概要
前回【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた②
前々回【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた①
に引き続き、netkeiba-scraperで取得した過去10年データを使って競馬の妙味について分析していきます。
またSQLへ列(妙味計算用フラグ)を追加し、matplotlibで散布図を描くことも行ないます。
今回のテーマは「人気より着順を上にもってくる騎手」です。
騎手で馬券を買うこと
前回までの分析では、単勝人気と競馬場コースという、「人」でも「馬」でもないファクターを使用しました。
そのため「期待値の高い買い目を探す」ことが目的となってしまい、また再現性に乏しい(分析結果を100%信じて買いづらい)分析となってしまいました。
しかし「馬」にフォーカスした分析は困難な理由がいくつもあります。
・一般的に生涯1-30戦程度しか出走しないため、分析する間に引退してしまう
・走法(完歩のピッチやストライド)のデータを集めるのが非常に難しい(一頭ずつ手動計測する他ない)
・競走馬の能力は一定ではない
・レースで競う相手が毎回同じでない
そこで今回は、騎手に焦点を当てて分析していこうと思いました。
得意コース、苦手コースを見極め、馬券妙味に繋げていきたいと思います。
「人気より走った」フラグをSQLに追加する
「実力の割に人気しにくい馬を狙う」のが競馬ファンのセオリーの一つであります。
そこでnetkeiba-scraperで取得したテーブルに、新たに列を追加します。
# 人気と結果の差でフラグ付ける
# 0が人気-結果が3以上、1が+-2以内, 2が-3以下
import mysql.connector as mydb
import sqlite3 as sq
conn = sq.connect('race.db')
cur = conn.cursor()
cur.execute("ALTER TABLE race_result ADD COLUMN umami INTEGER")
cur.execute("UPDATE race_result SET umami=0 WHERE popularity - order_of_finish >= 3")
cur.execute("UPDATE race_result SET umami=1 WHERE abs(popularity - order_of_finish) <3")
cur.execute("UPDATE race_result SET umami=2 WHERE popularity - order_of_finish <= -3")
conn.commit()
umamiという名前の列を追加し、「人気 - 着順」が3以上の時は0, ±3未満の時は1, -3以下の時は2としました。
例えば12番人気で6着なら0, 2番人気で4着なら1, 1番人気で5着なら2となります。
騎手別の妙味、勝率などを調べる
追加したumami列を使って、騎手別の人気-着順平均を見てみましょう。
ノイズを防ぐため、通産騎乗回数が100回未満の騎手は除いています。
cur.execute("SELECT r.jockey_id, round(avg(r.umami),3), \
round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \
sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \
count(*) \
FROM race_result r INNER JOIN race_info i on r.race_id=i.id \
GROUP BY r.jockey_id HAVING count(r.umami) >= 100 ORDER BY avg(r.umami) ASC")
rows = cur.fetchall()
print('騎手id', 'umami', '勝率', '複勝率', '勝利数', '複勝数', '騎乗回数')
for row in rows:
print(row)
-----結果-----
騎手id umami 勝率 複勝率 勝利数 複勝数 騎乗回数
('01082', 0.668, 2.51, 9.55, 5, 19, 199)
('01105', 0.706, 2.39, 12.17, 10, 51, 419)
('01010', 0.713, 1.87, 8.05, 13, 56, 696)
('01177', 0.723, 0.45, 8.52, 1, 19, 223)
('01057', 0.724, 2.82, 9.32, 10, 33, 354)
etc...
騎手ごとのumami、勝率、複勝率をまとめることができました。
matplotlibで散布図表示する
# umamiと複勝率でグラフを描いてみる
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x = []
y = []
for row in rows:
# xにumami, yに複勝率を入れていく
x.append(row[1])
y.append(row[3])
plt.scatter(x,y)
plt.xlabel("umami")
plt.ylabel("fukushou")
plt.show()
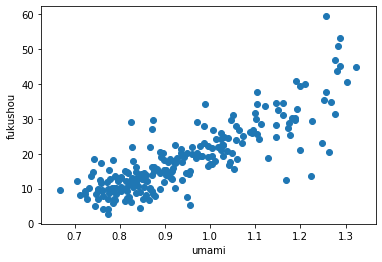
ここで捕捉しておきたいのは、【umamiの数値は人気のない馬ほど0に近づきやすい】ことです。
12番人気で6着であればumamiは0ですが、1番人気で1着でもumamiは1、もし4着なら2になるため、
【人気騎手ほどumamiの数値は2に近づきやすい】です。
そのためumami数値が小さい騎手は複勝率も低い結果となりがちです。
こうして騎手の複勝率とumamiの相関関係を可視化することができました。
基本的にグラフ左上にいる騎手ほどオイシイ馬券をもたらし、右下にいる騎手ほど「買うべきでない」人気先行型といえます。
ちなみにumamiが1未満で複勝率が30%付近にいる騎手は障害レースの金子騎手や白浜騎手、
複勝率が50%を超えている騎手はモレイラ騎手やC.ルメール騎手、
umamiが1.1以上で複勝率が20%周辺にいる騎手は藤田菜七子騎手、ミナリク騎手、ピンナ騎手などでした。
騎手を深堀りしてみる
武豊騎手のコース別成績を調べる
例として、武豊騎手のデータを見てみましょう。umamiは1.267, 複勝率は35%とmatplotlibのグラフではボーダー上に位置している(人気通りの成績を残している)騎手です。
ここからは平均着順と平均人気も追加しています。
# 武豊を狙うべき競馬場とコースを考える
# 30回以上走ったコースのみ表示する
cur.execute("SELECT i.place, i.surface, i.distance, round(avg(r.umami),3), \
round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
round(CAST(sum(r.order_of_finish) as float) / count(*), 2), \
round(CAST(sum(r.popularity) as float) / count(*), 2), \
sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \
sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \
count(*) \
FROM race_result r INNER JOIN race_info i on r.race_id=i.id \
WHERE r.jockey_id='00666' GROUP BY i.place, i.surface, i.distance HAVING count(*)>=30 ORDER BY avg(r.umami) ASC")
rows0 = cur.fetchall()
print('競馬場コース', '妙味', '勝率', '複勝率', '平均着順', '平均人気', '勝利数', '複勝数', '騎乗回数')
for row in rows0:
print(row)
-----結果-----
競馬場コース 妙味 勝率 複勝率 平均着順 平均人気 勝利数 複勝数 騎乗回数
('京都', '芝右外', 1400, 1.09, 17.72, 37.97, 5.28, 4.37, 14, 30, 79)
('阪神', '芝右', 2200, 1.1, 26.0, 52.0, 4.58, 4.04, 13, 26, 50)
('東京', '芝左', 2400, 1.106, 8.51, 19.15, 7.45, 6.26, 4, 9, 47)
('京都', '芝右', 2000, 1.121, 14.75, 39.34, 5.07, 4.11, 27, 72, 183)
('京都', '芝右外', 2400, 1.122, 22.0, 44.0, 4.32, 3.48, 11, 22, 50)
etc.....
傾向として、京都競馬場芝コースでは人気以上に持ってくることが多い騎手のようです。複勝率も平均以上です。
京都競馬場は武豊の庭!と言われるのも納得できますね。
横山典弘騎手の「ヤラズ」を分析する
横山典弘騎手は「ポツン」「ヤラズ」など、馬の余力を残したままレースを終えることが一部で話題の騎手です。
どのような条件で「ヤラズ」になるのか? umami数値を使えば見えてきそうです。
# 横山典弘を狙うべき競馬場とコースを考える
cur.execute("SELECT i.place, i.surface, i.distance, round(avg(r.umami),3), \
round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \
round(CAST(sum(r.order_of_finish) as float) / count(*), 2), \
round(CAST(sum(r.popularity) as float) / count(*), 2), \
sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \
sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \
count(*) \
FROM race_result r INNER JOIN race_info i on r.race_id=i.id \
WHERE r.jockey_id='00660' GROUP BY i.place, i.surface, i.distance HAVING count(*)>=30 ORDER BY avg(r.umami) DESC")
rows0 = cur.fetchall()
print('競馬場コース', '妙味', '勝率', '複勝率', '平均着順', '平均人気', '勝利数', '複勝数', '騎乗回数')
for row in rows0:
print(row)
-----結果-----
競馬場コース 妙味 勝率 複勝率 平均着順 平均人気 勝利数 複勝数 騎乗回数
('札幌', 'ダ右', 1700, 1.293, 17.24, 43.97, 5.45, 3.53, 20, 51, 116)
('福島', '芝右', 2000, 1.281, 9.38, 28.13, 7.53, 5.22, 3, 9, 32)
('新潟', 'ダ左', 1800, 1.25, 12.5, 28.13, 6.81, 5.06, 4, 9, 32)
('中山', '芝右', 2000, 1.25, 4.97, 23.2, 6.86, 5.22, 9, 42, 181)
('東京', 'ダ左', 1600, 1.24, 15.0, 31.59, 6.15, 4.56, 66, 139, 440)
etc...
行が多いため見せられませんが、目立つのはダートコースのumami数値の高さです。
「馬が走る気を失くしたら無理に追わない」というスタンスの騎手ですので、
馬が砂をかぶって意欲を失いやすいダートコースでは人気を裏切るケースが多いということでしょうか。
武豊騎手は芝・ダート別でumami数値のバランスがよい(芝でもダートでも人気通りの着順になりやすい)のに対し、
横山典弘騎手はダートで特にumami数値が悪いなど、騎手ごとの個性も垣間見ることができました。
まとめ
今回は騎手に焦点を当てて分析を行いました。
騎手のコース別成績をさらに深堀りすれば、より競馬が面白くなるかもしれませんね。
ここまでご覧いただきありがとうございました。