この記事について
グラフデータベースNeo4jを使ったグラフアルゴリズムの実装を紹介してみようという計画「グラフアルゴリズム入門 - javaとNeo4jで学ぶ -」の一部です(どこまで続くか・・・)
サンプルコードはこちらにおいた。
Neo4jのユーザ定義プロシージャ
Neo4jにはユーザ定義のプロシージャを組み込む機能が用意されている。その利用方法はNeo4j開発初期のころよりもかなり簡単になっており、Cypherと連動した利用もできる。以下の点について紹介する。後者については、マニュアル等にあまり情報のないPathを返却するようなプロシージャの作り方についても触れる。
- ユーザ定義プロシージャの利用の仕方
- ユーザ定義プロシージャの作り方
ユーザ定義プロシージャの利用の仕方
インストール
まずは、Neo4jから提供されているプラグインをアクティブにしてみよう。Neo4j Desktopがインストールされていて、おなじみのMovie Graphがデータベースとして作成されている前提で説明する(Neo4j Browserで:play moviesでMovie Graphのデモが開始される)。Neo4j Desktopを立ち上げ、My ProjectからMovie Graphを作成したデータベースを選択し、manageを選択。メニューからPluginsを選択すると、Neo4j Desktopからインストールできるプラグインが表示される。
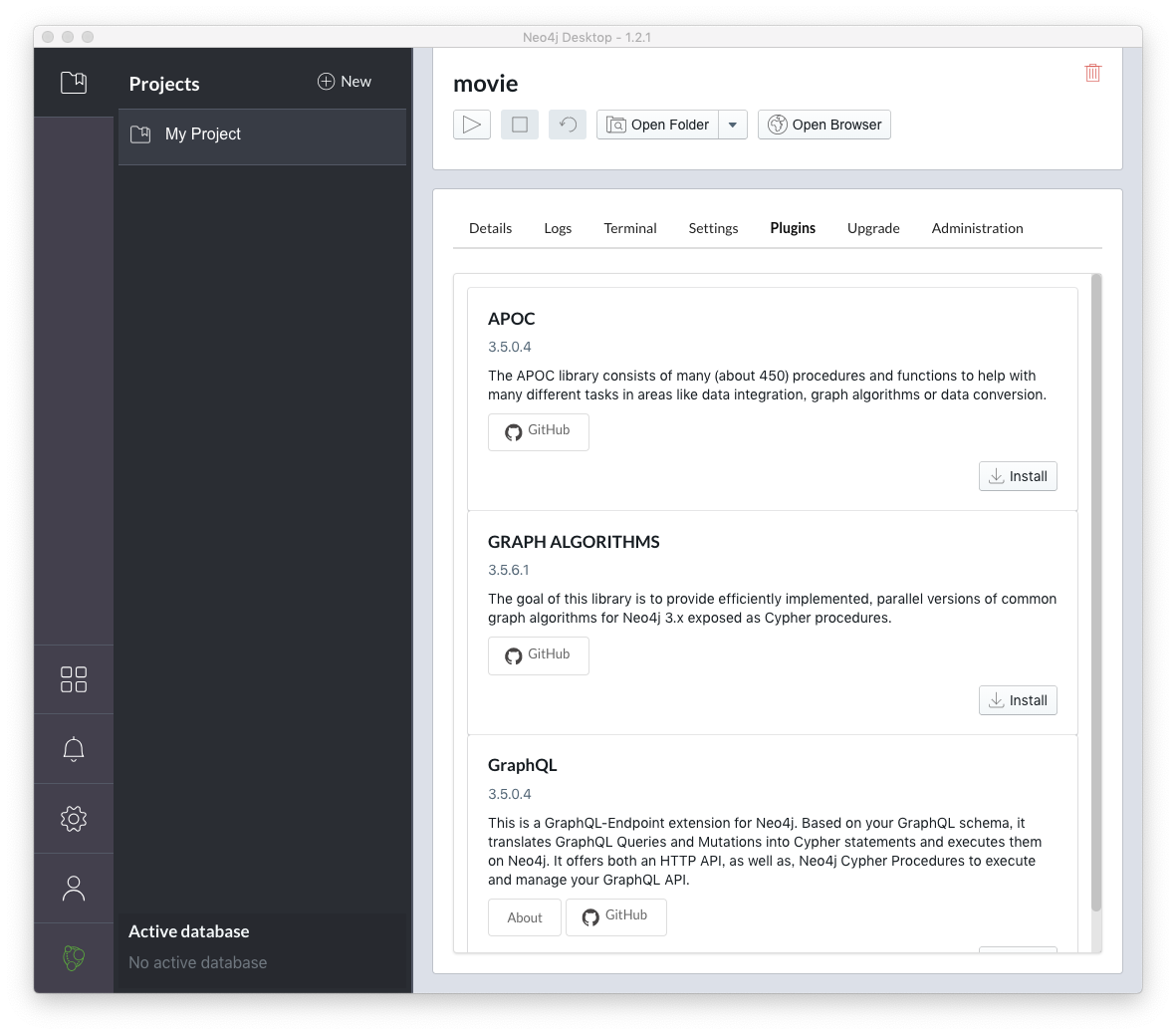
APOC・Graph Algorithms・GraphQLのプラグインがある。ここで右のInstallボタンを押せばプラグインはインストールされる。インストールにはインターネット接続が必要である(つながっていないとボタンは表示されない)。インストールされたプラグインは、上のメニューにあるOpen Folder→Pluginsによって確認できる(下はAPOCをインストールした状態)。
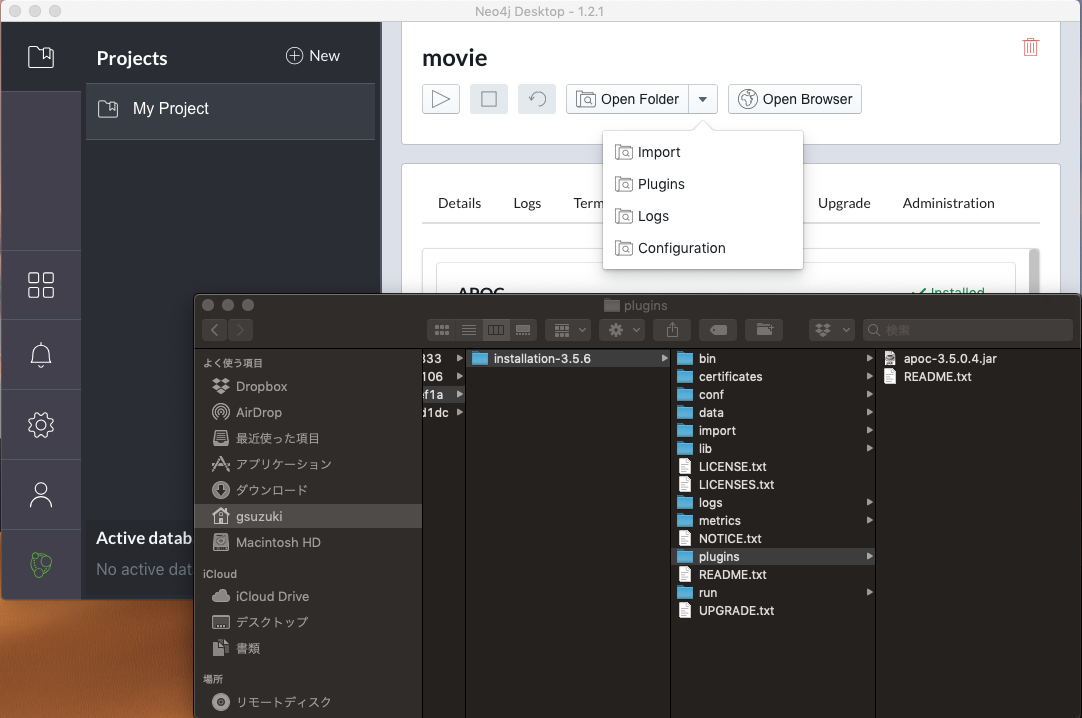
プラグインフォルダにapoc-3.5.0.4.jarが配置されている。自分でユーザ定義プロシージャを利用するときも、自分で作ったjarをここにおいてデータベースを再起動すれば利用できる。
Cypherからの利用
今インストールしたAPOCをサンプルとして、Cypherからの利用方法を説明する。まず利用可能なプロシージャを確認してみよう。CALL dbms.procedures()で利用できる一覧を取得することができる。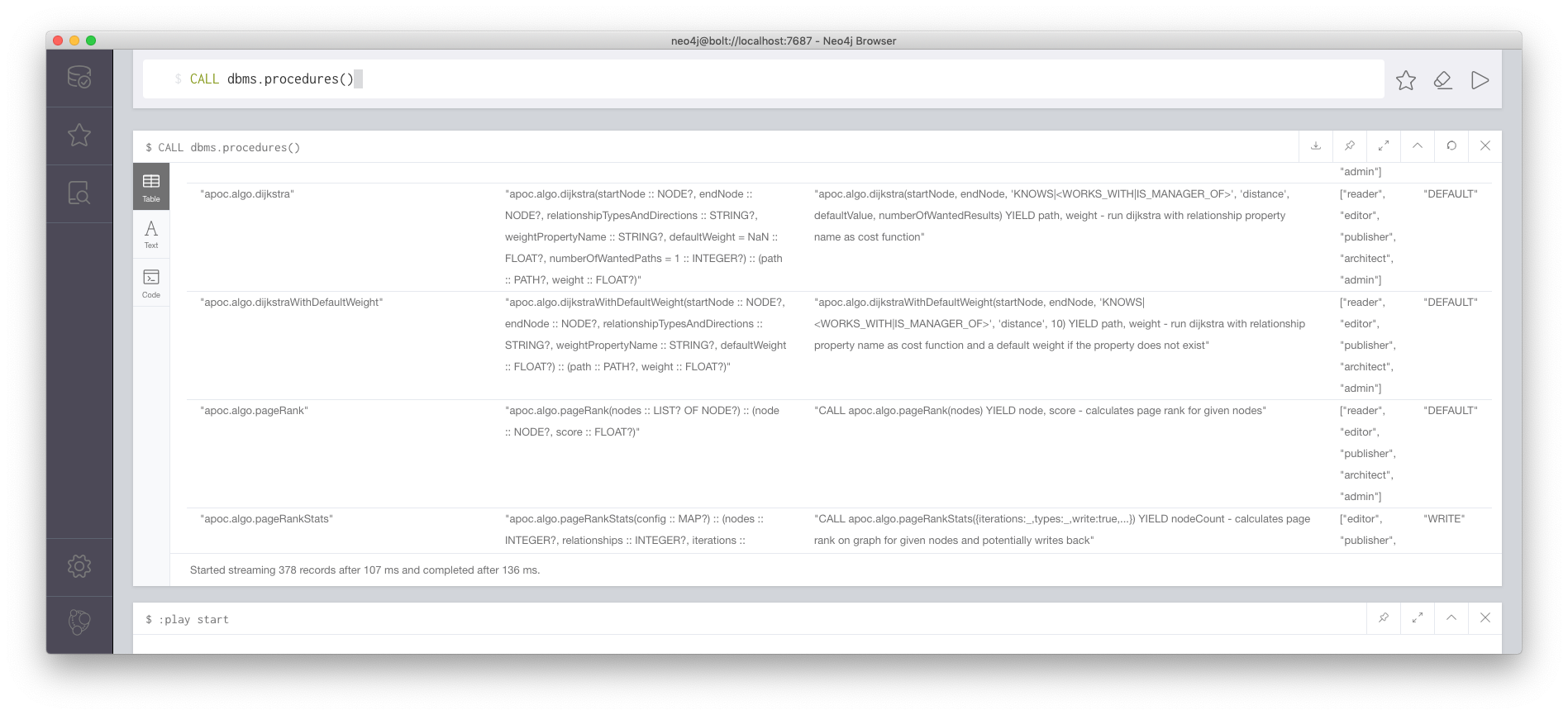
プロシージャの名前、シグネチャ、概要、等が表示されている。ここではAPOCのダイクストラ探索であるapoc.algo.dijkstraやPageRankアルゴリズムであるapoc.algo.pageRank等が利用できることがわかる。
プロシージャを呼び出すには、CALLを使う。上記のCALL dbms.procedures()もそれ自体プロシージャを呼び出す例となっている。CALLはCypherに組み込んで使うことができる。例えば、CALL dbms.procedures()でプロシージャの名前だけが取得したいとする。そのときは、YIELD AS を利用して結果をCypherの変数にマッピングし、RETURN句で絞り込めばよい。
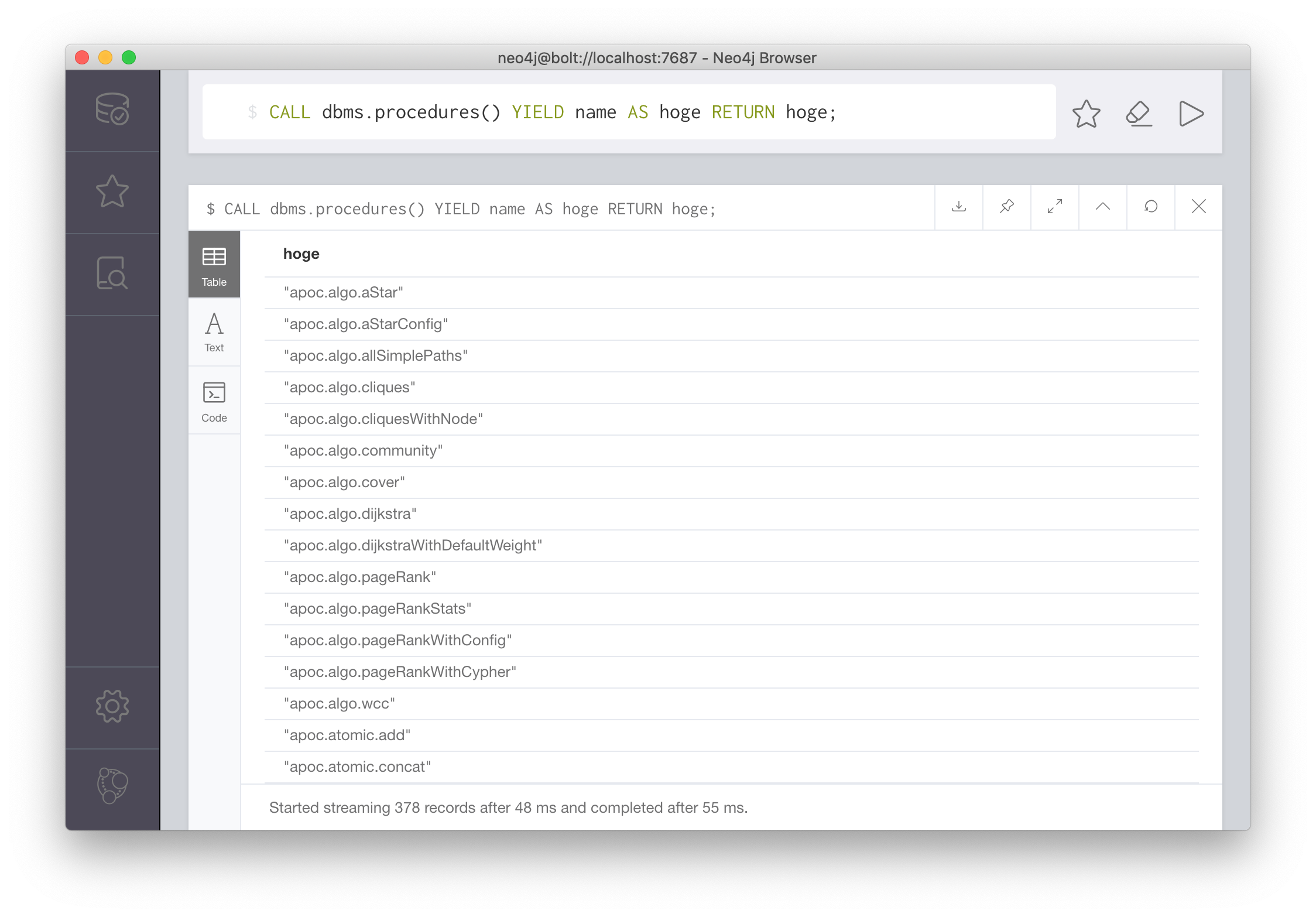
この例では、dbms.procedures()の結果のnameをhogeというCypherの変数にマッピングして、hogeをRETURNしている。
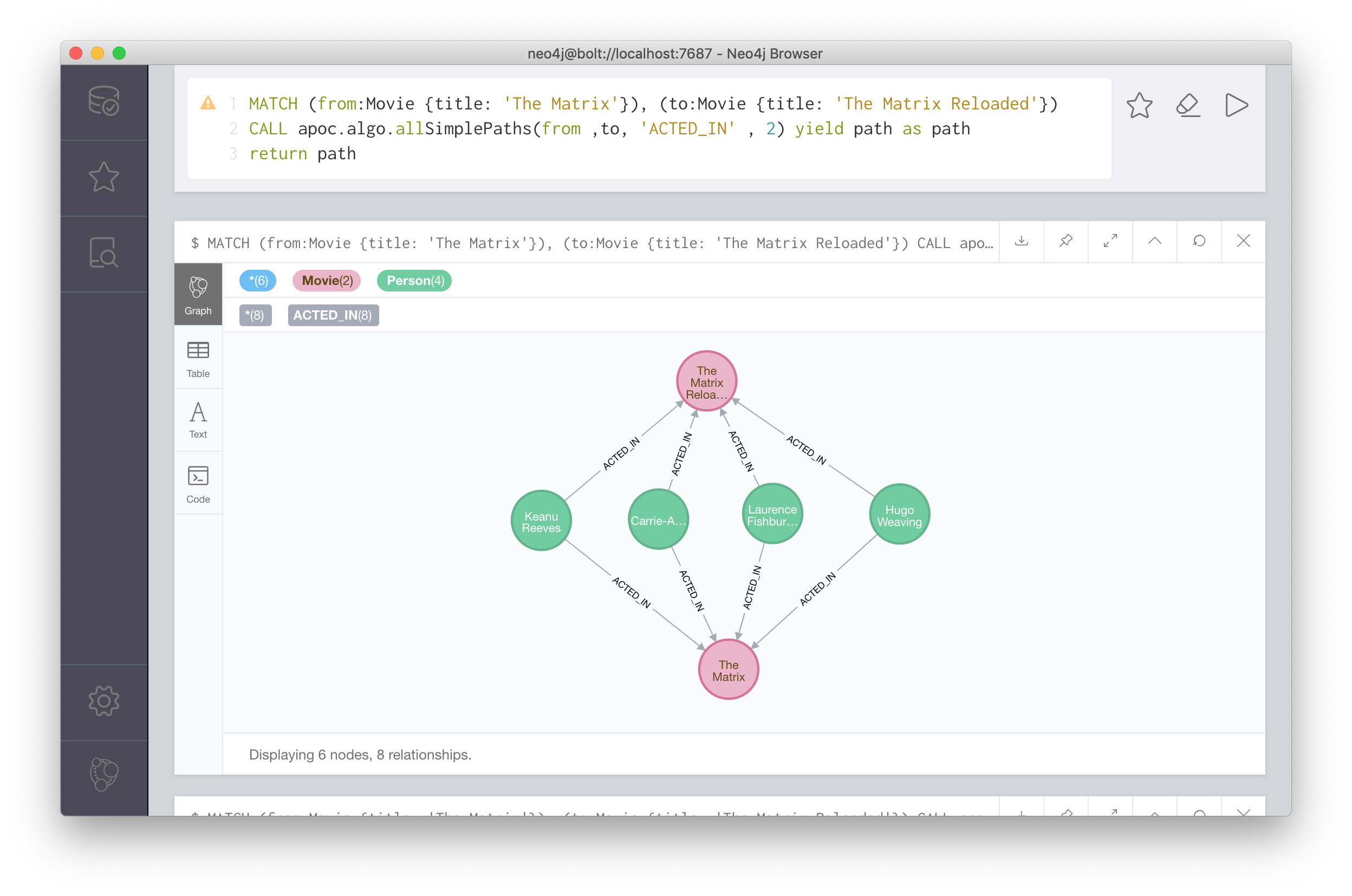
次に、apoc.algo.allSimplePathsを使ってノード間のパスを取得してみよう。下記のサンプルような書き方をすることができる。これはThe Matrixというタイトルをもったノードから、The Matrix Reloadedというタイトルをもったノードへ、ACTED_INというタイプをもった関連によって到達するパスを求めるようなクエリとなる。このようにプロシージャはCypherに統合された形で利用することができる。
MATCH (from:Movie {title: 'The Matrix'}), (to:Movie {title: 'The Matrix Reloaded'})
CALL apoc.algo.allSimplePaths(from ,to, 'ACTED_IN' , 2) yield path as path
return path
上記サンプルの実行結果が以下の通りである。
ユーザ定義プロシージャの作り方
開発者がユーザ定義プロシージャの作成を容易にするためのテンプレートとして、Neo4j Procedure Templateが提供されている。 このテンプレートを拡張する形でプロシージャを作成するのが楽である。このプロジェクトにはFullTextIndex.java、Join.java、Last.javaの3つのテンプレートが含まれているが、後の2つはユーザ定義関数(Last.javaはさらに集計)の例なので、ここではプロシージャの例であるFullTextIndex.javaを参考にすることにする。
まずは、2つの文字列を連結するようなプロシージャを作ってみる。以下のコードを挿入すれば機能する。@Procedureアノテーションはプロシージャの名前、@Descriptionアノテーションはプロシージャの説明を表しており、dbms.procedures()の結果に表示される。プロシージャの引数は@Nameアノテーションを使う。結果はユーザが任意の作成した結果用クラスのオブジェクトのStreamとする必要がある。結果用クラスのクラス名は任意である。クラスのメンバーには、プロシージャの結果として使われる変数の名前と型を定義する必要がある。
// user defined procedure sample
@Procedure(value = "example.sample01") // プロシージャの名前
@Description("ggszk sample01") // プロシージャの説明
public Stream<Output> sample01( @Name("sei") String sei,
@Name("mei") String mei )
{
Output o = new Output();
o.out = "hello: " + sei + mei;
return Arrays.asList(o).stream();
}
// 返却値となるクラス
public class Output{
public String out;
}
この修正を行った後、リビルドし作成したjarをプラグインフォルダに置き、再起動すればこのプロシージャが利用可能となる。dbms.procedures()によって、正しく組み込めたかどうかが確認できる。
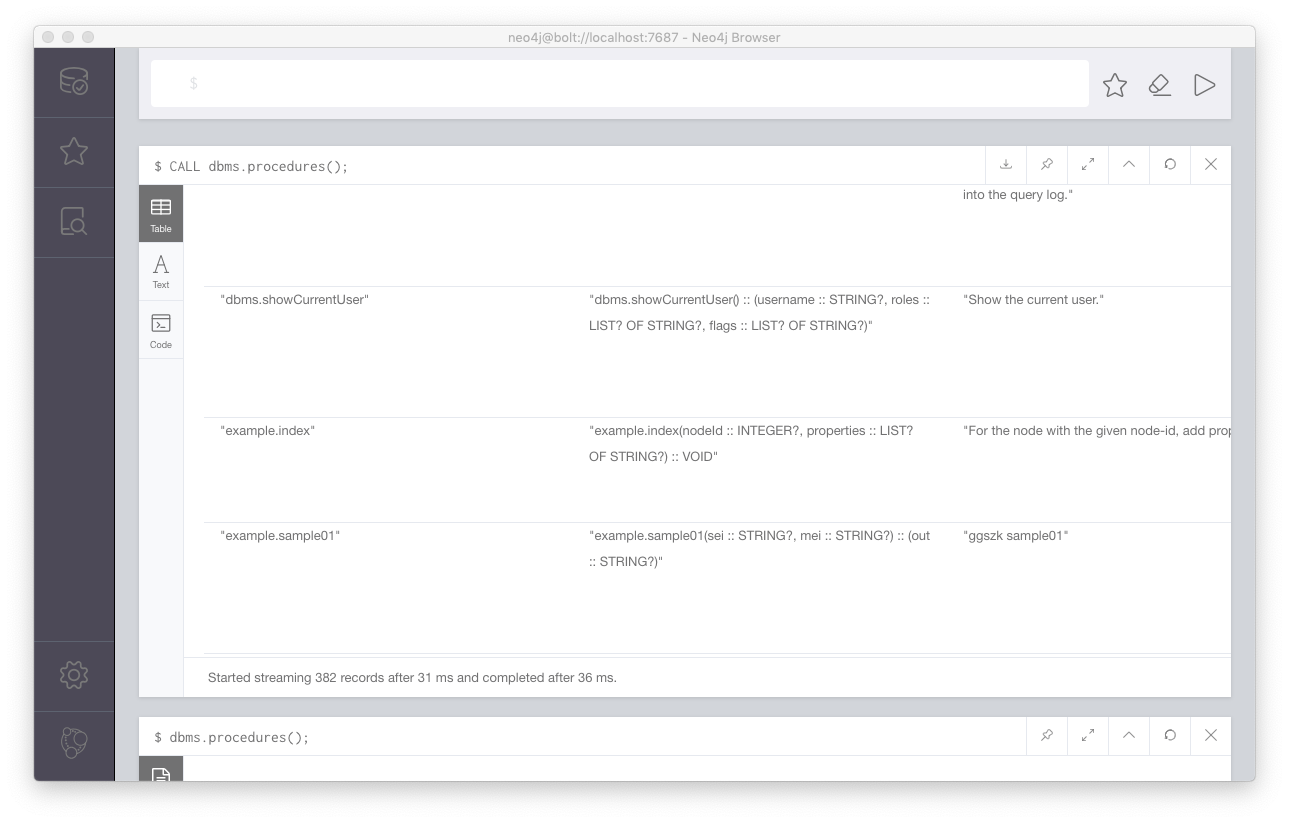
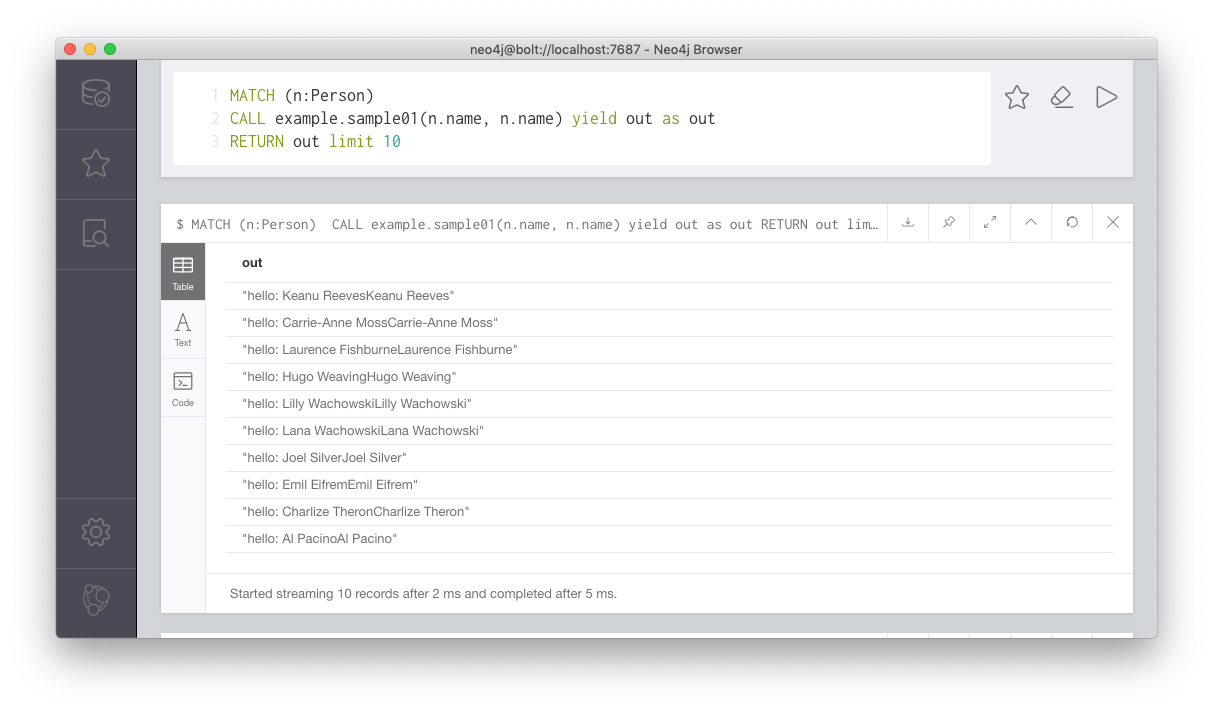
確かに、example.sample01が組み込まれている。これを利用してみる。あまり良い例ではないが、Personのnameを2つつなげてみた。
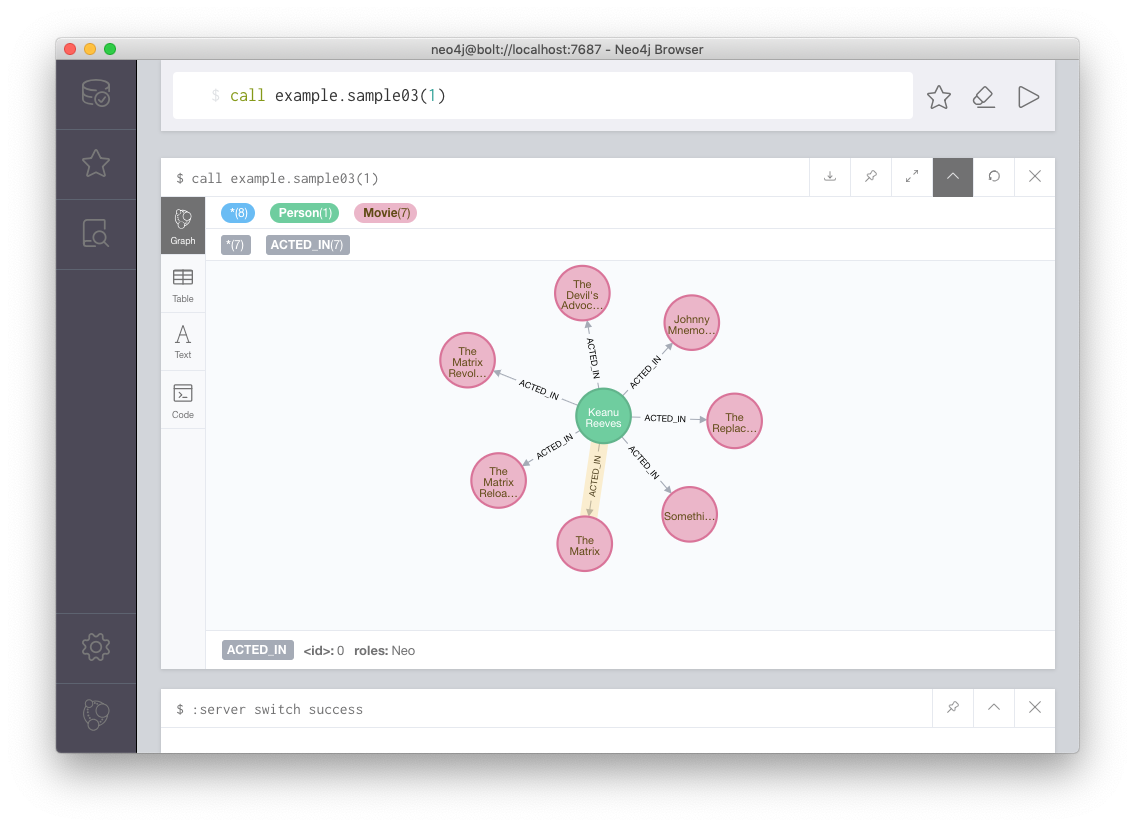
自分の探索アルゴリズムを実装し利用するためには、Pathを返却するプロシージャを作る必要がある。しかし、Pathを返却する例はこのテンプレートにはなく、また、Pathを作ることはCypherを通じてNeo4jを利用する限り、ほとんど必要にならないために開発者マニュアルにも記述がない。そのあたりの実装はAPOCプロシージャのPath Finding系のソースコードを見ればよい。Pathの作成にはorg.neo4j.graphalgo.impl.util.PathImpl.Builderを使用する。次にコード例を示す。あまり良い例とは言えないが、あるノードのidが与えられたときに、そのノードから1hopのすべてのPathを返すような例である(ノードのidとは、Neo4j Browserでノードを選んだときに<id>と表示される番号である。内部的なidなので積極的に使うことは推奨されない)。
@Procedure(value = "example.sample02")
@Description("sample02: return adjacent paths for given node id")
public Stream<Output2> sample02( @Name("id") Long id )
{
Node from_nd = db.getNodeById(id);
Iterable<Relationship> rels = from_nd.getRelationships();
List<Output2> o_l = new ArrayList<Output2>();
for(Relationship rel: rels){
PathImpl.Builder builder = new PathImpl.Builder(from_nd);
builder = builder.push(rel);
Output2 o = new Output2();
o.path = builder.build();
o_l.add(o);
}
return o_l.stream();
}
// result class of sample
public class Output2{
public Path path;
}
ここにでてくるdbとはFullTextIndex.javaに以下のように定義されている。
// This field declares that we need a GraphDatabaseService
// as context when any procedure in this class is invoked
@Context
public GraphDatabaseService db;
GraphDatbaseServiceとは、いわゆるデータベースプロセスに対応するオブジェクトのクラスであり、データベースにアクセスする場合はこのオブジェクトから情報にアクセスしていく。getNodeById()は、そのデータベースのidからNodeを取得するAPIである。そこで指定されたノードに対してgetRelationships()で隣接するRelationship(関連)を取得している。
Pathの作り方は簡単で、builderに対して、Relationshipをpush()していって、完成したらbuild()すればよい。実行結果を次に示す。id1番はKeanu Reeves(さすがにNeo4j!:KeanuはMatrixのNeo役)でその隣接するパスが求められている。最低限、これだけの内容がわかれば、自分で探索アルゴリズムを作成して拡張していくことが可能だろう。