GitLab Advent Calendar 2018 7日目の記事です。
この記事でわかること
- GitLab APIの使い方
- APIで取得したデータの活用方法
はじめに
GitLab使ってますか?私が所属するチームでは、2014年から4年以上、sameersbn/docker-gitlabのdocker imageを利用しています。チーム外の方も我々のコード等を利用するために、一部のプロジェクトにゆるく参加してもらったりして、社内の利用者をどんどん増やしています。
GitLabの用途として、コード管理はもちろんのこと、Issueによるプロジェクト管理、Issue Boardによる進捗管理、GitLab CIを用いてプロジェクトごとに複数の分析スクリプトを日々バッチで実行したりしています。そのため、業務に関わる多くのことをGitLabの各種機能に依存しています。会社によっては、同様のことをGithub Enterpriseで行っているところも多いでしょう。触れている時間が多いことから、私にとってもGitLabは好きなプロダクトの1つです。
さらに、GitLabはGitLab APIも非常に充実しており、実はGitLabの画面上で操作する多くのことがAPI経由で実行することができます。しかし、APIでできるからといって、これまでわざわざ使うケースに出くわしたことは少ないかもしれません。
GitLabを長く利用していると、各種プロジェクトや利用者も徐々に増え、プロジェクト横断的な管理が難しくなってきたり、GitLab CI Jobの管理が難しくなってきました。例えば、
- 利用傾向確認のため、プロジェクト数 / メンバー数はどれくらい増えてきているのか?
- チームメンバー、その他利用者がどんなコードを今書いてるのか?どんなライブラリを利用しているのか?
- さまざまなプロジェクトでGitlab CIによるJobが走っているが、共通的なエラーはないか?どれくらいJobが失敗しているのか?なにか対策がとれないか?
など、素朴な利用動向に対する疑問から、GitLabで管理しているプロジェクトをより良くするためになにかできないかなど、いくつか解決したい課題が見えてきました。
本記事では、GitLab APIを使ってこれらに関するデータを収集し、利用してきた自分たちのケーススタディをいくつか紹介します。
環境
GitLab APIで取得できるデータの整形に、jqコマンドを利用しますので、インストールしておきます(方法は省略)
- GitLab : 11.5
- GitLab FQDN : mygitlab.com
- GitLab API : v4
- jq : 1.3 (古い…)
準備 : Private トークンを準備しよう
GitLab APIを使用するためのPersonal access tokensを作成する必要があります。ページにある手順どおりですが、ユーザごとの右上のアイコン画面から[Settings] -> [Access Tokens]で作成するページにいきます。
作成されたPrivate TokenはXXXであるとします。
練習
Gitlabへ移行した際の、使えるAPI(v4)メモにGitlab API v4の一般的なコマンドを紹介してくれています!これを見て、個々のGitLab環境で叩いてみましょう!
目的1 : プロジェクト数 / ユーザ数の推移を見たい!
GitLab APIでは、paginationの考え方をもとに、APIを叩くことで、大量の結果が返ってくることを避けるために、pageとper_pageを指定することで、データの取得範囲を制限します。
ここでは、page=1とper_page=3とすることで、3件のデータが返ってきます。実際すべてのデータを取得するには、時間間隔をあけながらforループでpageをインクリメントしていけばいいでしょう。
GitLabにあるプロジェクト一覧を取得するために/projectsにGETリクエストを投げてみます。jq以降は取得したjsonから必要なキーを取得する処理を書いています。
$ curl -XGET -H "PRIVATE-TOKEN:XXX" "http://mygitlab.com/api/v4/projects?page=1&per_page=3" | jq ".[] | { id : .id, name : .name, web_url : .web_url, created_at : .created_at }"
<snip>
{
"created_at": "2018-12-05T05:03:41.776Z",
"web_url": "http://mygitlab.com/gingi99/test_project",
"name": "test_project",
"id": 100
}
つづいて、GitLabに登録しているユーザも取得してみましょう。/usersにGETリクエストを投げてみます。
$ curl -XGET -H "PRIVATE-TOKEN:XXX" "http://mygitlab.com/api/v4/users?page=1&per_page=3" | jq ".[] | {name : .name, created_at : .created_at, id : .id}"
<snip>
{
"id": 50,
"created_at": "2018-07-04T01:28:13.350Z",
"name": "OKI"
}
これで必要なデータは取得できました!
ここでは、ユーザ数の推移を例に可視化してみることを行います。具体的には、created_atがユーザ(id)がGitLabに登録した時刻を表すので、それをもとにユーザ数の時系列推移を可視化してみます。可視化にはRを使用しました。軸のスケールは申し訳程度に消しています。
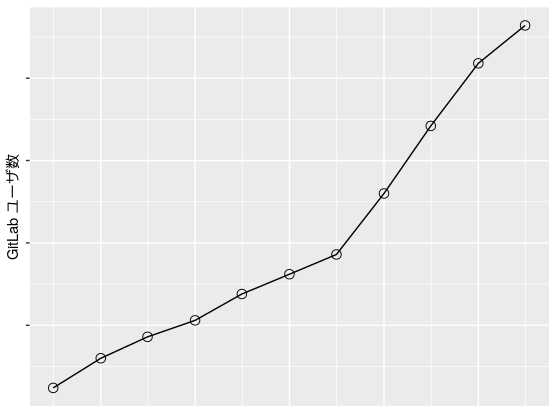
利用者数は、最近まで単調に伸びてきていることがわかります。ある時期にユーザ数が増加しているのも、プロジェクトに関わる人が増加した時期であるかもしれません。また、各時期のアクティブユーザ数は各ユーザが各時期別でコミットした時刻と合わせることで、わかりそうですね(以下、省略)。
目的2 : 各言語のファイル数の推移 / ライブラリの使用状況を把握したい!
先程の簡単に例につづいてですが、GitLabの各プロジェクトでどんなコード(何の拡張子のファイル)をみんなが書いてるか気になります。それを調べるために、ここでは、各プロジェクトのファイル名を取得していくことを試してみます。
まず重要なのが、GitLabにあるすべてのプロジェクト名とそのidの対応を把握することです。というのも、各プロジェクトをAPIで参照するには、各プロジェクト名ではなく、IDが必要です (@tnir さんからのコメントの通り、Namespaced path encodingを使えばプロジェクト名でも参照できます!) 。プロジェクトIDを知るのは、先ほど/projectsへのリクエストで、取得したidを使います。これを使って、プロジェクト名とそのIDのテーブルを先に用意しておきます。また、GitLabで各プロジェクトのページを見れば、Project IDというのが上に記載しているのでそれで確認することもできます。
次に、各プロジェクトのレポジトリにあるファイル名等の情報を取得します。ID=100のプロジェクトの/repository/treeにGETリクエストを投げた結果を示します。参考:Repositories API
$ curl -XGET -H "PRIVATE-TOKEN:XXX" "http://mygitlab.com/api/v4/projects/100/repository/tree?ref=master&recursive=true&page=1&per_page=3"
[
<snip>
{
"mode": "040000",
"path": "utils",
"type": "tree",
"name": "utils",
"id": "abc1234"
},
{
"mode": "100644",
"path": "Analysis.Rmd",
"type": "blob",
"name": "Analysis.Rmd",
"id": "def5678"
},
<snip>
]
ここで返ってくる結果のポイントは、キーがtypeとなっている箇所にtreeとblobが格納されています。treeはディレクトリを表し、blobはファイルを表しています。リクエスト時にパラメータとしてrecursive=trueとref=masterとしておくことで、masterブランチに対して、typeがtreeのものを再帰的にファイル取得してくれます。
あとは、各プロジェクトIDの分だけforループを回しながら、pageもインクリメントしていくことでどんなコード(拡張子)が多いのかを分析できるデータが取得できます。
それだけで終わりません。私自身、データ分析チームであるので、チームでよく使用するRの拡張子(.Rまたは.Rmd)を例に、各Rファイルでどんなライブラリを使用しているかのデータを取得します。そのために、各ファイル(ソースコード)を開き、Rの場合library(***)で始まっている行に注目する必要があります。(...さすがに、ここまで来ると、プログラミング言語で記述したほうが楽ですので、実際はPythonでリクエストコードを書いています。)
ここでは例として、ID=100のプロジェクトのAnalysis.Rファイルの中身を標準出力してみます。具体的には、/repository/files/[Path]/rawにGETリクエストを投げた結果を示します。
$ curl -XGET -H "PRIVATE-TOKEN:XXX" "http://mygitlab.com/api/v4/projects/100/repository/files/Analysis.R/raw?ref=master"
<snip>
library(dplyr)
library(ggplot2)
<snip>
このように、ファイルの中身も取得することができました。今回はライブラリ名を抽出することで、各プロジェクトにあるRファイルでどんなライブラリが使われているのかもデータ化することができました。
目的1のときと同じように、Rファイル数の推移を例に可視化してみることを行います。
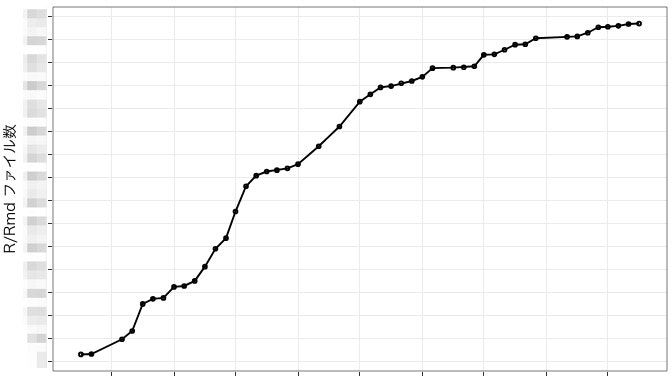
Rファイル数も、最初は伸びてきているところから、最近は伸びが小さくなっていることがわかります。この結果だけからは結論はわかりませんが、同じファイルをコミットしているためか、もしくは、Python等の別の言語に利用者移り変わっているということがあるかもしれません。いろいろと考えさせられる結果ですね。
また同様に、どんなライブラリを利用しているのかを把握するために、棒グラフで可視化してみます。y軸にライブラリ名が比率の多い順に並んでいます。下部は切り取っています。70%というのは、すべてのRファイルの中で、このライブラリを使用している(正確には、呼び出してる)率になります。Rユーザなら、上位は何になるか想像できますよね?
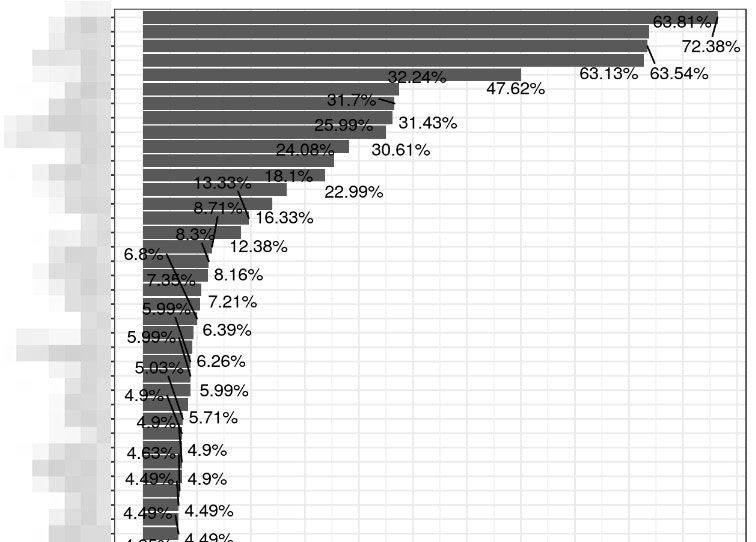
例えば、ある言語の初学者向けに、こういう結果から上位のライブラリを調べていくことで、プログラミング言語の習得に役立つかもしれません。他の言語でも似たようなことができそうですね。
目的3 : プロジェクト横断でGitLab CIの失敗Jobのエラー内容を分析したい!
さいごです。我々のチームではGitLabのいくつかのプロジェクトで、GitLab CIを用いて、バッチで定期的にデータのETL処理、分析結果のレポーティング通知等を行っています。ETL処理のために、Pipelineを複数定義し、1つのPipelineで複数のJobを呼び出しています。分析チームならではの使い方かと思います。
しかし、問題として、個々のパイプラインで定義されたJobの失敗が通知されると、それぞれの開発者の方でまずエラー処理/デバッグ対応をしていきますが、GitLab CI自体のエラーや実行環境および分析環境等の低いレイヤーでのエラーになるほど、開発者だけでなく、インフラエンジニアとともに解決に向かう必要があります。このような低いレイヤーでのJobの失敗は、各プロジェクト共通で発生しうるので、分析基盤の問題になりがちです。
そこで、GitLab CIで失敗したJobデータを定期的に収集し、そのJobが標準エラー出力した中身を解析することで、どんなエラーがどれくらいの頻度で発生しているかを把握してみます。。ID=100のプロジェクトの/jobsにGETリクエストを投げた結果を示します。参考:Jobs API。scope=failedを指定することで、失敗したJobに限定することができます。
$ curl --header "PRIVATE-TOKEN:XXX" 'http://mygitlab.com/api/v4/projects/100/jobs?scope=failed&page=1&per_page=3' | jq '.[] | {id : .id, created_at : .created_at, name : .name, web_url : .web_url}'
<snip>
{
"web_url": "http://mygitlab.com/gingi99/test_project/-/jobs/1000",
"name": "analysis_job",
"created_at": "2018-12-05T09:19:06.909Z",
"id": 1000
}
これで、失敗したJob IDの一覧を取得することができました!
つづいて、失敗したJobの標準エラー出力を取ってみます。ID=100のプロジェクトで失敗JobのJob ID=1000に、/jobs/[Job ID]/traceにGETリクエストを投げてみます。traceされた結果が出力されます。
$ curl --header "PRIVATE-TOKEN:XXX" 'http://mygitlab.com/api/v4/projects/100/jobs/1000/trace'
〜〜〜
ERROR: Job failed 〜〜〜
これで目的のデータを獲得できることを確認できました!あとは、各JobのtraceログからErrorの文字列マッチで抽出したり、ログの下N行を取得するなどして、価値のあるデータを抽出していきます。このような機械の吐く失敗ログの分析は、いわゆるSyslog分析に近く、解析法としてさまざまな面白いことができるのですが、今回は省略します。
いくつかのプロジェクトでのJobの失敗ログ数の推移をみてみると、以下のようになっていました。色でエラーの種類を分けてます。
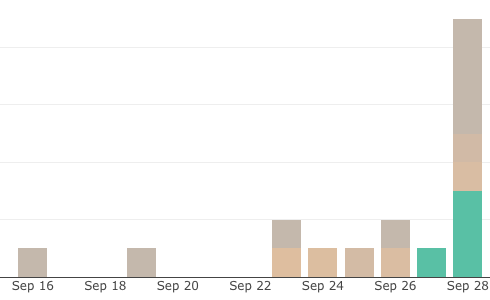
この例では、9月27日で新しいエラーが登場し、28日に大きく件数が増えています。エラーの詳細には触れませんが、緑色のエラーの発生が、あとに続く別のJobの失敗を引き起こす可能性について見える化できた一例です。
このように複数のプロジェクトに渡って、失敗ログを定期的にかつ定量的に把握しておくことは後の大きな失敗の予防につながることも期待できます。
できなかったこと
これまで、GitLab APIを通じてデータ取得を行ってきましたが、リクエストに期間を指定してデータを取得することができないようです。つまり、リクエストに対して、created_atがある日からある日までのデータを取るといったことは、該当の日が出るまでpageをインクリメントする必要があります。この点が解決できれば、さらに容易にデータ収集も可能になると思います(が、優先事項は低いと思います。)
おわりに
GitLab APIにより、多くの興味深いデータを収集し、可視化および分析してきました。とくに役立ってきたのは、目的3で扱ったように、複数プロジェクト横断における課題発見および解決を目指して、GitLab APIにより効率よくデータを収集して、分析できることだと思います。
また、その他に、メンバーが今週どんなプロジェクトにcommitしていたかを確認して、忙しそうなプロジェクト・逆に進んでなさそうなプロジェクトはなにかを探索するといった、GitLabで普段の業務を行っているエンジニア中心のチームの業務見える化を目指したピープルアナリティクスとして応用することもできます。
みなさんも、GitLab APIでデータを取得し、分析することで思いがけないプロジェクトの発見や、これまでのプロジェクトの活動量を見える化しましょう。
また、今回は、curlコマンドでの例を紹介しましたが、例えば、Pythonですとrequestsモジュールで同様のことができますし、Rですと、httrもしくはgitlabrというパッケージもありますので、それで簡単にAPIを利用したり、今回の例のようにデータ取得を試すことができます!是非トライしてみてください。
もちろん、Githubでも同じようなことを実施する方にもこの記事が参考になればと思います!ありがとうございました。