前提
このエントリはClean Architecture自体はすでに知識がある前提になりますので、なにそれ?という人はQiitaやGoogleで検索をしてみてください。
はじめに
#3を書いてからもう1年以上も経ってしまったのですが、ようやく手元のコードでオレオレCleanArchitectureを実装してみた&書籍Clean Architectureを読了したので、実装するだけでは分からなかったこと&書籍から学べたことを整理したいと思います。
ちなみに
書籍のClean Architectureは非常に良い内容でした。単なるClean Architectureというアイディアの紹介やサンプルだけではなく、読者がClean Architectureの背後にある考え方や原則を理解するための基礎となる部分もかなりの分量で説明されています。この基礎の部分は他のアーキテクチャやパターンを理解する上でも使える教科書的な内容になっています。そのため、これからクラス構成やアプリケーション構成を考える経験を積みたい人にはおすすめです。また、すでにそのような経験を積んだ人にも「こういう伝え方がある」という面ではよい資料になるのでは無いかと思います。
なお、クラス図などのUMLが多めに使われています。私は何度も図と文章を行き来しながら読み進めました。そのため、電子書籍ではなく、実際の本を買うことを強くおすすめします。
今回整理したいポイント
さて、本題に戻って今回は以下の点について整理します。
- 依存性はいつ注入するのか?特にDBなどのUI以外の具象クラスへの依存性。
- Streamを使うべきか?単なるmethodを使うべきか?
1. 依存性はいつ注入するのか?特にDBなどのUI以外の具象クラスへの依存性。
UIは通常、アプリケーションには画面遷移があり、ユーザ操作によって画面Aに遷移してきたときに対応する「画面A」インスタンス(iOSのViewController, AndroidのActivity)がその都度初期化されます。(戻る遷移は除く)
この時、UI側のクラスが、Interface Adapter層(Presenter)、さらにはApplication Business Rule層(UserCase)の対応するクラス達を初期化し、依存性注入を行うメソッドを叩けばUI→Presenter→UseCaseまでの初期化と依存関係の構築は完了します。
一方、このままだと「とある処理で何かの値を永続化」したり、「ネットワーク経由で別システムの値を取得」しなければならない場合、UseCaseからDBやNW側のInterface Adapterを経由してDBクラスやNWクラスのインスタンスを生成したくなります。しかし、これは許されていません。内側のレイヤーであるUseCaseから、外側(=詳細)のレイヤーであるUI, DB, NetworkのそれぞれのInterface Adapter層に向かって依存関係を持つことは禁止されています。
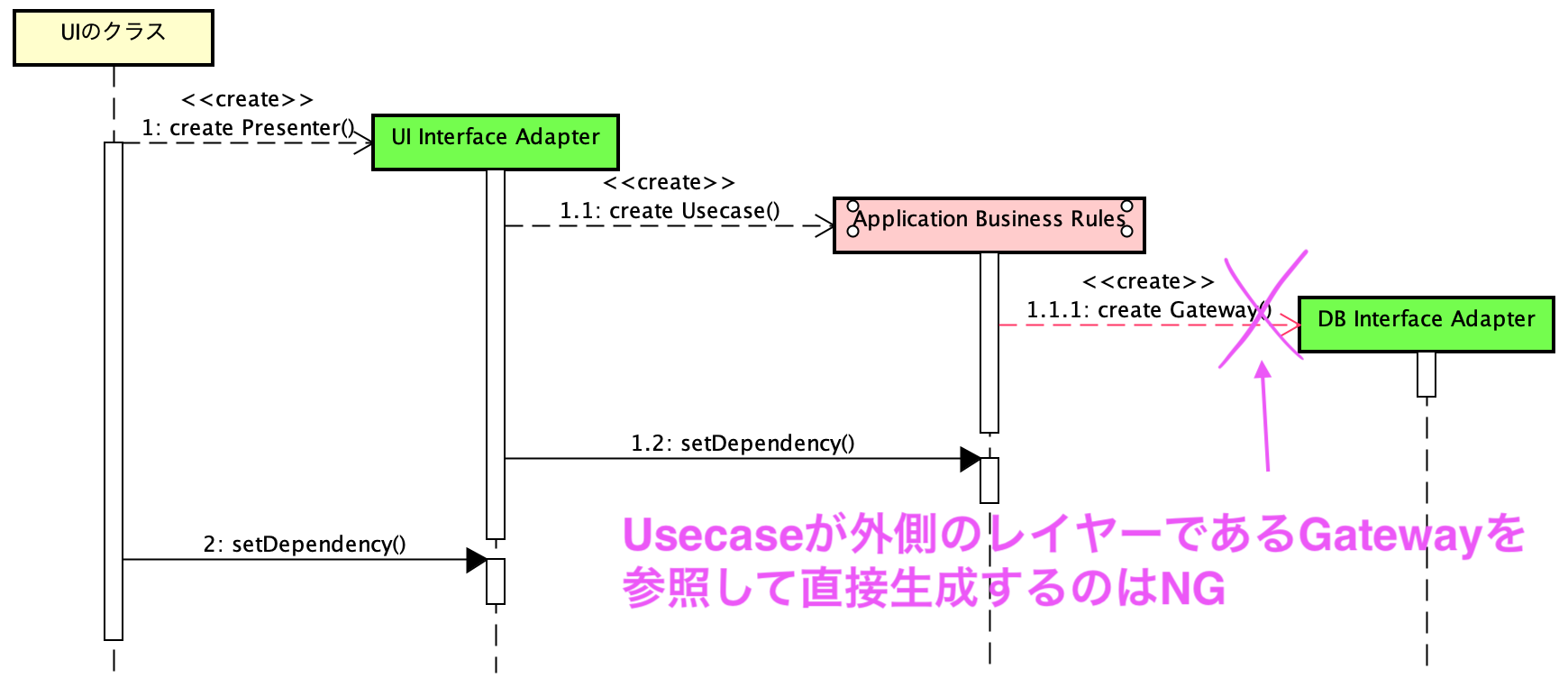
そのため、単純にUI側からのイベントをトリガーに全てのインスタンスを生成・依存性の注入をしようとすると依存関係のルールに縛られてUseCaseまでしか用意できない、という問題が発生します。オレオレclean architectureを実装してみた際、ここでつまづきました。
この問題については書籍で解決方法が提示されています。
依存を注入するタイミングはMain
書籍Clean Architecture曰く
Mainは、汚れ仕事が最もよく似合うコンポーネントだ
だそうです。つまり「Mainで依存の注入に必要な処理行え」とあります。
(汚れ仕事ってほどじゃ無いんじゃぁないかな、と思いますが。。。😅)
ここでいうMainは「アプリケーションのエントリポイント」のことになります。OSなどからそのアプリケーションを開始するために最初に呼び出されるポイントです。iOSやAndroidでは実際にはmainは開発者が実装できないのでAppDelegateやApplicationクラスのlife cycleメソッドが該当します。
また、もしテストを行う場合にはテストのエントリポイント(junitのtest runnerなど)で依存を解決させておくロジックを実装しておくことになります。
これにより、Usecaseの処理が呼び出された時にはすでにDB側の具象クラスに対する依存は解決済でUsecaseからInterfaceを通じて呼び出せる準備を整えることができます。
補足:依存の解決とインスタンスの生成
上記の記載の中では「インスタンスの生成」とは書かずに「依存の注入・解決」と書いています。DIコンテナが使える場合はあまり意識しないと思いますが、Factoryパターンなどを使う場合は先に「依存の注入」だけを行って必要に応じて「インスタンス生成」するパターンとそれらを同時に行うパターンがあります。
かなり雑ですが、以下は先に「依存の注入」だけを行うパターンです。
// これはUseCase層
interface DataStore {
String getFoo();
}
// これもUseCase層
class DataStoreFactory {
private static Class<? extends DataStore> storeClass = null;
// mainやアプリケーションのエントリポイントから「依存」だけを与える。
public static void setClass(Class clazz) {
storeClass = storeClass == null ? clazz : storeClass;
}
// このgetDataStore()が呼ばれるまでは「インスタンスの生成」はされない。
public static DataStore getDataStore() throws Exception {
return storeClass.getDeclaredConstructor().newInstance();
}
}
// ここから下はinterface adapter層
class MySqlDataStore implements DataStore {
public String getFoo() {
return "foo";
}
}
class TestDataStore implements DataStore {
public String getFoo() {
return "テストです";
}
}
一方、依存の注入とインスタンス生成を同時に行う場合は以下のようになります。getDataStore()は常に同じインスタンスを返します。DIコンテナなどで@SingletonとかasSingleton()とかする場合と同じですね。
class DataStoreFactory {
private static DataStore store = null;
// mainやアプリケーションのエントリポイントからインスタンス化したdatastoreを与える。
public static void setClass(DataStore ds) {
store = ds;
}
// このgetDataStore()が呼ばれる前にインスタンス化された、常に同じDataStoreを返す
public static DataStore getDataStore() throws Exception {
return store;
}
}
どちらのパターンを使うかはインスタンス化するものの特性によります。重要なのはUseCaseは具象クラスが何なのかはもちろん、インスタンス化のタイミングについても一切知らない状態をキープするということです。
自分の備忘録としての補足でした。
2. Streamを使うべきか?単なるmethodを使うべきか?
これは実際にClean architectureでクラス設計や実装しようとするとそれぞれの境界、とくにInterfaceAdapterとその1つ内側にApplication Business Rules層をどういう方法で繋げるか、という問題です。特にUsercaseからUIやDBなどの外側にデータを連携する場合、「依存性は"外→内"の原則を守りつつ、内側で作り上げたデータを"内→外"に流す」必要があります。
最近ではほとんどの言語でRxライブラリやSDKとしてstreamが提供されているので、何も考えずにStreamでやるってのもありですが、自分としてはちゃんとここを考えておきたいと思いました。
注:書籍のほうではこの点について何も言及されていませんので、ここからは完全に私の考えを整理しただけです。
繋げ方のパターン
1. Stream
Reactive Extension、通称Rxとして各種言語向けにStreamパターンを使えるライブラリが提供されています。言語によってはRxのライブラリを導入せずともstreamパターンを実装できる言語もあります。Dartとか。
Clean Architectureの文脈では、「依存性逆転」「スレッドの分離」に加え「フィルタリング」「値のキャッシュ」など豊富にあるStreamの機能・オペレータが魅力になります。
2. Observerパターン
RxでStreamが台頭してくる前からあるものとしてGoFにも含まれているObserverパターンが挙げられます。JavaのObservableなどがその実装で、Listenerを登録し、変更を伝える(notify)という方法です。
Clean Architectureにとって大切な「依存性逆転」「スレッドの分離」はObserverパターンでも容易に実装できますが、Streamのような値のキャッシュやフィルタリングなどは自実装していくことになります。
3. 単純なmethod
何の変哲もない普通にメソッドを呼び出す方法です。これだけでも「スレッドの分離」は簡単にできます。javascriptではasync付けるだけでできますしね。とはいえ「依存性逆転」は自実装でサポートする必要があります。
パターンまとめ
まとめるとこんな感じでしょうか。
|Stream|Observerパターン|単純なmethod
---|---|---|---
スレッド分離|ほぼ追加実装不要|追加実装要だが簡単|追加実装要だが簡単|
依存性逆転|正しく使えば追加実装不要|追加実装不要|そのための別の仕組みが必要
やりとりするデータクラスの生成、個々の値の変換|追加実装要だが簡単|そのための実装要*|そのための実装要*
クラス数(たぶん)|中|多|少
*編集作業の要件が少なければ簡単だが、フィルタリングや編集要件が多くなってくるとチリツモ。
UIとUsecaseの繋げ方
単純に考えれば、全てのUsecaseに向かってデータを渡す場合は、単純なmethodで十分です。Usecase側にinterfaceを切って適切なメソッドだけしか呼び出せないようにし、それを呼ぶ。ただし、UI→Usecaseの場合はスレッドの分離は必須です。とはいえ、それも簡単でJavaであればThreadにRunnable渡してstart()すれば良いだけです。毎回書くのが面倒なのであれば親クラスなどで処理を隠蔽すればよいだけであり、実現は可能です。
問題はUsecase→UIのデータフローの場合です。この場合はStreamが使えるならStreamを使った方が良いと思います。
理由はStreamの強みにも挙げた値のキャッシュがUIの初期表示のためには必須になるためです。StreamではBehaviorSubjectを使うだけでこれが実現できるし、dartのstreamにもlastなどが提供されています。都度「初期表示のためのデータくれ」というリクエストをUsecaseに求める方法も考えられますが、その場合「初期表示することもあれば、しないこともある」という前提が必要です。もし、そのシナリオで必ず初期表示を行うのであれば、それはもはやUsecaseレベルで認識しているべき事柄になると考えることができます。
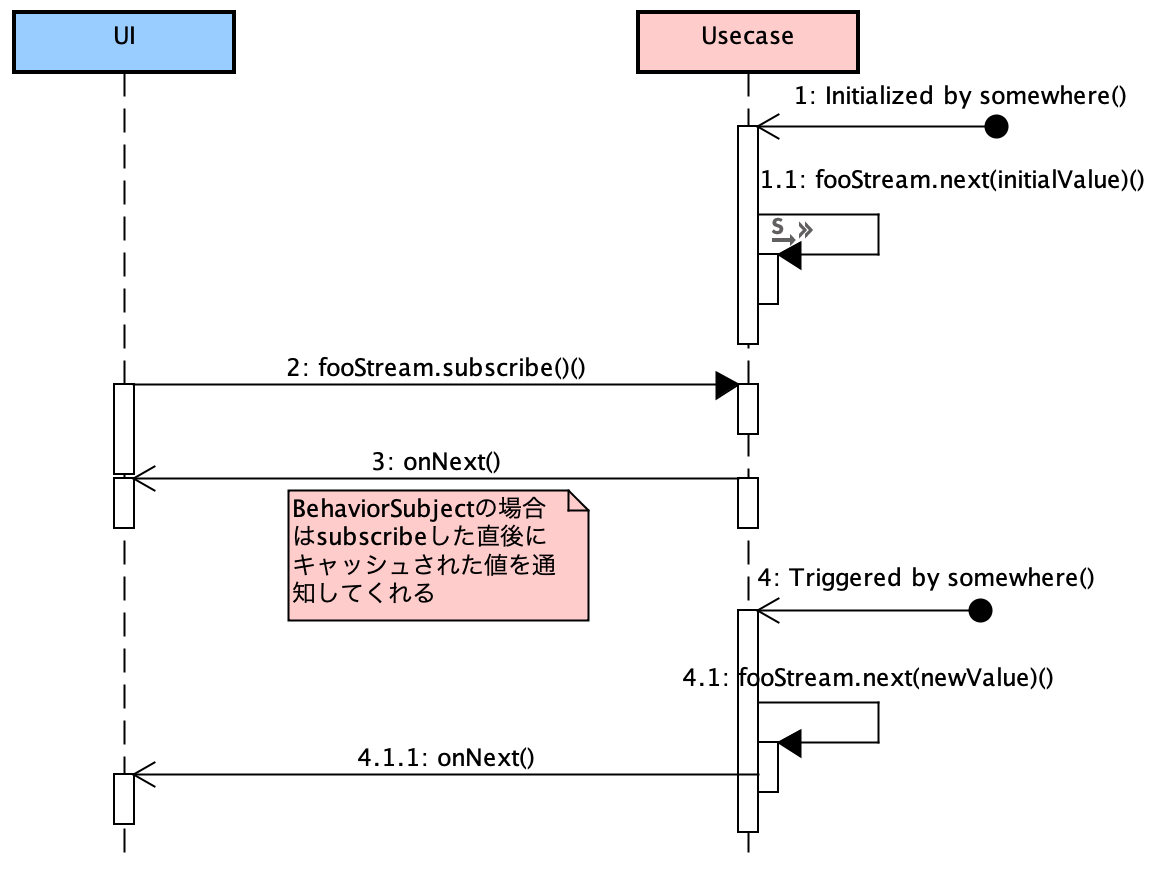
また、Streamを使うとオペレータにより値の編集処理もstreamの中に組み込みことができ、Interface Adapterの役割りの一つである外側の世界にあった形に編集するためのPresenterやGatewayといったクラスが不要になり、stream自体にその責務を与えることができます。
Streamが使えない場合はObserverパターンでしょう。キャッシュは自実装する必要がありますが、単純なmethodよりも依存性逆転が簡単に実装できるようになるため、Observableを継承したクラスを用意して変更通知するのか、callback listenerを登録しておいて所定のタイミングでそれらcallback listenerのメソッドを呼び出すのかはお好みですが、Observeパターンが次点になると考えられます。
DBなどUI以外の外側とUsecaseの繋げ方
ここの繋げ方は悩ましいところです。UIとUsecase(=ビジネスロジック)の間でスレッドが分離されていると、これまでよく言われていた「UIとHTTP通信は同じスレッドで処理しないようにしましょう!」というポイントはクリアしているため、DBやHTTP通信の処理のための専用スレッドを用意する強い動機はすでに無くなっています。
従って、「依存性逆転のしやすさ」「データ編集処理の差し込みやすさ」「クラス数の少なさ」などを考慮して良しなに選べば良いと考えられます。
ちなみに
そもそも「UIとHTTP通信は同じスレッドで処理しないようにしましょう」と言われていたのは「UIはHTTP通信よりも頻繁に更新やユーザからの操作を受け取りたいから」です。HTTP通信に時間がかかってもその間にGUIであればインジーケーターをアニメーションさせたり、CUIであっても.を点滅させたりして「今通信していますよ〜」とユーザに分かってもらい、何かの操作で通信をキャンセルできるUIを提供しようとすると、「通信の開始と終了の間隔」よりも「GUI描画やテキストのリフレッシュ間隔」を小さくする必要がある必要があります。それがスレッドを分け、並列処理を採用する動機になっていきます。
裏を返せば、HTTP通信がGUI描画間隔やテキストのリフレッシュ間隔よりも十分短いことが保証できるならば、同一スレッドで処理しても問題ないのです。(HTTP通信では無理だと思いますが、万が一保証できるなら、の話です)
とはいえ、アプリケーションによってはスレッド分離をしっかりと行う必要があります。例えば
- センサーから毎秒100回データを受け取る。
- ビジネスロジックとして何らかのアルゴリズムを使ってデータから計算結果を得る。
- センサーからの全てのデータと全ての計算結果をセットにしてDBに保存する。
という要件がある場合、ビジネスロジックとDB保存処理が毎秒100回=10msecよりも十分少ない時間で常に行えるなら同じスレッドで処理できますが、どうしてもビジネスロジック+DB保存が10msecを超えてしまうならスレッド分割を行うべきです。あるいは、今はぎりぎり10msec間隔で全て処理できるが、実は次世代のセンサーでは毎秒1000回データが取れるようになり、それを使うとビジネス的にメリットがあることが見込まれる場合などは、スレッドを分けておいた方が無難でしょう。
要するに、アプリケーションの要件をちゃんと見渡してスレッド分割の要否を考えましょうってことですね。
まとめ
今回はclean architectureを実装しようとするときの疑問点を整理しました。
やっぱり実装すると「あれ?ここどうやるのがいいんだ?」と思うところが色々出てきて勉強になるものですねぇ。
このエントリがどなたかの頭の整理に役立てば幸いです。