fluentd & ElasticSearchで構築したシステムでログの取りこぼしが見つかったので原因を調べて対策した。
状況
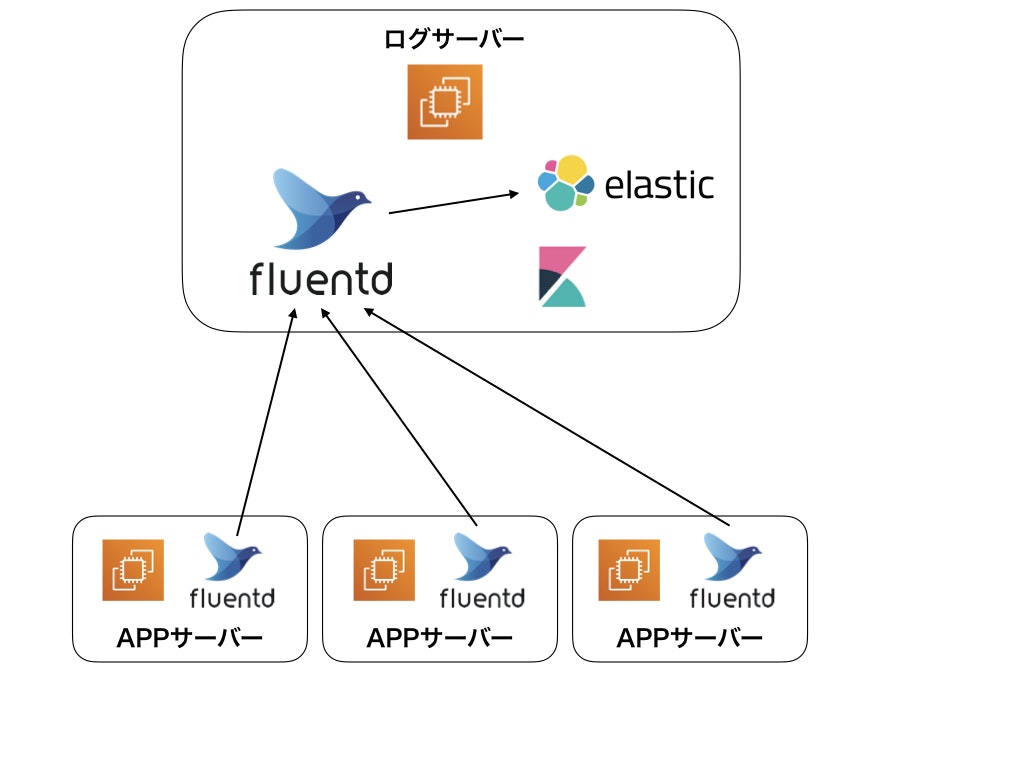
複数のAppサーバーのログをfluentdで一台のサーバーに集約し、そのログをElasticSearchに入れて解析できるようにしてる。
- バージョン
- fluentd: 1.2.3
- Elastic Search 6.2.4
- Kibana 6.2.4
- 各APPサーバーのログをログサーバーで一旦1ファイルに集約して出力
- 集約したログをElasticSearchに突っ込んでKibanaで可視化
問題となったのは以下のもの
- あるバッチから吐かれたログをElasticSearchで確認したら、本来出力されるはずの数に足りていない
- 取りこぼしたログはバッチが開始される22時00分からの1分間に集中
- そのバッチは毎日22時ジャストに開始され24時前には終了
- 22時以前に同日のログ出力はない
- ログサーバーで出力されたログファイルに取りこぼしはなかった。
原因
fluentの挙動について
fluentdは収集したログを毎日1ファイル出力している。
/var/log/fluentd/hoge
/hogehoge.log.20190301
/hogehoge.log.20190302
/...
デイリーの新しいログ作成タイミングは午前9時だそうで、これはサーバーの時計がJST +9:00となっているためらしい。
しかし22時ジャストにその日最初のログが吐かれる場合は、22時より___少しあと___にログファイルが作成される。
___少しあと___としたのは、fluentdでは設定された時間はバッファに溜め込み、設定時間経過後に内容を出力するようになっているから。正確には22時01分ごろにログファイルは再作成されていた。
# fluentd.conf
# 関係する設定項目を抜粋
buffer_time: 60
ElasticSearchの挙動
fluentdからElasticSearchに突っ込むのにfluentd-plugin-elasticsearchを使わせてもらっている。
# fluentd.conf
# elastic searchに投入する設定の抜粋
<source>
@type tail
path /var/log/fluentd/hogehoge.log.*
pos_file /var/log/fluentd/hogehoge.pos
tag hogehoge
</source>
<match hogehoge>
@type copy
<store>
@type elasticsearch
host localhost
port 9200
logstash_format true
logstash_prefix hogehoge
</store>
</match>
fluentdはログファイルを監視してElasticSearchに投入しているが、ログの監視はlinuxのtailコマンドと同じ挙動なのかもしれない。
もしそうならログファイルが作り直される22時01分頃に監視対象の切り替えが行われるが、tailコマンドのデフォルトで10行しか抽出できない。
22時00分から22時01分まで10行以上出力されている場合は取りこぼしが発生することになる。
この辺りの詳細な挙動は、fluentdのソースを読んだわけではないが辻褄はあう。
対策
午前9時ごろにダミーのログを出力するようにして、ElasticSearchが監視するログファイルは早めに切り替わるようにしておく。
# cat dummy_log.sh
# !/bin/bash
echo "LOG START" > /var/log/hoge/hoge.log
# crontab -l
1 9 * * * /root/dummy_log.sh
最後に
自分が構築しているシステムではこれで対策できたが、9時台に常にログが吐かれるようなシステムの場合はbuffer_timeを小さくするなどして対処する必要がある。
fluentdについてそれほど詳しくないので、もしかしたらもっといい対策があるのかもしれない。
ご存知のかたいたらぜひご教示頂けると嬉しいです。
追記 (2019/04/04)
コメントで教えていただいたread_from_headを使えば、ダミーのログを出力しなくても解決できました。
<source>
@type tail
path /var/log/fluentd/hogehoge.log.*
pos_file /var/log/fluentd/hogehoge.pos
tag hogehoge
read_from_head true # 追加!
</source>
もうちょっとよくドキュメントを読めば気がつきそうなのに、、、コメントくれた方ありがとうございました!
ただfluentのドキュメントにもあるように、ログがミリ単位で吐かれるなど大量になる場合はfluentの挙動に影響が出そうなので気をつけないと。
再追記 (2019/04/09)
read_from_headオプションをつけて動かしていたら、2日ほどは正常に機能していたが3日目からログが重複していた。
調べたけどよくわからず、、、、結局元のダミーログを吐き出す方式に戻して運用することにした。
再々追記 (2019/05/09)
その後の運用監視を続けていくうえ、ログが重複するのはread_from_headerオプションとは関係ないことがわかり、色々試した結果なんとかなったっぽいのでメモっておく。
取りこぼしについて
read_from_headerオプションは、インデックス更新時に取りこぼしを起こさないために有効だったので設定を戻した。
ログの重複について
ログが重複する問題に関しては、fluentからelasticsearchにレコードを突っ込む箇所で発生している。どうやらレコードにはインデックスを付けてからelasticsearchに突っ込むらしいのだが、その際に同一レコードに別インデックスが発行されることがあるらしい。その結果Kibana上では重複して同一レコードが表示されていた(インデックス値は別物だった)。
これはfluentdの設定でインデックスの作成ロジックを変更することで解決するとのこと。勉強不足でその理由までは分かりません!!
(参考:https://omohikane.com/fluentd_add_hash/)
最終的な設定
あれこれ悩んで結局以下のような設定でうまく動きました!
<filter hogehoge.**>
@type elasticsearch_genid
hash_id_key _hash
</filter>
<match hogehoge.**>
@type elasticsearch
host localhost
port 9200
logstash_format true
logstash_prefix hogehoge
id_key _hash
remove_keys _hash
</match>
<source>
@type tail
format /^\[(?<time>[^\]]*)\] (?<message>.*)/
path /var/log/fluent/hogehoge.*
pos_file /var/log/fluent/hogehoge.pos
tag hogehoge
read_from_head true
</source>
いや〜〜、難しいっすね。。
サーバーインフラ専任のエンジニアがいたらな〜