本記事はNTTコム公式アドベントカレンダーの25日(最終日)の記事です。
まさか最終日の記事担当とは恐縮です1。
著者は、技術開発部に所属し、社内外の各種データ分析、異常検知技術の研究開発を行っています。最近の研究成果は、AAAIのカンファレンスIAAI2018で採択されました。
はじめに
分析結果をいちはやくチーム内、各種サービス部に提供するために、OSSを駆使した分析基盤をチームで構築しています。分析結果をレポーティングするにあたり、データの集計や分析処理が必要になります。閲覧者により、レポーティング間隔(分析結果の更新頻度)の要求もさまざまです。例えば、
- 定期的なメール配信、データの最新化、機械学習のモデルの更新(1日に1回のバッチ処理)
- 1日に何度かデータにアクセスして、データの状況を確認する(◯分間 / ◯時間でのバッチ処理)
- 常に今のデータをモニタリングしたい(ニアリアルタイム処理、ストリーミング処理)
とくに最近の世間話では、リアルタイムでデータが見たいや今どうなのかが知りたいといった話題がよくあがります。実際、毎日モニターにべったりっていうわけではないでしょう。しかし、サービスの不具合時はモニターにべったりしてデータはまだかまだかと、いちはやく今を知りたいってこともあるでしょう。また、リアルタイムで動いてますって言ってデモで見せるとクール!といった使い方もでき ry)
我々はそのようなリアルタイム解析をさまざまなOSSのアーキテクチャで実装し、検証・導入を行っています。
JANOG2 39thではpmacct->kafka->presto->re:dash
を使った高速なflow解析というタイトルで12日目を担当した @__kaname__ からNWフローデータのリアルタイム解析事例も弊社から発表されました。このようなNWフローデータ解析だけでなく、インターネット上に設置したセンサー(Probe)により異なるNWトラフィックデータを収集し、様々な切り口で解析することも弊社では行っています。そこで、本記事では、Kafka+SparkStreamingを用いたリアルタイム処理基盤を構築した経験について書きたいと思います。私自身はじめて触れる技術も多かったので、勉強しながら実践していきました。
説明するにあたり、fluentd、Docker、Kafka、Sparkの用語がでてきますが、その辺については気づいた範囲でできるだけ噛み砕いて書きたいと思いますが、説明は省略します。
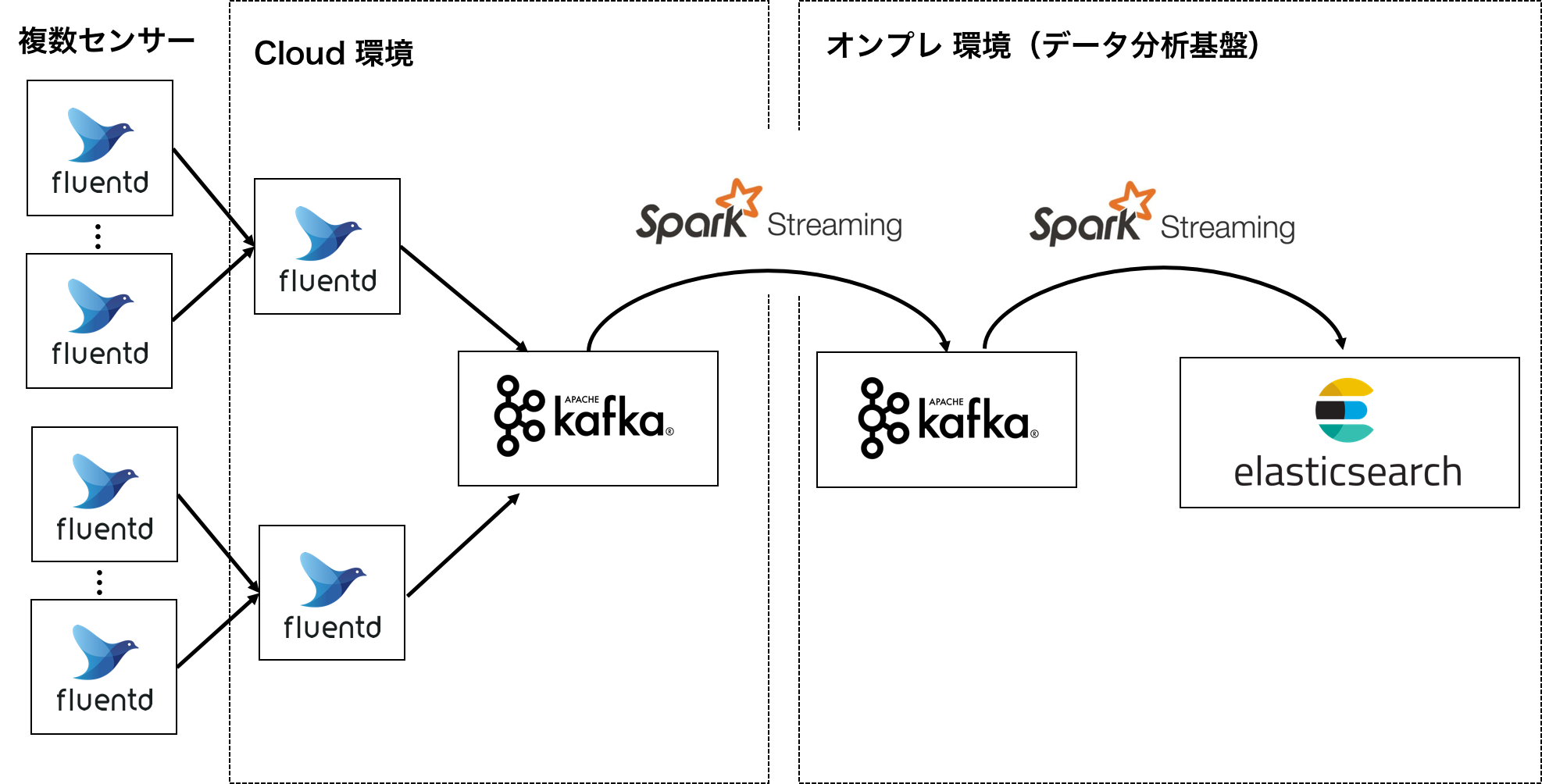
アーキテクチャ
複数の拠点にセンサーが設置されており、クラウド上の仮想マシンにデータがfluentdによって保存されている状況を想定します。
その際の要件としては、
- SQLベースで書ける処理が必要。すでに分析者が利用しているSQLクエリが複数存在するので、リアルタイムに集計する際にもそれを利用できるようにしたい。
- Pythonベースで構築したい。チームのスキルセット的にPythonで構築したほうがメンテナンスコストがかからないのと、基盤上で機械学習モデルAPIのインタフェースをすぐに利用できるためです。
- 分析環境の再現性の確保のため、Dockerコンテナで構築したい。
- Kibanaでの可視化のため、Elasticsearchにデータを格納したい。
以上の要件と昨今のトレンドから、Kafka+SparkStreamingをDockerコンテナでデプロイし、処理はすべてPythonで構築することにしました。
SparkStreamingを選定した理由としては、リアルタイムの粒度が数秒を争うほどシビアに求められなかった点、SparkSQLで流れてくるデータをSQLで処理できる点、理機械学習APIをPythonでそのまま利用できそうだなと思った点があったからです。
ポンチ絵は以下のとおりです。本記事ではノード数やクラスタ規模、また機械学習API部分等は省いています。
構築に利用したバージョンは以下のとおりです。
- fluentd : 0.12.40
- Kafka : 0.10.2.1
- Spark : 2.2
- Elasticsearch : 5.6.2
すでにKafkaクラスタ、Elasticsearchのクラスタは立ち上がっています。
クラウド上のfluentdからKafkaへの転送
収集されているセンサーからKafkaへの転送するためにCloud環境のfluentdで中継します。そのために、fluent.confを編集し、fluent-plugin-kafkaのとおり、KafkaへのOutput-pluginを利用します。以下に例を示します。
<match aaa>
<store>
@type kafka_buffered
brokers XXX.XXX.XXX.XXX:9092
default_topic TOPIC_NAME
<snip>
# See fluentd document for buffer related parameters
max_send_retries 1
required_acks -1
ack_timeout nil
compression_codec gzip
kafka_agg_max_bytes 4096
kafka_agg_max_messages nil
max_send_limit_bytes 1000000
discard_kafka_delivery_failed false
monitoring_list []
</store>
</match>
パラメータ調整はドキュメントどおりですが、 max_send_limit_bytes を設定して制限を設けたりしています。
設定後リロードすると、forward error error=#<Fluent::BufferQueueLimitError: queue size exceeds limit> error_class=Fluent::BufferQueueLimitErrorが頻繁に発生しました。過去に同様のエラーでの対処法(td-agentでqueue size exceeds limit)を参考に、Fluentd側のVMのメモリを増加して対処しました。
クラウド上のKafkaから基盤上のKafkaへの接続
クラウド上のKafkaから基盤側のKafkaへデータを送り込みます。単純なデータの転送ではなく、分析しやすいようなデータにクレンジング処理が必要になります。元のデータからノードのラベル情報や、時刻情報、統計情報を付与したりといったことです。
SparkStreamingで処理を行なうために、まずどの環境でも再現性を確保するために、SparkのDockerコンテナを構築します。すでに公開されているSparkのDocker Imageファイルもありますが、不要なライブラリが含まれていたりと、シンプルなImageが無かったため、Dockerfileを準備します。Docker SwarmでApache Sparkクラスタを構築してみるが参考になりました。
Dockerfileの重要な部分だけを抜き出します。
Sparkのインストール
# install spark
RUN cd /tmp \
&& curl -LO http://ftp.jaist.ac.jp/pub/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz \
&& tar zxf spark-2.2.0-bin-hadoop2.7.tgz \
&& mv spark-2.2.0-bin-hadoop2.7 /spark \
&& rm spark-2.2.0-bin-hadoop2.7.tgz
Sparkで使う外部のJARファイルをダウンロードします。ログをJSTの時刻で表示するためのapache-log4j-extras-1.2.17.jarとKafkaからデータをロードするためのspark-streaming-kafka-0-8-assembly_2.11-2.2.0.jarです。
また Structured Streamingを用いる場合Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher)を参考にspark-sql-kafka-0-10_2.11-2.2.0.jarを利用します。
# add jar files
RUN curl -o /spark/jars/apache-log4j-extras-1.2.17.jar -L "https://www.apache.org/dist/logging/log4j/extras/1.2.17/apache-log4j-extras-1.2.17.jar"
RUN curl -o /spark/jars/spark-sql-kafka-0-10_2.11-2.2.0.jar -L "http://central.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.11/2.2.0/spark-sql-kafka-0-10_2.11-2.2.0.jar"
RUN curl -o /spark/jars/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar "http://central.maven.org/maven2/org/apache/spark/spark-streaming-kafka-0-8-assembly_2.11/2.2.0/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar"
Python3でKafkaへデータをPublishするためのPythonライブラリです。Sparkで使用するPythonバージョンを環境変数で設定する。
# python packages
RUN pip3 install --upgrade pip setuptools
RUN pip3 install kafka-python
# set python3 for spark
ENV PYSPARK_PYTHON=python3
DockerfileをビルドしてImageを構築します
$ docker build -t spark-streaming-load:latest .
docker-composeで起動します。その際、Sparkの設定ファイルをマウントして起動します。
spark-streaming-load:
image: spark-streaming-load:latest
container_name: spark-streaming-load
hostname: spark-streaming-load
volumes:
- /data:/data
- /spark/conf/load.spark-defaults.conf:/spark/conf/defaults.conf
- /spark/conf/load.log4j.properties:/spark/conf/log4j.properties
- /spark/log:/spark/log
load.spark-defaults.confにSparkのパフォーマンスに関わるパラメータを設定します。公式ドキュメントでパラメータの内容を確認します。例は以下のとおりです。パラメータチューニングの詳細は後述します。
spark.master local[2]
spark.driver.memory 8g
spark.executor.memory 8g
spark.eventLog.enabled true
spark.streaming.concurrentJobs 1
ログファイルの設定をします。ログの出力先やフォーマットを設定することで、デバッグがしやすくなるため行います。
ファイルに書き出す設定(参考:Spark Streaming Logging Configuration)を行います。各ファイルは50MBまで格納され、超えると別のファイルに書き込まれます。5個までファイルを保存する用に設定します。
# Set everything to be logged to the console
# log4j.rootCategory=INFO,console
log4j.rootCategory=INFO,rolling
# logged to the rolling setting
log4j.appender.rolling=org.apache.log4j.RollingFileAppender
log4j.appender.rolling.layout=org.apache.log4j.EnhancedPatternLayout
log4j.appender.rolling.layout.conversionPattern=[%d{ISO8601}{GMT+9}]%-5p - %m%n
log4j.appender.rolling.maxFileSize=50MB
log4j.appender.rolling.maxBackupIndex=5
log4j.appender.rolling.file=/var/log/spark/streaming_load.log
log4j.appender.rolling.encoding=UTF-8
時刻に関しては、以下のフォーマットで出力するようにします。コメントアウトがデフォルトの設定です。
# log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout=org.apache.log4j.EnhancedPatternLayout
# log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss/zzz} %p %c{1}: %m%n
log4j.appender.console.layout.ConversionPattern=[%d{ISO8601}{GMT+9}]%-5p - %m%n
結果、無事にログがファイル出力されました。
<snip>
[2017-11-01 14:25:26,413]INFO - Running Spark version 2.2.0
<snip>
基本的な設定ができたので、続いてPythonスクリプトの準備を行います。例を以下に記します。Direct Kafkaベースでデータをロードします。
# -*- coding:utf-8 -*-
import sys,json
from datetime import datetime
from kafka import KafkaProducer
from collections import defaultdict
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from pyspark.sql import SQLContext,SparkSession
def process(dstream):
# process
<省略>
# Output
BROKER_HOSTS = "XXX.XXX.XXX.XXX:9092"
producer = KafkaProducer(bootstrap_servers = BROKER_HOSTS,
value_serializer = lambda v : json.dumps(v).encode('utf-8'))
producer.send("TOPIC_NAME", data)
if __name__ == "__main__":
# 30秒毎のバッチ処理を繰り返すStreamingContext
spark = (SparkSession.builder.getOrCreate())
sc = spark.sparkContext
sqlContext = SQLContext(sc)
ssc = StreamingContext(sc, 30)
# kafka Direct Stream
def my_utf8_decoder(s):
try :
if s is None:
return "{}"
return s.decode('utf-8')
except UnicodeDecodeError :
return "{}"
BROKERS_HOSTS = "XXX.XXX.XXX.XXX:9092"
kafkaStream = KafkaUtils.createDirectStream(ssc = ssc,
topics = ["TOPIC_NAME"],
kafkaParams = {"metadata.broker.list" : BROKERS_HOSTS},
valueDecoder = my_utf8_decoder)
# Parse
lines = kafkaStream.map(lambda x: x[1])
lines.foreachRDD(process)
# ストリーム処理を開始
ssc.start()
ssc.awaitTermination()
Sparkにサンプルファイルがあるので、基本はそれを参照することで動かすことはできると思います。しかし動かし続けていると、Kafkaからのデータロード時にEOFErrorが発生しました。これは、データの文字コードがDecodeできないときに起こるようでした。そのため、valueDecoderで例外処理を追加しています。発生理由は、センサー側のデータ取得のバグで、文字列のデータがたまに発生していたようです。現実問題だとこういうことがザラで起きますね。
参考:UTF-8 encoding error while connecting Flume twitter stream to spark in python
ジョブがスタックしないようなパラメータ調整
SparkStreamingで安定して運用させるために、ジョブがスタックしていないか等の監視は必須です。何もせずにほうっておくと、ジョブ処理が追いつかず、データの遅延が発生します。例えば、あるときからデータが急増した、重い処理をジョブに追加したときに起こります。
そのような状況になっているかを気づくのにSparkのデバッグログでINFO JobScheduler: Added jobs for time ◯◯◯ msがでてきます。
当初、このログやたら出るなって思ってググると
Continuously INFO JobScheduler:59 - Added jobs for time *** ms, in my Spark Standalone Clusterのとおり。要は、処理するスレッド数が不足しているときに出るINFOログでした。
といっても、単純にSparkのワーカー数を増やすことだけでも、解決しなかったので、続いてパフォーマンスチューニングについて調べました。
検索して見つけた中で、とくに有用だったのがLinkedinの技術ブログSpark Streaming : Performance Tuning With Kafka and Mesosでした。私なりの解釈で要約すると、
- Receiver baseより Direct base推奨。理由は、Kafkaのデータパーティションごとに、SparkのRDDを1対1で対応させることができる。結果、サーバのコア数をフルに活用して処理がはやくなる。Kafkaのデータパーティションはサーバのコア数の約2〜3倍のほうがフルにCPUを利用できる(らしい)
-
Batch Interval Parameterを少しずつ大きくして調整する。これは、Sparkのミニバッチの間隔のことで、ssc = StreamingContext(sc, XXX)のXXX部分を調整します。これはジョブの大きさや要件(RTB広告配信などではかなりキモになる)によって最適なのを調整します。 -
ConcurrentJobs Parameterを大きくする。ジョブの実行数のことで、ここを大きくすると、あるジョブの処理が遅れていても、それが完了するのを待つことなく次のジョブを実行することができます。ただし、私の意見でもありますが、本来1であるのが望ましいと思います。理由は、そもそもジョブがなぜ遅れているのかの原因がログ上で見えにくくなるためです。 - KafkaのPatitionがあるなら、1ミニバッチの1パーティションあたりの処理メッセージ数の制限値
maxRatePerPartitionを設定(デフォルトはnot set)する。これはあるパーティションで急激なデータが増えても、制限値でコントロールできるようにするためのパラメータです。
他にも、
MapRのPerformance Tuning of an Apache Kafka/Spark Streaming System - Telecom Case Studyなどはシステム全体のワーカーのメモリ数の割当等も紹介していて参考になりました。
KafkaからESへの書き出し
分析基盤側へのKafkaにデータが蓄積されるようになりました。このKafkaに蓄積されたデータをどう使うかですが、今回はリアルタイム可視化のために、ElasticSearchへの格納を別のSparkStreamingで構築します3。サンプルコードを以下に示します。
# -*- coding:utf-8 -*-
import json
from datetime import datetime
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from pyspark.sql import SQLContext,SparkSession,Row
from utils.Schema import Schema
from utils.Select import Select
from utils.ElasticSpark import ElasticSpark
def getSparkSessionInstance(sparkConf):
if ('sparkSessionSingletonInstance' not in globals()):
globals()['sparkSessionSingletonInstance'] = SparkSession\
.builder\
.config(conf=sparkConf)\
.getOrCreate()
return globals()['sparkSessionSingletonInstance']
def process(dstream):
# dstream load
spark_dstream = getSparkSessionInstance(dstream.context.getConf())
row = dstream.map(lambda x: Row(
date = json.loads(x)["DATE"]
key = json.loads(x)["KEY"],
value = float(json.loads(x)["VALUE"]))
)
# schema setting
schema = Schema()
row_df = spark_dstream.createDataFrame(row, schema.get())
row_df.show()
# Select and Filtering
ps = Select(spark = spark, df = row_df)
sql_df = ps.select(keyword = "AAA")
sql_df.show()
# To ES
es = ElasticSpark()
es.df_write(sql_df, "BBB", "BBB")
if __name__ == "__main__":
# StreamingContext by Each 60 sec
spark = (SparkSession.builder.getOrCreate())
sc = spark.sparkContext
sqlContext = SQLContext(sc)
ssc = StreamingContext(sc, 60)
# kafka Direct Stream
BROKERS_HOSTS = "XXX.XXX.XXX.XXX:9092"
kafkaStream = KafkaUtils.createDirectStream(ssc = ssc,
topics = ["TOPIC_NAME"],
kafkaParams = {"metadata.broker.list" : BROKERS_HOSTS})
# Batch Process Define
lines = kafkaStream.map(lambda x: x[1])
lines.foreachRDD(process)
# Start
ssc.start()
ssc.awaitTermination()
大枠はSparkのサンプルコードのとおりですが、実際に分析で使えるようにするために、いくつか処理を挟んでいます。ざっと流れを説明します。
SparkのDataFrame型でデータを処理したいため、RDD形式をまずRow型で記述してDataFrameを構築します。
次に、各データ列のスキーマ(String, Float, Date型など)を自作のSchemaクラスで定義します。例は以下のとおりです。
schema = StructType([
StructField("date", TimestampType(), True),
StructField("key", StringType(), True),
StructField("value", FloatType(), True)
])
続いて、自作のSelectクラスでSpark SQLに基づいてそのデータから必要な列を選択したり、条件にマッチする行のみを抽出したり、Groupby等で統計処理を行ったデータを作ります。例は以下のとおりです。
sql_df = self.spark.sql("""
select *
from df
where key rlike '^[a-z]+[0-9]{2}$' AND
(value > 0 AND value < 100)
""")
最後にDataFrameをElasticsearchにデータをインポートします。ここでは、Elasticsearchのベーシック認証を通じて格納されます。このとき、ハマったのが、es.nodes.wan.onlyがデフォルトでFalseになっていたようで、自分の環境ではTrueにしています。また、Elasticsearchがサービスダウンしているときでも処理が継続されるような例外処理を追加します。
try :
df.write\
.format("org.elasticsearch.spark.sql")\
.mode('append')\
.option("es.nodes",self.urls)\
.option("es.port",self.port)\
.option("es.net.http.auth.user",self.user)\
.option("es.net.http.auth.pass",self.password)\
.option("es.nodes.wan.only", True)\
.option("es.resource",index+"/"+mapping)\
.save()
except Py4JJavaError :
print("ERROR - Something wrong to import ES")
結果として、以下のようなDataFrame形式のデータが流入され、Elasticsearchにインポートされるようになりました。
<snip>
INFO DAGScheduler: Job 93 finished: showString at NativeMethodAccessorImpl.java:0, took 0.162547 s
+---------------------+-------------+-----------+
| date| key| value|
+---------------------+-------------+-----------+
| 2017-12-12 09:58:50| abcc12| 3.72|
+---------------------+-------------+-----------+
INFO SparkContext: Starting job: runJob at EsSparkSQL.scala:101
<snip>
あとはKibanaを用いてデータを好きなように閲覧します。この設定は省略します。
構築後を振り返ると
- Kafka+SparkStreamingを今回一から作りました。サンプルコードは色々あるのですが、それを実環境で動かすまでのプロセスはそれの組み合わせだけじゃ解決しないことも多かったです。その辺は、幅広い周辺知識をキャッチアップしながら、あとはStack Overflowの検索力。
- データの発生からのESへの格納までのボトルネック箇所の分析はこれから必要になりそうです。Kafka、Spark、Elasticsearchとボトルネック箇所となり得るのが複数考えられるため、切り分けのために各種プロセスのモニタリングが必要になります。Spark Streamingの概要と検証シナリオは読んでいて、ボトルネック箇所を調べる勉強になりました。
- どれくらいの前のデータを見たいというニーズにこのアーキテクチャだとどこまで耐えれるのかはまだまだわかりません。例えば、10秒後のデータがみたいといったことに耐えれるのかなど。
- セキュリティ要件を今回は省いていますが、SSL化等でパフォーマンスがどの程度落ちるのかも気になります。
運用しながら、勘所を掴んでいくのがこれからですが、Pythonだけで処理を完遂できることを確認できましたので、これからより良いものを目指していきます。
おわりに
本記事では、著者のPythonでのリアルタイム処理基盤の構築した経験を振り返りました。つい最近までは、異常検知技術の研究開発を行ったり論文を書いていたりしてましたので、新鮮な気持ちで基盤構築に取り組むことができました。振り返ると、いろいろアラいところもあったのですが、アドベントカレンダーの機会でアウトプットさせて頂きました。ここはどうしてこのようなことをしているのかなど、素朴なご意見や質問は大歓迎です!Enjoy Data!