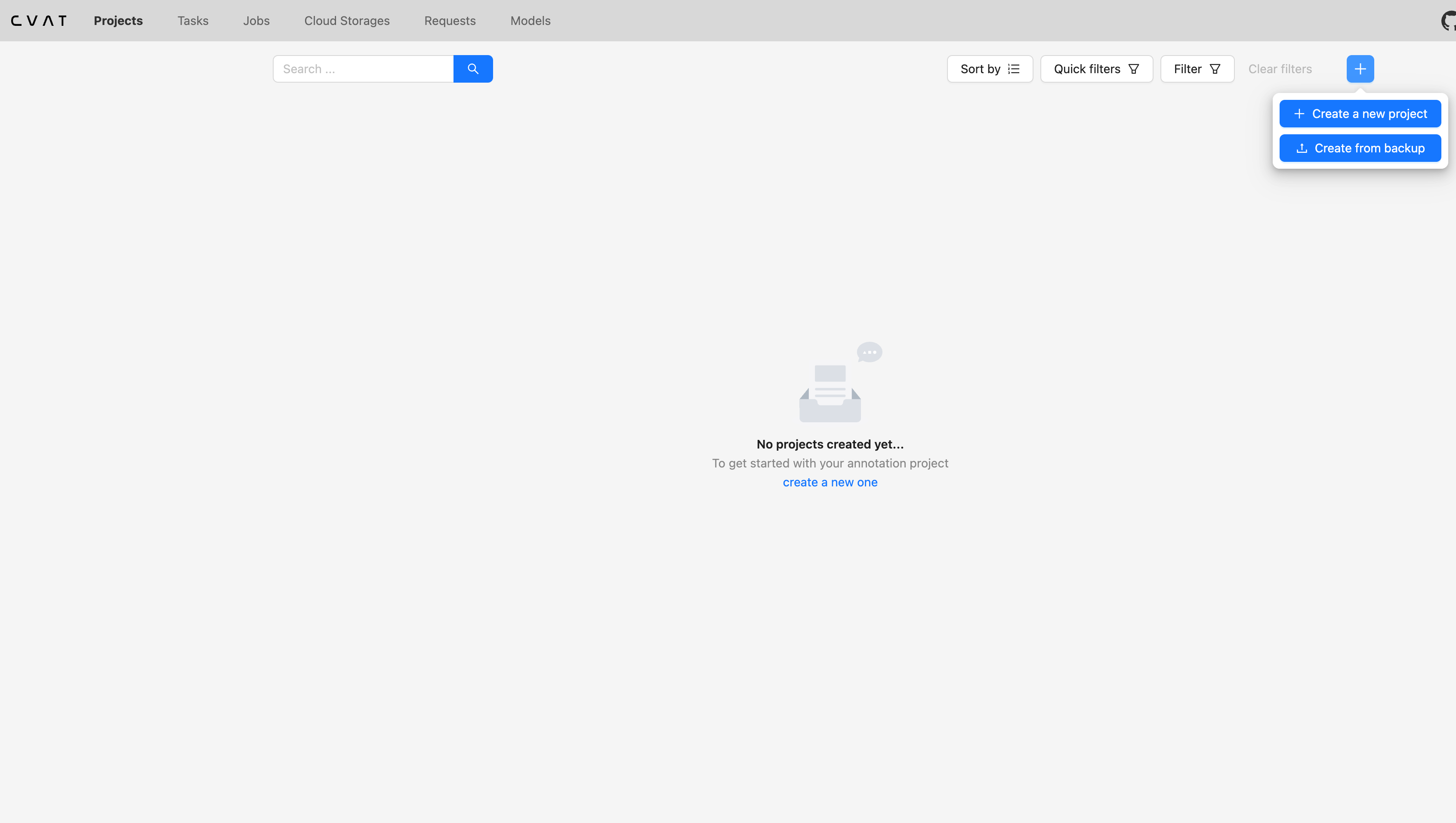
ステップ1: プロジェクトの作成
まずはcvat上でプロジェクトを作成します。右上の『Create a new project』を押下し、以下のように設定を行います。
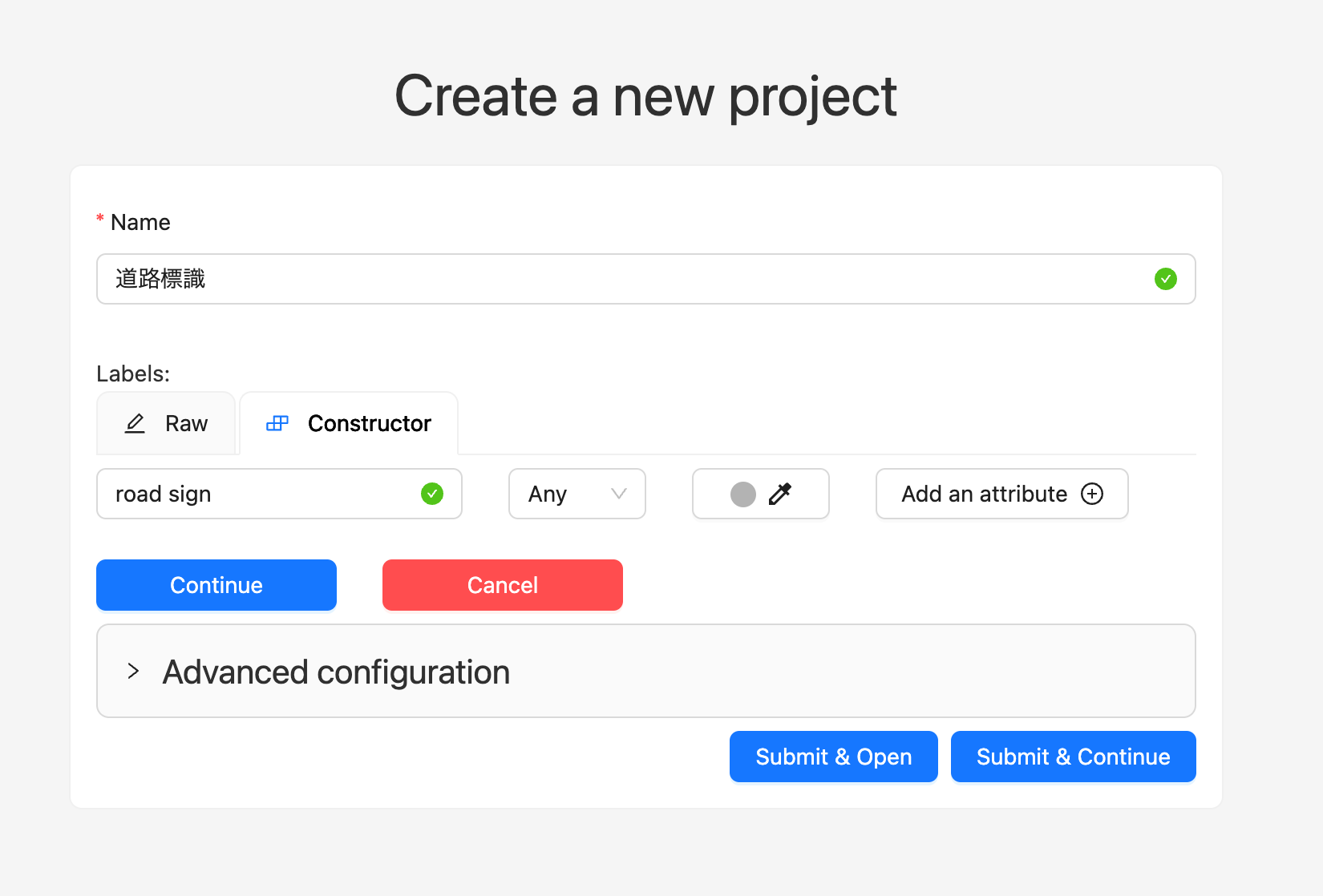
ステップ2: ラベルの設定
アノテーションしたいラベルを追加します。今回は道路標識のみなので『road sign』としておきます。
コードの説明
流れは非常にシンプルです。
- 画像を読み込む
- YOLO-Worldで画像を推論する
- アノテーション対象(今回は道路標識)を検出し、その結果をXMLに追記する
以下にYOLO-Worldを用いた推論部分のサンプルコードを示します。
となります。
# 検知したい対象を指定
# ここでは道路標識を検知するように設定
DETECTION_TARGET = ["road sign"]
# yoloのモデルを読み込み
model = YOLO("yolov8s-world.pt")
model.set_classes(DETECTION_TARGET)
def execute_yolo_inference(image_path):
results = model.predict(
source=image_path
)
# debug用で結果を表示したい場合はコメントアウトを外す
# results[0].show()
return results[0].summary()
YOLO-Worldでは検出対象を自然言語で指定可能です。ただし、医療データのような複雑なドメインについては、学習なしでの高精度な推論は難しい場合があります。
コードの詳細はコメントをなるべく多めに記載しているので是非ご覧ください。
サンプルコードの実行方法
このプロジェクトではuvライブラリを使用して依存関係を管理しています。uvがインストール済みの場合、以下のコマンドで実行可能です:
uv run python src/main.py
実行後、sample.zipというファイルが生成されます。このファイルをCVATにインポートすることで、アノテーション結果を確認できます。
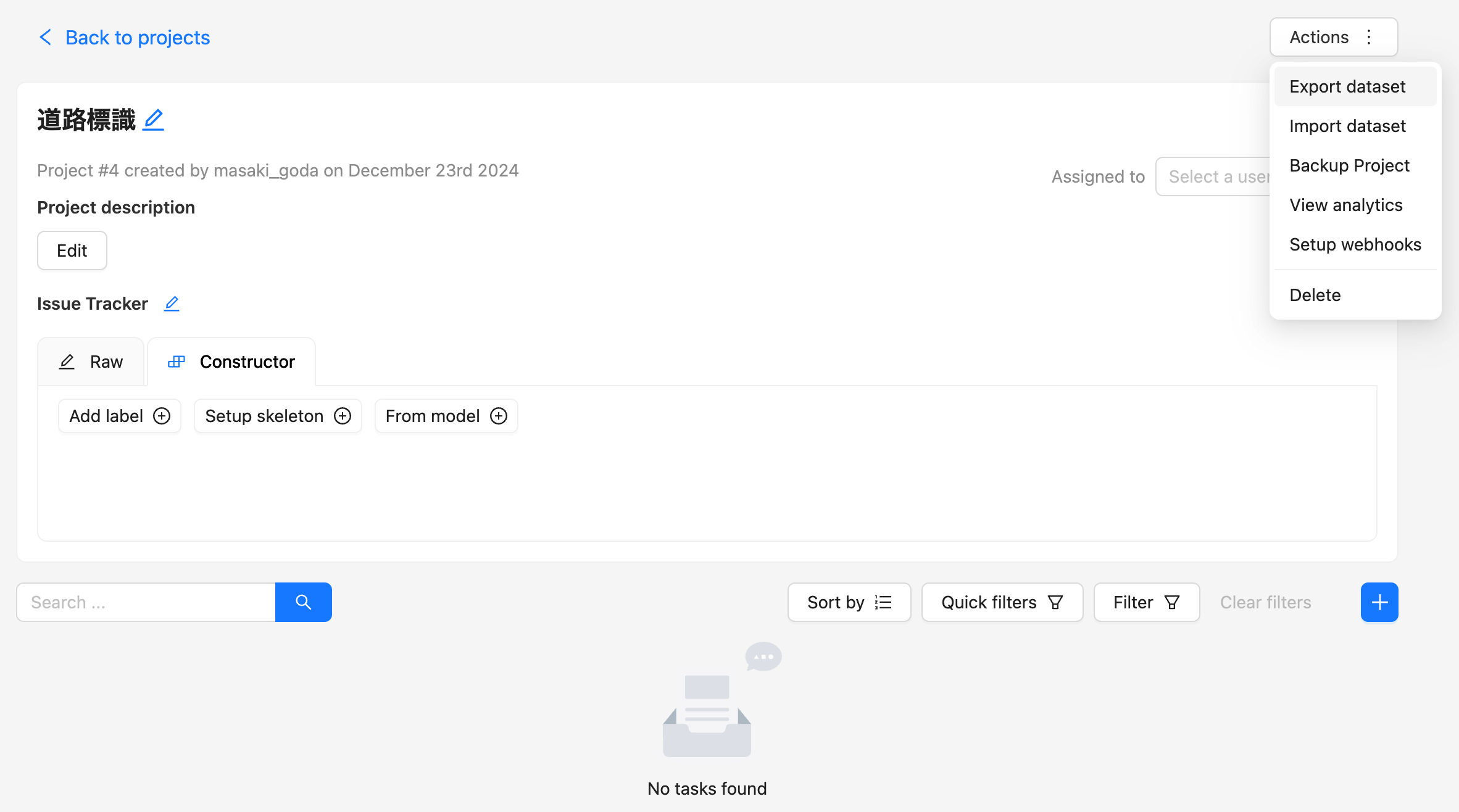
CVATでのインポート
-
CVATで「Import dataset」ボタンを押下します。
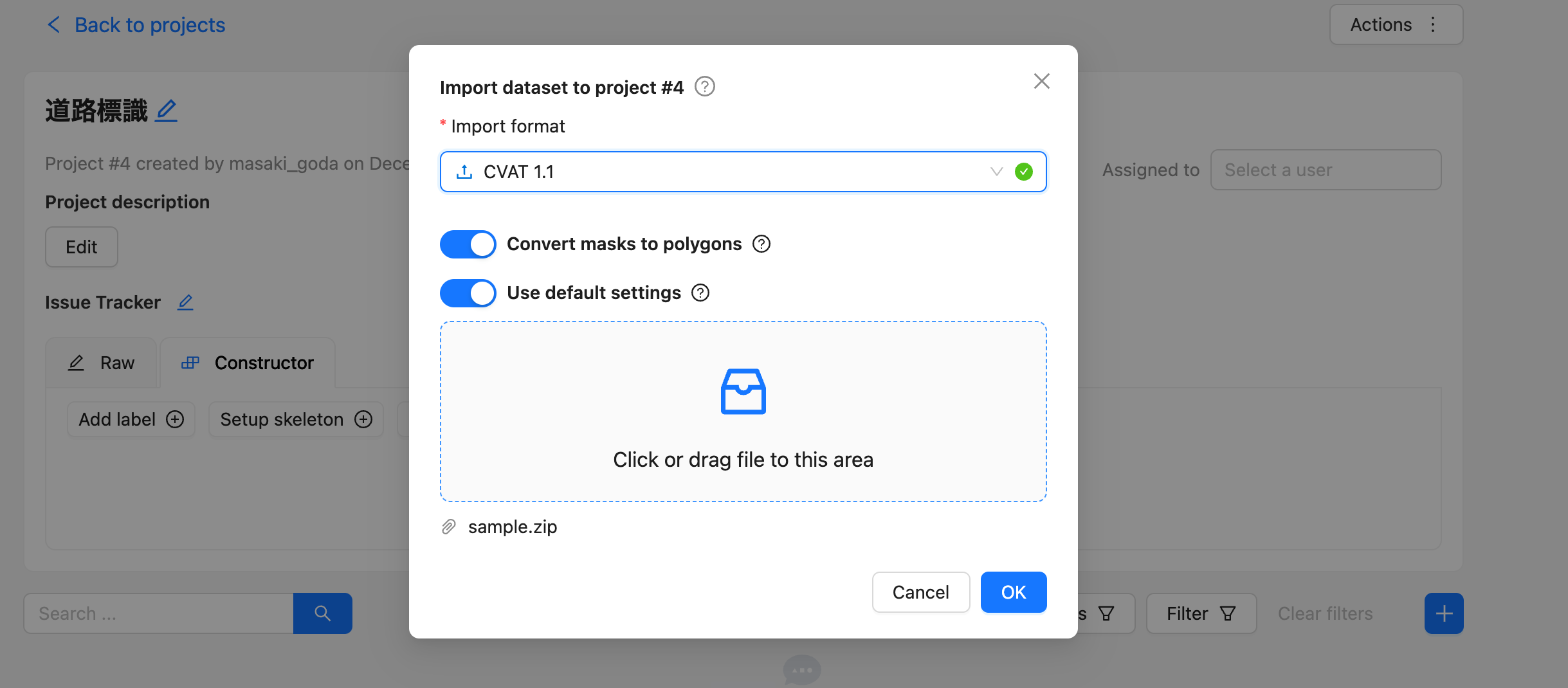
-
フォーマットは「CVAT 1.1」を選択し、生成されたZIPファイルをアップロードします。
-
数秒後、インポートが完了し、アノテーション結果を確認できます。
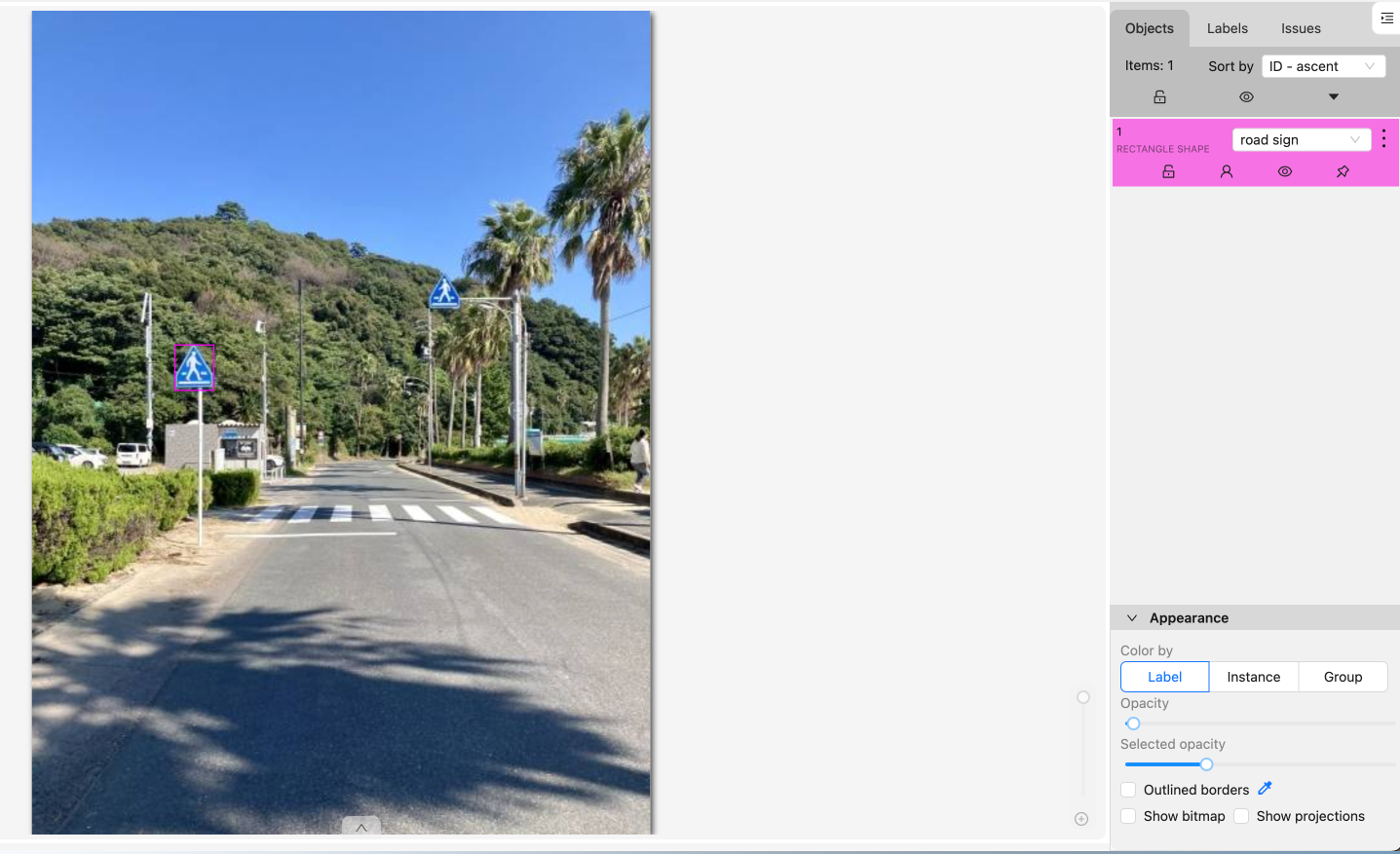
インポート結果を確認すると、今回のサンプル画像では、左側の指示標識に矩形があることがわかります。しかし、右側の標識は検知することができていません。これは、閾値設定などを調整することで改善が可能です。
自動アノテーションが活躍するユースケース
この手法は、以下のような場面で特に有効です:
- 既存データの活用: 社内に大量の画像データがあるが、どの画像に特定のオブジェクトが含まれているか分からない場合。YOLO-Worldを使用して全画像を一括処理し、対象画像を絞り込みながら同時にアノテーションを生成できます
- 細かい分類の準備: 例えば、道路標識の「road sign」アノテーションをさらに「止まれ」や「進入禁止」といった詳細なラベルに分類する場合。矩形アノテーションはすでに完了しているため、ラベル付けの作業を効率化できます
まとめ
本記事では、YOLO-WorldとCVATを活用した効率的な自動アノテーションの手法を紹介しました。
近年では、YOLO-Worldに加えてMeta社のSAM(Segment Anything Model)など、多くの自動アノテーション手法が存在します。これらを組み合わせることで、アノテーション作業をさらに効率化できます。ぜひ、本記事を参考にして、アノテーションの負担を軽減し、より良いデータセット作成を実現してください!