AA自動作成プログラムを作りました。
キーワード、URL、ファイルパスのいずれでも画像を渡せば自動でAAに変換します。
犯行動機
どうもこんにちは。
万年つまらない記事bot、私です。
先日、静かなるドン如き私の通知が珍しくオレンジになっておりました。
驚くべきことに、今を時めくジェイソンステイサムの熱心な愛好家さんからフォローを頂いたようです。
愛と勇気がつまった素敵な記事を書いていらっしゃるなと何度か拝見していたのですが、こちらの記事に宇宙No.1アイドルにこにーがスクショに写っていたので、俺もジェイソンステイサムの記事書くぞ!と一念発起致しました。(謎)
このタグ、流行ってほしい!
ジェイソンさんに関する余談
それはそうと、私も毎度ジェイソン様の映画を見ては三日間だけ筋トレをするぐらいに彼が好きです。 どれも好きなんですが一番好きなのはジェイソンステイサムの無駄遣いと言われた(?)SPYですかね笑 メカニックみたいなどちゃくそカッコイイのもいいんですが、アドレナリンとかみたいに脱ぐ!筋肉!爆発!胸毛!Fu●k off!!みたいなバカしてるのが好きです、個人的に。 ミニミニ大作戦やスナッチみたいに主役じゃなくても存在感半端ないですし何なら一番かっこいいですし、作品が引き締まるし緩まるし、ほんとにすごい人だなと思います。 洋画の話は僕の年だとあんま通じる人いなくて寂しいんですけどね…。ちなみに推しはブラットピットさんです。 べたですが超良作ですので`Fight Club`、ぜひ。
こんな駄記事でタグを汚して申し訳ない。 が、**[このタグ](https://qiita.com/tags/%e3%82%b8%e3%82%a7%e3%82%a4%e3%82%bd%e3%83%b3%e3%83%bb%e3%82%b9%e3%83%86%e3%82%a4%e3%82%b5%e3%83%a0)、流行ってほしい!**(二回目)
概要
PythonでAAを自動作成する記事はちらほらと見受けられます。
その辺りを参考にしつつ、PillowとNumpyで実装していきます。
参考その一・参考その二
AAとは
`AA`とは`ASCII Art`の略で、文字だけを使い描かれた絵のことです。 もともとインターネット上で今のように画像をやり取りできなかった時代に生み出されたものですが、現在でも住所がIPアドレスで職業が警備員の我々には馴染みのもので、凄い方が作ると  この様に輪郭を上手くとらえて線画として完成されます。 Pythonでもゴリゴリがんばればいけないこともないかと思ったんですが、しがない浪人生にそんな時間はありませんでしたので、今回は既存のものを踏襲して濃淡系と呼ばれる簡単な`AA`に取り組みます。 そもそも私の経験値はWeb寄りで`Python`は`P`の一画目の3pxも理解していないので濃淡系ですら大変でしたが…。 [線画調のAAに関する論文(!?)](https://www.jstage.jst.go.jp/article/iieej/35/5/35_5_435/_pdf)今回は濃淡系AAを描いていきます。
各ピクセルの輝度に最も近い文字を並べるだけで、最終的にはこんな感じのものができます。
横が80文字でちょうど小窓のターミナル分ですが、自由に調節して大きくもできます。
大きくすれば必然的に解像度も上がるので仕上がりも綺麗になります。
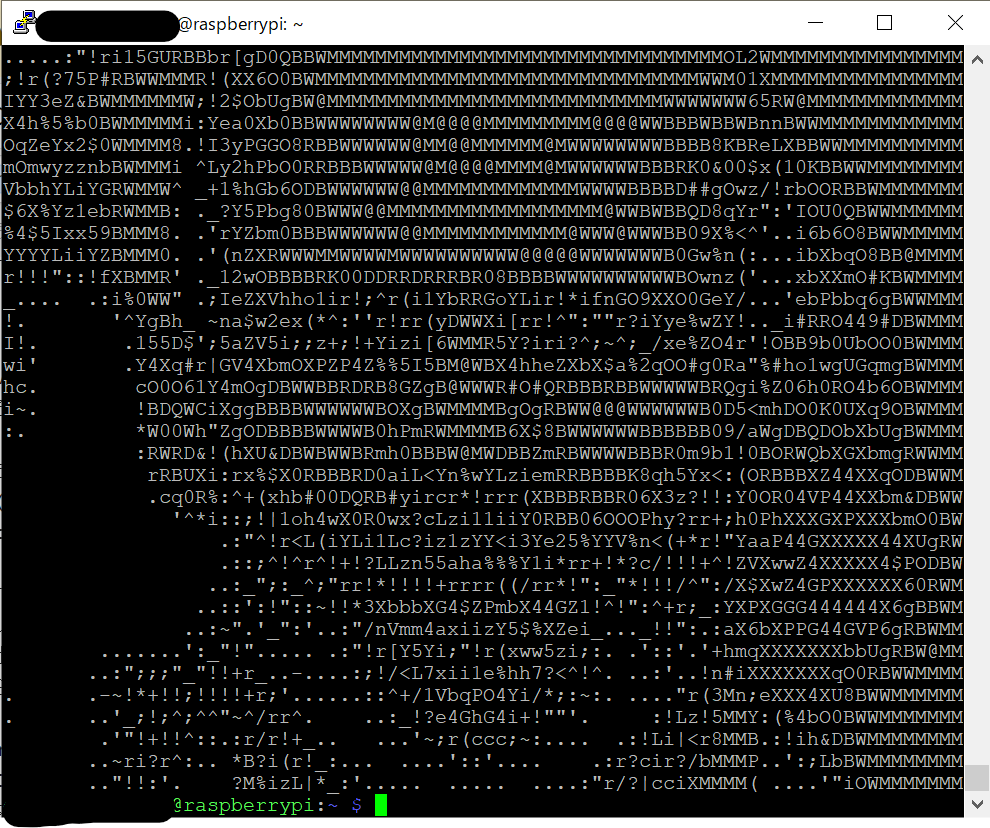
どうです?
疲れて手が止まった時にこれを見れば、ほら、あのイケメンな声が聞こえてきませんか?
What the f●ck are you doing? Get back to work or I will beat the shit out of you!
(脳内で勝手に再生された声ですからコンプライアンスなんて知りません)
元気百倍、お仕事バリバリ、社畜ちゃんいっちょ上がり~。
今回はそんな企画です。
にしても、AAで見てもかっこいいですねー。
環境
$ uname -a
Linux raspberrypi 5.4.51-v7l+ #1333 SMP Mon Aug 10 16:51:40 BST 2020 armv7l GNU/Linux
$ python -V
Python 3.7.3
$ pip list
Package Version
------------------- ---------
beautifulsoup4 4.9.2
numpy 1.19.2
Pillow 7.2.0
pip 20.2.3
requests 2.24.0
特徴
前述のように濃淡系AAの自動作成だけでしたら前例が在りつまらないので、幾つか手を加えました。
自分で言うのもなんですが、手軽に使えるようになったと思います。
-
キーワード、URL、ローカルファイルパスのいずれを渡してもAAが返ってきます。 - 上に関連して、Google画像検索を組み込んで画像を自動取得するようにしました。
- 文字割り当てアルゴリズム(?)を改良して再現度を高めました。
使いどころ?
CUIだと、パッと画像を確認したいときなんかでも一々`FTPで転送して~~`と手間が嵩んで不便だと感じます。 本プログラムがあれば、画像をAAで表示できて概観くらいなら掴めるかもしれないので便利ですね。(暴論) 個人的にLinuxはCUI以外許しませんおじさんなので(そんなこともないですが)、Linuxの白黒画面にコマンド一つでAAの華が咲くのは嬉しいです。 例えば`園田海未`とか渡せば海未ちゃんが微笑みかけてくれるんです。 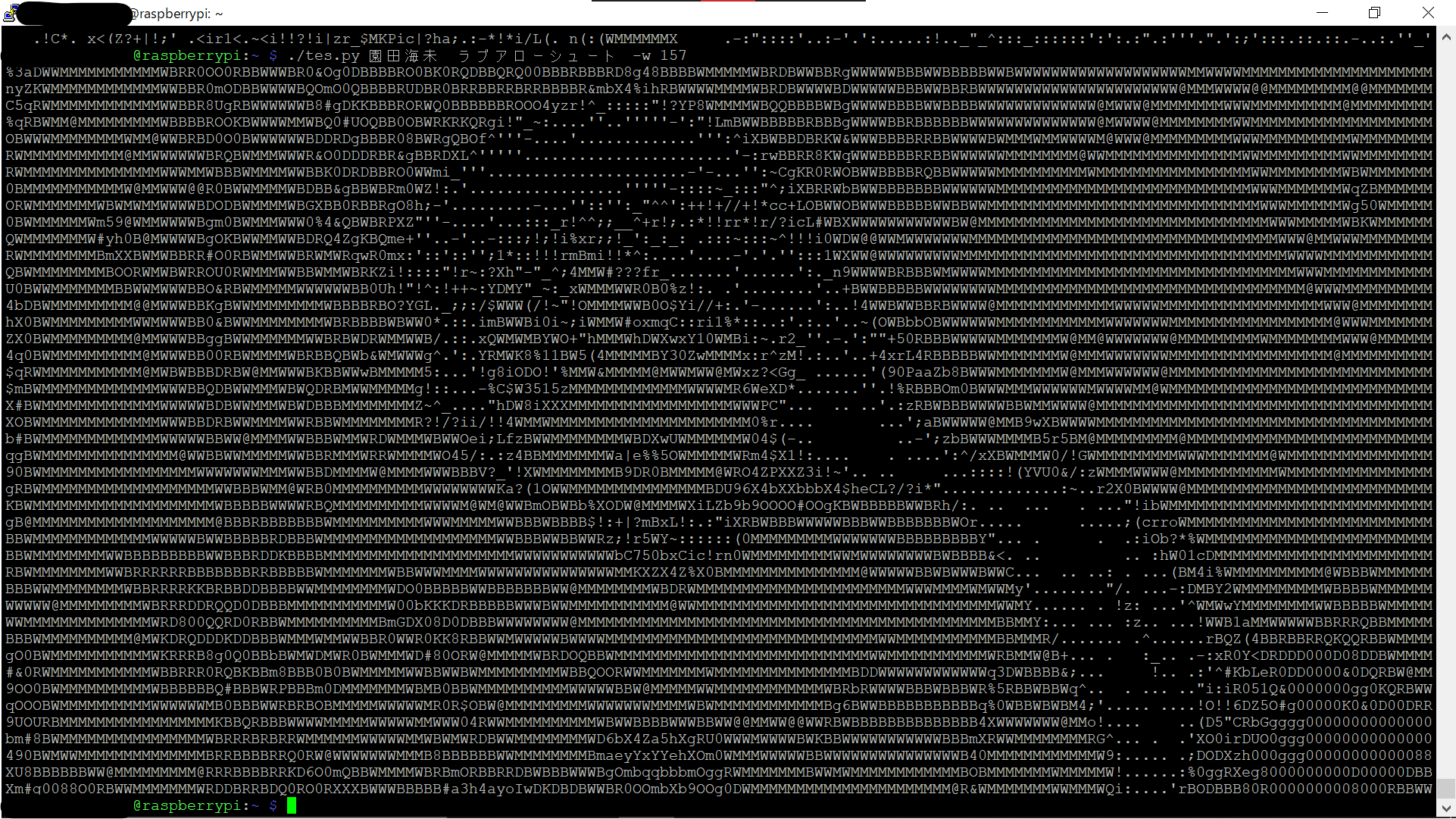 幸せでしょう??僕は幸せです。文字割り当てアルゴリズム体操
ピクセル輝度に応じて使用する文字を割り当てていきます。
今回使用する文字は互換性向上のために元祖ASCII文字だけとします。
- 各文字のピクセルが一定面積に対して占める割合を計算
- 文字の割合を正規化して0から255の256段階に変換し、これをマップとする
- 変換したい画像の各ピクセルをマップと比較して適切な文字を選択
from PIL import Image, ImageDraw, ImageFont # Pillowの読み込み
import numpy as np # numpyの読み込み
width = 80 # 横幅(文字数)
font = ImageFont.truetype('DejaVuSansMono.ttf', 16) # マップ作りに使用するフォント(ラズパイのデフォルト)
characters = list('!"#$%&\'(*+,-./0123456789:;<=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[^_`abcdefghijklmnopqrstuvwxyz{|~ ') # 使用する文字列(ASCII文字列)
img_gray = 'hogehoge.png' # 変換する画像
# 正規化関数(渡された数字のリストを0-255に正規化して返します)
def normalize(l):
l_min = min(l) # リスト内最小値
l_max = max(l) # リスト内最大値
return [(i - l_min) / (l_max - l_min) * 255 for i in l] # 各アイテムを正規化
# 密度計算関数(渡された文字のリストを{256段階密度:文字}の辞書配列にして返します)
def calc_density():
l = [] # 密度を入れる空配列を宣言
for i in characters: # 全文字分繰り返し
im = Image.new('L', (24,24), 'black') # グレースケールで24px*24pxの黒単色画像作成
draw = ImageDraw.Draw(im) # 作成した画像をImageDrowオブジェクトに
draw.text((0,0), i, fill='white', font=font) # 画像に白で文字を描画
l.append(np.array(im).mean()) # 文字が描画された画像の輝度平均を配列に追加
normed = normalize(l) # 各文字の輝度が入った配列を256段階に正規化
dict = {key: val for key, val in zip(normed, characters)} # {輝度:文字}の辞書配列にします
return sorted(dict.items(), key=lambda x:x[0]) # 辞書配列を輝度でソートして返します
maps = calc_density() # 各文字の輝度に関する辞書配列を取得
density_map = np.array([i[0] for i in maps]) # 輝度だけ取り出してnumpy配列に
charcter_map = np.array([i[1] for i in maps]) # 文字だけ取り出してnumpy配列に
imarray = np.array(img_gray) # 画像のピクセルごとの輝度をnumpy配列に
index = np.searchsorted(density_map, imarray) # ピクセルの輝度に最も近い輝度の文字を探して、そのインデックスをnumpy配列に
aa = charcter_map[index] # 上のnumpy配列で文字のnumpy配列をファンシーインデックス
ほぼ偉大なこちらの記事の丸パクリなんですが(申し訳ない)、文字を割り当てる時の動作を改善しました。
動作は少し重くなりますが、numpy.searchsorted関数を用いることで濃淡をより正確に表現できるようになっています。
結果として、画像などを変換した際に輪郭などが捉えやすくなります。
numpy.searchsorted関数は、第一引数に基準となる配列を、第二引数に対象を渡すと、基準となる配列から対象と一番近い要素のインデックスを返してくれます。1
基準となる配列がソートされている必要があり、返ってくるのがインデックスなので、マップ作成など周辺の処理は辞書配列を用いて無理くり実装しています。
輝度と文字の二つの配列を辞書型に変換してキー(輝度)で並べ替えた後、再び輝度と文字の二つの配列に分けてそれぞれ格納しています。
アプリケーションのように使うなら、この関数を廃止してマップは固定にしたほうが処理が軽くなって良いですね。
numpyで画像のピクセルごとの輝度を配列にして、numpy.searchsorted関数に渡すと輝度が近い文字のインデックスが格納された配列ができますので、それをファンシーインデックスで文字の配列にします。
これを任意の方法で書き出せばAAの完成となります。
Googleで画像検索→取得
Google先生にキーワードを投げて、スクレイピングで画像を引っ張ってきます。
どうせAAになるので画質はサムネ品質で十分ですから実装も簡単です。
ちなみに、Google先生には検索キーワードとしてq=keyword1+keyword2、画像検索指定はtbm=ischを渡せば良いです。
-
RequestsでGoogleの検索結果全体のHTMLを取得 -
<img>タグ(画像)をピックアップ -
src属性値(画像URL)を取得 - 取得した画像リンクから画像をダウンロード
- ダウンロードした画像を一時ファイルに保存
from bs4 import BeautifulSoup # htmlノードをいじるライブラリ
import requests # http通信を司ってくれる"人間向き"なライブラリ
import tempfile # 一時ファイルを管理するライブラリ
import re # 正規表現用ライブラリ
import sys # Pythonより上位の操作ができるライブラリ
# 画像検索・取得関数(渡されたURLを画像にして返す)
def get_image(destination):
try: # ローカルで完結しないのでエラーを想定して例外処理の組み込み
html = requests.get(destination).text # httpリクエストを送ってレスポンスをテキスト形式に
soup = BeautifulSoup(html,'lxml') # パーサーに優秀なlxmlを指定(エラーが出たらxmlで)
links = soup.find_all('img') # htmlのタグ<img>を探し出して全て抽出
for i in range(10): # 画像を拾えないことがあるので最大10回繰り返し
link = links[random.randrange(len(links))].get('src') # ランダムで<img>タグの"src"を一つ抽出
if re.match('https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', link): # 抽出した文字列がURLであることを確認
image = requests.get(link) # 抽出したリンク画像をダウンロード
image.raise_for_status() # リクエストのエラーを検出(404など)
break # 正常に取得できたのでループをぬける
elif i >= 9: # 10回繰り返したのでループを抜ける
raise Exception('Oh dear. Couldn\'t find any image.\nWhy don\'t you try with my name?') # 上位の例外にエラーをカスタムエラーを投げます
except Exception as e: # エラーをキャッチします
print('Error: ', e) # エラーメッセージを標準
sys.exit(1) # 終了コードを1(異常)で終了
fd, temp_path = tempfile.mkstemp() # 一時ファイルを作成
with open(temp_path, 'wb') as f: # 一時ファイルを開く
f.write(image.content) # 一時ファイルに画像を書き込み
return temp_path # 一時ファイルを返す
url = 'https://www.google.com/search?q=Jason+Statham&tbm=isch&safe=off&num=100&pws=0' # Google先生でジェイソンステイサム様の画像を検索
file_path = get_image(url) # 取得した画像のパスを変数に格納
とてもスムーズにスクレイピングができますね。
PHPで同様の実装をしたときは少し手間取ったので便利だと感じました。
注意点としては、requestsライブラリはHTTPレベルの実装なので、requests.get()を実行したときのレスポンスが404 Not foundでもエラーとはなりません。
ですが、スクレイピング的にはエラーですから自力で場合分けする必要があります。
幸い404などの200代以外のステータスコードは全て異常とみなせますから、raise_for_status()という便利な関数をレスポンスにかけると200代ではないステータスコードの際にエラーを上げてくれます。
そちらのエラーをexceptで拾い、番号で場合分けすればよいことになります。
徒然なるままに
アプリ的な利用ができるようにちょこちょこと弄りました。
jason2aa.py -hとするとヘルプが表示されます。
Okey, here is the fuckin' help.
Usase: jason2aa.py keyword keyword .. [option]
[Options]
-w Width of AA (The number of characters)
-p Path to image file
-b Return Black and white reversed image
-h Show this help (or -help)
If I was you, I'm sure I can handle such a bullshit app without the help.
Because, I'm a true man.
ジェイソンステイサムライクと語っているので、「騙って」とならないようにメッセージなんかを僕の脳内ジェイソンステイサムに協力してもらいました。
ぜひ色々とエラーを吐き出させてみてください。
例えば画面幅としてint()ではないものを渡すと
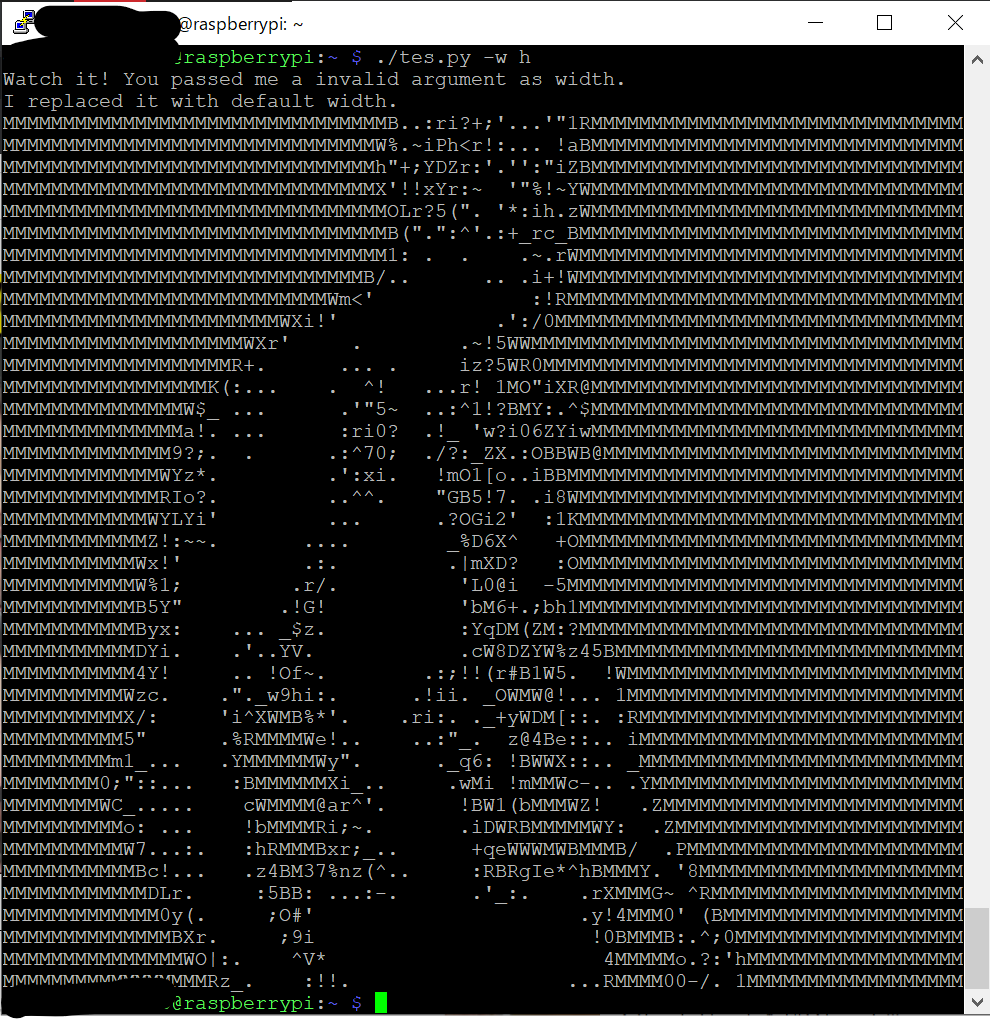
こんな感じに返してきます笑
検索ワードやパスが渡されない場合は勿論ジェイソンステイサムの画像が返ってきます。
幅は標準でターミナルのウィンドウサイズ全幅になるようにしてあります。
こちらの記事を参考にしてos.get_terminal_size().columnsで実装してあります。
読み込むライブラリを減らしたかったのでosで実装しました。
渡されたパスは極力エラーの出ないように処理していますが、エラーになってたら教えてください。
白黒反転も導入しました。
ターミナルでの使用を想定していますが、Webなどに書き込むときは白背景が基本ですから-bオプションで反転するようにしてあります。
画像処理
濃淡系AAで仕上がりをよくするためにはコントラストを上げる必要があります。
コントラストが低いと黒(スペース)と白(M)を使いきれず、輪郭がはっきりしません。
AAは濃度の表現段階数が少ないので、輪郭がはっきりしないと何の画像か分からなくなってしまいます。
今回はモジュールの関係で、単純にコントラストを上げてからグレースケール化しましたが、グレースケールに変換する際に濃淡をはっきりさせる手法も良さそうです。
cont = ImageEnhance.Contrast(img) # PillowのEnhancerオブジェクトを生成
img_gray = cont.enhance(2.5).convert('L') # コントラストを二倍に強調し、グレースケールに変換
奥が深いグレースケール
[こちらの記事](https://qiita.com/yoya/items/dba7c40b31f832e9bc2a)に詳しいですが、一口にグレースケールといっても色々な変換方法があるそうです。  左が`Pillow`でグレースケール化したもの、右が`OpenCV`の**退色処理**でグレースケール化したものです。 この画像では違いが分かりにくいですが、スーツとYシャツのあたりを見ていただくと右のほうが**白黒が強調**されているのが分かるでしょうか。 右のものはコントラストを維持することに着目した手法だそうで、単純に言えばグレースケール化とは人間の色感覚を白黒の濃淡で表そうとしたものですが、機械が認識するには**人間の感覚よりコントラストを維持**するほうが適しているのだそうです。 この辺りは掘り進めると画像認識などとかかわりが深そうで興味深いです。 僕の中でタイムリーな画像認識と言えば`アイサイト`ですが、あれはとても複雑な処理を行っているのでしょうね。 とは言えこうして画像処理の末端の末端に触れてみると、その複雑な処理も突き詰めれば単純にパラメータの調整なのかとも思ったりもします。 単純であるからこそ、周辺のプログラムも含め、当に何十年にもわたって蓄積された経験の賜物としか言えぬ素晴らしい技術なのでしょう。全文
ライブラリさえ用意しておけばコピペで動くと思います。
需要があるかは知りませんがGitHubにも上げておきました。
ターミナルに華を咲かせたい!って人は使ってみてください。
# !/usr/bin/python3.7
from PIL import Image, ImageDraw, ImageFont, ImageEnhance
from bs4 import BeautifulSoup
import numpy as np
import requests
import tempfile
import os
import re
import sys
import random
is_direct = False
is_local = False
background = 'black'
color = 'white'
width = os.get_terminal_size().columns
font = ImageFont.truetype('DejaVuSansMono.ttf', 16)
characters = list('!"#$%&\'(*+,-./0123456789:;<=?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[^_`abcdefghijklmnopqrstuvwxyz{|~ ')
def get_image(destination):
try:
html = requests.get(destination)
html.raise_for_status()
soup = BeautifulSoup(html.text,'lxml')
links = soup.find_all('img')
for i in range(10):
link = links[random.randrange(len(links))].get('src')
if re.match('https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', link):
image = requests.get(link)
image.raise_for_status()
break
elif i >= 9:
raise Exception('Oh dear. Couldn\'t find any image.\nWhy don\'t you try with my name?')
except Exception as e:
print('Error: ', e)
sys.exit(1)
fd, temp_path = tempfile.mkstemp()
with open(temp_path, 'wb') as f:
f.write(image.content)
return temp_path
def normalize(l):
l_min = min(l)
l_max = max(l)
return [(i - l_min) / (l_max - l_min) * 255 for i in l]
def calc_density():
l = []
for i in characters:
im = Image.new('L', (24,24), background)
draw = ImageDraw.Draw(im)
draw.text((0,0), i, fill=color, font=font)
l.append(np.array(im).mean())
normed = normalize(l)
dict = {key: val for key, val in zip(normed, characters)}
return sorted(dict.items(), key=lambda x:x[0])
arg = sys.argv
if '-h' in arg or '-help' in arg:
print(' Okey, here is the fuckin\' help.\n'
'\n'
' Usase: jason2aa.py keyword keyword .. [option]\n'
'\n'
' [Options]\n'
' -w Width of AA (The number of characters, less than 10000)\n'
' -p Path to image file\n'
' -b Return Black and white reversed image\n'
' -h Show this help (or -help)\n'
'\n'
' If I was you, I\'m sure I can handle such a bullshit app without help.\n'
' Because, I\'m a true man.')
sys.exit(0)
if '-b' in arg:
b_index = arg.index('-b')
for i in range(1):
arg.pop(b_index)
background = 'white'
color = 'black'
if '-w' in arg:
w_index = arg.index('-w')
try:
w_temp = int(arg.pop(w_index + 1))
if w_temp > 0 and w_temp < 10000:
width = w_temp
else:
raise Exception
arg.pop(w_index)
except Exception:
print('Watch it! You passed me a invalid argument as width.\nI replaced it with default width.')
for i in range(1):
arg.pop(w_index)
if '-p' in arg:
p_index = arg.index('-p')
try:
path = arg.pop(p_index + 1)
arg.pop(p_index)
if re.match('https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', path):
try:
image = requests.get(path)
image.raise_for_status()
fd, temp_path = tempfile.mkstemp()
with open(temp_path, 'wb') as f:
f.write(image.content)
is_direct = True
file_path = temp_path
except Exception as e:
raise Exception(e)
else:
if os.path.exists(path):
is_local = True
file_path = path
else:
raise Exception('There ain\'t any such file. Are you fucking with me?')
except Exception as e:
print(e, '\nThe above error blocked me accessing the path.\nBut, don\'t worry. Here is the my photo.')
url = 'https://www.google.com/search?q=Jason+Statham&tbm=isch&safe=off&num=100&pws=0'
file_path = get_image(url)
else:
if len(arg) <= 1:
arg = ['Jason', 'Statham']
else:
arg.pop(0)
url = 'https://www.google.com/search?q=' + '+'.join(arg) + '&tbm=isch&safe=off&num=100&pws=0'
file_path = get_image(url)
for i in range(10):
try:
img = Image.open(file_path)
except Exception:
print('Oh, fuck you! I couldn\'t open the file.\n'
'It\'s clearly your fault, cuz the path wasn\'t to image file.\n'
'But, possibly, it\'s caused by error like 404. Sorry.')
sys.exit(1)
if img.mode == 'RGB':
cont = ImageEnhance.Contrast(img)
img_gray = cont.enhance(2.5).convert('L').resize((width, int(img.height*width/img.width//2)))
break
elif is_local or is_direct:
print('Shit! I could only find only useless image.\nYou pass me files containing fuckin\' alpha channel, aren\'t you?.')
sys.exit(1)
elif i >= 9:
print('Damm it! I could only find only useless image.\nMaybe, fuckin\' alpha channel is contained.')
sys.exit(1)
else:
os.remove(file_path)
file_path = get_image(url)
maps = calc_density()
density_map = np.array([i[0] for i in maps])
charcter_map = np.array([i[1] for i in maps])
imarray = np.array(img_gray)
index = np.searchsorted(density_map, imarray)
aa = charcter_map[index]
aa = aa.tolist()
for i in range(len(imarray)):
print(''.join(aa[i]))
if not is_local:
os.remove(file_path)
sys.exit(0)
まとめ
未熟者ですので初めてPythonをまともに弄りました。
とても使いやすくて親しみやすい言語で、楽しく書くことができました。
AAの自動作成なんてWebを探せばいくらでも出てきますが、自分で作ってみると割り当ての工夫など違った視点で見えてきて面白かったです。
また時間のある時にCV2や輪郭検知なんかをゴリゴリ駆使して線画系のAAも書いてみたいなと思います。
なにかアドバイスやご指摘がありましたらお教えいただけると幸いです。
最後までお読みいただきありがとうございました!