
本記事は、QiitaのGraphQL Advent Calendar 2018の3日目の記事になります。
Self-Intro / 自己紹介
まずは、自己紹介をさせて頂きますと私はウェブ系の受託業務をやっている普通のプログラマですが、週末はUdemyのコース作成やサポート、あるいはYouTuber活動をやっていたりします。今年は私にとってはUdemy元年でした。有り難いことに、ReactとGraphQLの2つのコースをリリースさせて頂き多くの方に受講頂いております。(皆様もUdemyの講師を始めてみませんか?と調子に乗って宣伝してみたり。。。)また、このQiitaさまにも掲載されている広告等からもご購入頂いた事例もあり、そういう意味ではQiitaさまにも大変お世話になった有り難い1年となりました。そして、2019年もどうぞ宜しくおねがい致します。
Format and Assumption / 本記事の形式及び前提について
というわけで、早速やっていきたいのですが、本記事の形式は、実際に私がUdemyのGraphQLのコースの中で扱っている実際のレクチャーである「ページネーション」からの転載という体で掲載させて頂きます。従いまして、文体がレクチャー形式になっており、また、文章も実際に使用したスクリプト(台本)になりますので、普段ブログを読み慣れている方からすると若干違和感を感じられるかもしれませんが、記事の内容に触れる前に、まずは形式をきちっと定めているという点は、GraphQLの記事らしいな、みたいな感じで大目に見て頂けると幸いです。
お願い
本記事は動画の台本の転載になりますので、動画ありき文章となり、口語調だったり、あるいは映像ありきの説明になっている箇所が多々あります。例えば、本動画の中でも登場するGraphiQLエディター上の操作等については文字だけでは非常に分かりづらい内容となっています。かといって文字起こしするもの非常に非合理です。そのため、もし動画を閲覧できる環境でしたら、記事の中にも埋め込んでいますYouTubeのリンクから実際のUdemyでも使用している動画も一緒にご覧頂きながらご視聴頂けるのが一番良いかと思いますので、本当にお手数をおかけし恐縮ですが宜しくお願い致します。
Which Pagination We Will Go with? / どのページネーションで行くか?
GraphQLでは、言語仕様としては、ページネーションの方法として、こういう方式でなければならないといった決まりは全くなく、実装依存になります。つまり、「おれおれページネーション」っていうのを発明して、このサービスではこんなページネーションの実装になっていますので、「みなさん、どうぞこんな風にしてお使いください!」といった感じで独自の方式で実装することもできなくはないです。しかしながら、APIというはそもそも、多くの人に使ってもらうために存在するものというのが大前提ですし、使いやすいものでなければAPIを開発して公開する意義が薄れてしまいます。そのため、ページネーションの方式としては、デファクトスタンダードとか、ベストプラクティスといった、事実上標準化されているものがあれば、それに従っていくいくのが現実的なソリューションになるかと思います。というわけでですね、GraphQLで実用化されているページネーションの最も有名な方式の1つに、「Relay-style cursor pagination」というページネーションの方式があります。
その方式についてこれから学習していこうと思うのですが、その理由としては2つあります。
まず1つ目。このRelay-style cursor paginationなんですが、 GitHubのGraphQL APIでも採用されているページネーションの方式であること。これがまず1つめの理由です。
そして、2つ目の理由としては、このページネーションもGraphQLと同様に、Facebookが考案したものであり、最も実装に用いられているページネーション手法の1つと言われているからです。この2つが採用理由になります。
Let's See a Normal Pagination - 通常のページネーションについて
ではですね、まずは、ウォーミングアップとして、一般的なページネーションについておさらいをしておきましょう。新しいタブを開いて、ブラウザ検索で、GraphQLで検索してみましょう。すると、検索結果として、 大量の検索結果が画面上に表示されると思います。そしてですねこの検索結果の画面を画面の一番下までスクロールしていきますと、ご覧のようにですね1、2、3、4、5、6、7、8、9、10、そして、Nextという形ですね、ページの番号が表示されます。そして、それぞれのページ番号がリンクになっていて、さらにその先の検索結果のページに遷移できるようになるというものが、みなさんがよくご存じのページネーションになるかと思います。
Let's See the Relay-Style Cursor Pagination - Relay-style cursor paginationについて
はい、ではですねRelay-Style Cursor Paginationが一体どんなものなのかについて、詳細に見ていくことにしましょう。まず、こちらの図を御覧ください。
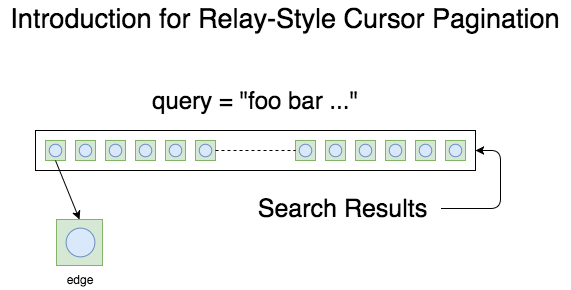
こちらに示している図は、Relay-Style Cursor Paginationの概念図になります。
先程ブラウザでGoogle検索を行ったときの様にですね、そもそもページネーションというのは、大量のデータが存在するときに、小さい単位、例えば10件とか、20件とか100件とかの単位、つまり、ブラウザに快適に表示できうる件数分のデータを1つのページ上に表示していくというのが、ページネーションのそもそもの機能になります。こちらの図で示した、Search Resultsが検索結果になります。この検索結果には大量のデータが含まれています。そして、こちらの正方形の形をしたものがですね、1件分のデータに該当します。これは、GraphQLのページネーションの世界ではedgeと呼ばれています。このデータをブラウザはサーバに対して要求するわけなんですが、大量のデータを分割してブラウザに対して配信する場合にちょっとした工夫が有るわけです。
では、次の図を御覧ください。

こちらに示しているのが、GitHubのGraphQL APIで実現しているRelay-Style Cursor Paginationの詳細なイメージ図になります。こちらのですねサーバーと書かれている部分にはですね、たくさんのデータが並んでいます。そしてですね、全てのデータはデータベースというものに格納されています。そして下の方に行きますと、クライアントが存在します。クライアントは適宜サーバーに対してデータの要求を行います。実際にはですね全てのデータをクライアントが一気に受け取ることは不可能になりますので、ここで、ページネーションという仕組みを用いてですね、ある塊単位にデータを要求するという行為を行っているわけですね。その塊のことをこのRelay-Style Cursor Paginationでは、connectionと呼んでいます。そして、このconnectionが示すもろもろの情報の集まりをpageと呼びます。pageは、edgeの集まりであるedgesとpageInfoの2つで構成されています。edgeには、ご覧のようにですね、位置情報を示すcursor、そして、情報そのモノであるnodeの2つで構成されています。このnodeは、インラインフラグメントのレクチャーで登場したnodeと全く同じものになります。nodeは、データを抽象化した呼び名でしたね。
そして次に、pageInfoの方ですが、これは文字通り、ページに関する情報が含まれています。具体的には、4つの情報が含まれています。
- startCursor
- endCursor
- hasPreviousPage
- hasNextPage
です。
先ほどですね、pageにはedgeの集まりが含まれていますと言いましたが、そのedgeの集まりの先頭のedgeの持つcursor情報はstarCursorに、そして、最後尾のedgeの持つcursor情報はendCursorに格納されています。そして、hasPreviousPageは、前のページが存在するかどうか、そして、hasNextPageは、まだ後続のページが有るかどうかについて真偽値で示されています。
では次に、 3つのユースケースに基づいてですね、実際にpaginationに関わるqueryを作成して実行してみようかと思います。まず、想定するユースケースを3つ紹介します。
まずは、Case 1です。

Case 1は、最初のページを要求する場合です。こちらはですね、具体的にはある検索クエリーを初めて送信する場合を想定しています。初めての検索になりますので、取得するべきページの情報は1ページ目に関するものになります。なのでですね、pageInfoのhasPreviousPageは当然falseになるでしょうし、該当のページが多い場合で後続のページがある場合は、hasNextPageはtrueになるという想定です。そして、検索結果の各edgeの示す、startとendのCursor情報が得られるという形になります。当然、このケースにおける要求に渡す変数には、検索文字列や検索結果の数といった数値を渡す必要があります。これがCase 1です。
続いてCase 2にいきましょう。

Case 2は、次のページを要求する場合を想定するケースになります。Case 1を実行した結果、hasNextPageがもしもtrueだった場合、次のページが存在しますので、具体的にはページ上には、nextページに遷移するための、nextボタンを表示することになると思います。ちょっと、こちらはデモページでご覧頂きたいのですが、
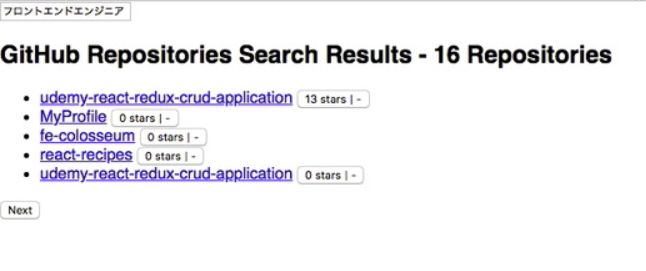
このページではですね、「フロントエンドエンジニア」という文字列で検索を行った結果、16件のリポジトリ情報が見つかって、そのうち、5件分のデータを取得して表示している画面になります。この場合はですね、次のページにも遷移するためのnextボタンというのが必要になってきますが、まさに、このnextボタンの表示の要否の判定に使用することになるものというイメージです。
では、図の方に戻ります。
先程のnextボタンをクリックすることで得られる情報としては、hasPreviousPage、つまり、前のページ情報があるかどうかについてはtrueになるはずです。またですね、さらに後続のページがある場合はですねhasNextPageが引き続きtrueになる想定です。Pageには当然Case 2においてもですね、開始と終了のcursor情報が必ず存在します。こういったpageInfoが得られるのはですね、送信するqueryの変数にですね、検索文字列や件数情報のfirstが必要となるのはもちろんですが、肝となるのはですね、afterに渡しているこちら、"Y3Vyc29yOjU="という文字列になります。これはですね、cursor情報になります。これはどこからきているのかというとですね、Case 1のendCursorから来ています。
Case 1の図をみてみましょう。はい、確かに同じ文字列ですね。
これを渡すことで何が解決しているかというとこのカーソル情報を受け取ったサーバサイドは、検索文字列である、「フロントエンドエンジニア」で検索をかけるわけなんですがafterで指定されたcursor情報、つまり位置情報を元にですね、これよりも後のデータを5件分取得する必要があるんだなという判断に用いることができるわけですね。そうすることで、次のページに関連するedgeの一覧が整理できるということになります。
はい。そして最後にCase 3の紹介です。
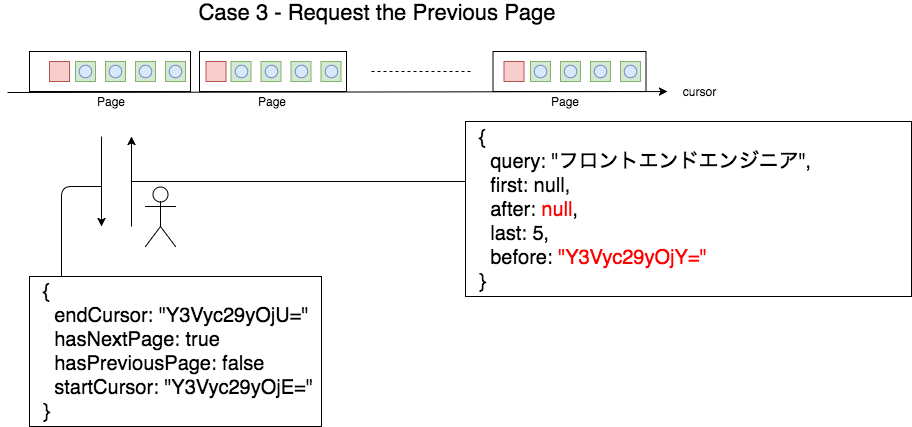
こちらはですね、今までのCase 1とCase 2の認識がしっかりあればですねさほど難しくはないです。Case 3はですね、Case 2の逆方向となる、前のページを要求する場合の想定です。こちらの図で示しているようにですね、前のページへの遷移には、Case 2と同様にcursor情報が必要となります。検索に与える情報は、Case 2と逆方向なので、Case 2のstartCursorである、Y3Vyc29yOjY=をbeforeにそして、件数を示す数値をlastに与えることでqueryに与える情報としては完成します。そして、このqueryを送信することで取得できるpageInfoの情報は、もしこれが1ページ目であればhasPreviousPageがfalseになりますし2ページ目以降であればhasPreviousPageはtrueになります。前のページにさかのぼっているので、必ずhasNextPageはtrueになります。また、startCursorやencCursorはそれぞれ開始と終了のedgeのcursor情報を示します。
はい、ではですね、Case 1の場合を想定した検索queryを実際にGitHub API Explorerで実行してみることにしましょう。
こちらのGitHub GraphQL API Explorerの画面を開きます。まずは、documentationを開いて、Queryをクリックして、searchというfieldを探します。一番下にスクロースするといると思います。今回はREPOSITORY検索を行うsearchを実行してみたいと思います。なので、引数一覧をコピーして、QUERY VARIABLESにペーストします。
{
"first": 5,
"after": null,
"last": null,
"before": null,
"query": "フロントエンドエンジニア"
}
そして、typeは常にREPOSITORYになるので、type以外のパラメータを設定してみます。firstは取得件数になります。今回は5と設定します。1ページ目なのでafterやlastやbeforeはnullになります。そして、検索文字となるqueryにはフロントエンドエンジニアを与えます。これで、QUERY VARIABLESの完成です。では、graphql editorの方に行ってですね、queryを作成します。
query searchRepositories($first: Int, $after: String, $last: Int, $before: String, $query: String!) {
}
query とかいて、スペース、そしてsearchRepositoriesというオペレーションネームを付けます。引数には、QUERY VARIABLESで指定したもの全てを列挙します。
query searchRepositories($first: Int, $after: String, $last: Int, $before: String, $query: String!) {
search(first: $first, after: $after, last: $last, before: $before, query: $query, type: REPOSITORY)
}
続いてsearchフィールドの指定です。引数にはDocumentationで指定されている全てを書きます。typeにはREPOSITORYを指定します。では、Documentationに行ってですね、返却フィールドの指定を行いたいと思いますので、SearchResultItemConnectionのリンクをクリックします。ここからページネーションに関わるfieldを選定してgraphqlのコードに組み込みたいのですが、必須となるのは、pageInfoとedgesです。あと、参考情報としてrepositoryCountもおまけで付けておきましょう。では、まずはpageInfoからですね。pageInfoは、paginationを助ける情報とあります。Pageinfoのリンクをクリックします。すでに学習済みの用語が羅列していますが、これらは全てページネーションを実現する上で必須となるfieldになりますのでgraphqlのコードにも実装していきましょう。では、pageInfoを追加しますね。
query searchRepositories($first: Int, $after: String, $last: Int, $before: String, $query: String!) {
search(first: $first, after: $after, last: $last, before: $before, query: $query, type: REPOSITORY) {
pageInfo {
endCursor
hasNextPage
hasPreviousPage
startCursor
}
}
}
では、実行ボタンをクリックしてみましょう。
{
"data": {
"search": {
"pageInfo": {
"endCursor": "Y3Vyc29yOjU=",
"hasNextPage": true,
"hasPreviousPage": false,
"startCursor": "Y3Vyc29yOjE="
}
}
}
}
実行すると、応答が返ってきましたね。edgesの指定はまだ行っていないため、各検索結果の具体的な情報は無いもののpageInfoにより、ページの概要が取得できました。今回のqueryでは、1ページ目の情報が取得できました。なので、hasPreviousPageはfalseとなっています。良さそうですね。そして、hasNextPageはtrueとなっています。今回の検索文字列「フロントエンドエンジニア」でリポジトリ検索をすると6件以上のリポジトリが存在するということがこのpageInfoから推測できます。では、repositoryCountについても追加して実行してみましょう。実行すると、ご覧のようにrepositoryCountが16となっていますから、トータルで16件分のnode情報がバックエンド側に存在するということになりますね。
では、次にpageInfoに引き続き、edgesフィールドの指定を行っていきたいと思います。Documentationのedgesを参照します。edgesはedgeの一覧です。とありますね!では、このedges、配列になっているこちらのSearchResultItemEdgeのリンク先をみてみましょう。このSearchResultItemEdgeは、cursorとnodeとtextMatchesなどが指定できるということなんですけれどもpaginationに必須となるのは、位置情報を示すcursorと検索結果そのものの情報を示すnodeの2つとなります。nodeはオブジェクト型のSearchResultItem型という型になります。このSearchResultItemはinline fragmentのレクチャーでも学んだ型になります。SearchResultItemをクリックします。inline fragmentのレクチャーでは、typeをUSERと指定しましたが、今回はtypeをREPOSITORYと指定していますのでRepositoryの内容を見ていきます。Repository型をクリックします。はい、今ご覧頂いているのがRepositoryの情報として取得できるフィールド一覧になります。今回はですね、id、name、urlの3つを指定したいと思います。それぞれ見ていきましょう。まずidですね、idはID型のフィールドになります。次にnameです。nameは文字列型のフィールドですね。そしてurlです。urlはURI型のフィールドです。
では、edgesについて実装しますね。
query searchRepositories($first: Int, $after: String, $last: Int, $before: String, $query: String!) {
search(first: $first, after: $after, last: $last, before: $before, query: $query, type: REPOSITORY) {
repositoryCount
pageInfo {
endCursor
hasNextPage
hasPreviousPage
startCursor
}
edges {
cursor
node {
... on Repository {
id
name
url
}
}
}
}
}
edgesには、cursorとnodeを指定しますね。そして、nodeは、Repositoryのidとnameとurlを指定したいと思います。nodeのフィールドの指定はRepositoryをinline fragmentで展開して指定します。はい、ここまでできたら実行ボタンをクリックしますね。
{
"data": {
"search": {
"repositoryCount": 16,
"pageInfo": {
"endCursor": "Y3Vyc29yOjU=",
"hasNextPage": true,
"hasPreviousPage": false,
"startCursor": "Y3Vyc29yOjE="
},
"edges": [
{
"cursor": "Y3Vyc29yOjE=",
"node": {
"id": "MDEwOlJlcG9zaXRvcnkxMjM5NTA3MjU=",
"name": "udemy-react-redux-crud-application",
"url": "https://github.com/gipcompany/udemy-react-redux-crud-application"
}
},
{
"cursor": "Y3Vyc29yOjI=",
"node": {
"id": "MDEwOlJlcG9zaXRvcnkxMTI5MjQwOTk=",
"name": "MyProfile",
"url": "https://github.com/kuro-channel/MyProfile"
}
},
{
"cursor": "Y3Vyc29yOjM=",
"node": {
"id": "MDEwOlJlcG9zaXRvcnk4MDgwMzYyOQ==",
"name": "fe-colosseum",
"url": "https://github.com/wakamor/fe-colosseum"
}
},
{
"cursor": "Y3Vyc29yOjQ=",
"node": {
"id": "MDEwOlJlcG9zaXRvcnkxMzMwNjMxOTE=",
"name": "react-recipes",
"url": "https://github.com/ProgrammingSamurai/react-recipes"
}
},
{
"cursor": "Y3Vyc29yOjU=",
"node": {
"id": "MDEwOlJlcG9zaXRvcnkxNDIzNDgzNDM=",
"name": "udemy-react-redux-crud-application",
"url": "https://github.com/uni51/udemy-react-redux-crud-application"
}
}
]
}
}
}
ご覧のようなjson データが返ってきました。そして、各edgeにはcursorとnodeが確認できます。cursorはbase64でencodingされているようなので、パット見妥当なものなのかどうかは判断しがたいんですが、順番に、cursor:1、cursor:2、cursor:3、というような文字列が格納されています。はい、その証拠にですねこちらのrepl.itで今回得られたcursorをdecodeしてみて中身が妥当なものなのかどうかを参考までに覗いてみることにしましょう。
const cursors = [
'Y3Vyc29yOjE=',
'Y3Vyc29yOjI=',
'Y3Vyc29yOjM=',
'Y3Vyc29yOjQ=',
'Y3Vyc29yOjU='
]
const results = cursors.map(cursor => new Buffer(cursor, 'base64').toString('binary'))
このようなコードでですね、今回得られた文字列がbase64にエンコードされている想定でですね、それを今度はデコードする処理をNode のBufferモジュールで実装するとこのようになります。では、実行してみますね。
cursor:${何個目のnodeなのか}
実行すると、cursorsに格納した文字列がですね、デコードされてですね、各々がですね、cursor:というプリフィックス付きの文字列として出力されました。これがcursorの実体となります。では、最後にnodeの情報です。画面を戻しますね。nodeに関しては、各リポジトリのid、name、urlを示していることがわかりますね。このようにですね、GitHubで実現しているページネーションはrelay styleのページネーションをベースに実装されいてpageInfoやedgesといったフィールドでページに関する情報が提供されているということになります。
長くなりましたが、まとめです。
本レクチャーで学習した内容は、この後の実践編でページネーションを実装する上で必須となる知識ばかりですのでしっかりと概念や用語について身につけておきましょう。
というわけでですね、GraphQLのページネーションでした。
ここまで読んで頂き有難うございました!
少しでもお役に立てたら幸いです。