初めに
この記事は現在開催している「新人プログラマ応援イベント」の投稿記事です。
これは何?
初心者が、SQLがどんなものかを理解、書けるようになること目指すための記事です。
理論を軽く説明したのち、具体的な書き方の説明を行なっていきます。
もともと社内勉強会用に用意した資料でしたが、いろいろな人に役立ててもらいたいと思い、Qiitaに投稿することにしました。
SQLを知っている方でも、読むと再度構文の意味などの理解が深まるかもしれません。
説明に誤りなどあれば編集リクエストやコメントをいただければと思います。
理論編
SQLって何?
はじめに、そもそもSQLとはなんなのかを説明します。
SQLと聞くと、以下のようなイメージを持つ方が多いのではないでしょうか?
- DBからデータをとってくるツール?
- DBの検索を行うためのもの?
- SELECT, FROMとか書くやつ
これらのイメージはどれもSQLができることで、SQLがなんなのかの説明ではありません。
僕はSQLは「データをある抽象化された概念として扱えるようにするための言語」だと思っています。
DBの実態はファイルやメモリデータです。これらを直接人間が理解して最適な操作ができるならSQLはいりません。
しかし実態はそんなことはできないことはなんとなくイメージできると思います。できたとしてもコンピュータに比べて途方もない労力と時間がかかるでしょう。
SQLはデータを何に抽象化しているのか?
前項で、SQLは「データをある抽象化された概念として扱えるようにするための言語」と説明しました。
では、SQLはデータを何に抽象化しているのでしょうか?答えは「集合」です。集合とは、ある要素の集まりのことです。
SQLでの操作を行えるデータベース(リレーショナルデータベース)は、SQLでの操作時以下のような構造になっています。
- データベースの中に「テーブル」というスプレッドシートのシートのようなものがある
- テーブルの中には、名前のついた列がいくつか存在する
- 各列の名前=カラム
- テーブルの各行には、各カラムが埋まったデータが存在する
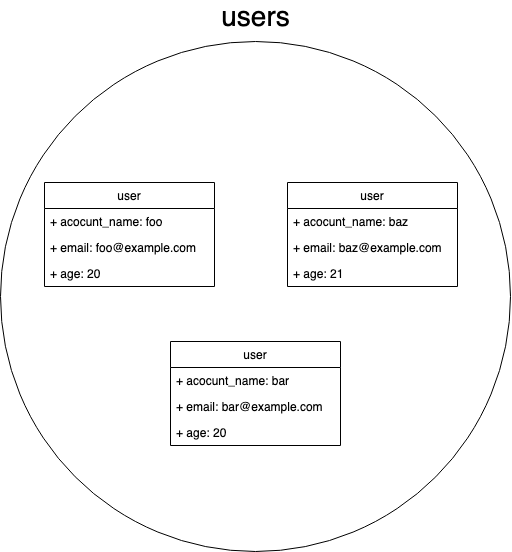
テーブル名: users
| id | account_name | age | |
|---|---|---|---|
| 1 | foo | foo@example.com | 20 |
| 2 | bar | bar@example.com | 20 |
| 3 | baz | baz@example.com | 21 |
| ... | ... | ... | ... |
このような行と列の集まりを以下のように捉えることで、最初に述べた「ある要素の集合」として扱うことができるようになります。
- 集合 = テーブル
- 要素 = カラムの集まり(ベクトル)
テーブルは複数形で書くのが慣習です。これは、テーブルが要素の集合であるためです。
上のテーブル図でいうと、各行の(id, account_name, email, age)の集まりがそれぞれuserであり、その集合であるためテーブル名がusersになります。
まとめ
SQLは何?の答えは、「データを集合として抽象化し、ある集合を新しい集合に変換するための言語」です。こういうものを数学的には写像と言います。
また、SQLが操作できる行 - カラムで表現できるようなデータベースをRDB(関係データベース)といいます。
構文編
基本操作
本題に入る前に基本操作の紹介を行います。
SQLは以下のような構文でカラムの指定とテーブルの指定が行えます。
SELECT *
FROM users;
- カラムはSELECTの後に指定する
- テーブル(集合)の指定はFROMのあとにする
- クエリの終わりにはセミコロンをつける
具体的な操作
SQLが行うのは集合の変換です。行える変換の種類は大きく見ると三つのみになります。
- 絞りこみ
- 集約
- 結合
絞り込み
絞り込みは一番簡単な変換です。ある集合から要素や情報を削ぎ落とす変換になります。
絞り込みには二種類あります。
- 要素の絞り込み
- カラムの絞り込み
要素の絞り込み
要素の絞り込みにはWHERE句を用います。WHEREの後に指定した条件にあう要素だけで新しい集合が作られます。
SELECT *
FROM users
WHERE account_name = 'foo';
WHEREで使える演算子はたくさんあるので、適宜調べてみてください。
カラムの絞り込み
SELECTのあとにカラムを指定すると、そのカラムの要素の集合ができます。* は「全てのカラムを指定する」という意味です。
SELECT account_name, email
FROM users
WHERE account_name = 'foo';
集約
集約とは、「集合の要素をまとめあげて、その集計情報によって新しい集合を作る変換」です。GROUP BY句を用いて行うことができるます。
GROUP BYに指定したカラムのみSELECT句にかけます。逆に他のカラムは指定できず、集計関数を用いて集計した値にする必要があります。
例で、年齢ごとのユーザーの数を抽出するクエリを書きます。
SELECT age, COUNT(*) AS user_count
FROM users
GROUP BY age;
結果
| age | user_count |
|---|---|
| 20 | 2 |
| 21 | 1 |
GROUP BYは何をやっているのか?
GROUP BYは集合がどのような集合に変換されているのかがイメージしづらいので、もう少し説明します。
GROUP BYは指定したカラムによって集合を分ける構文です。
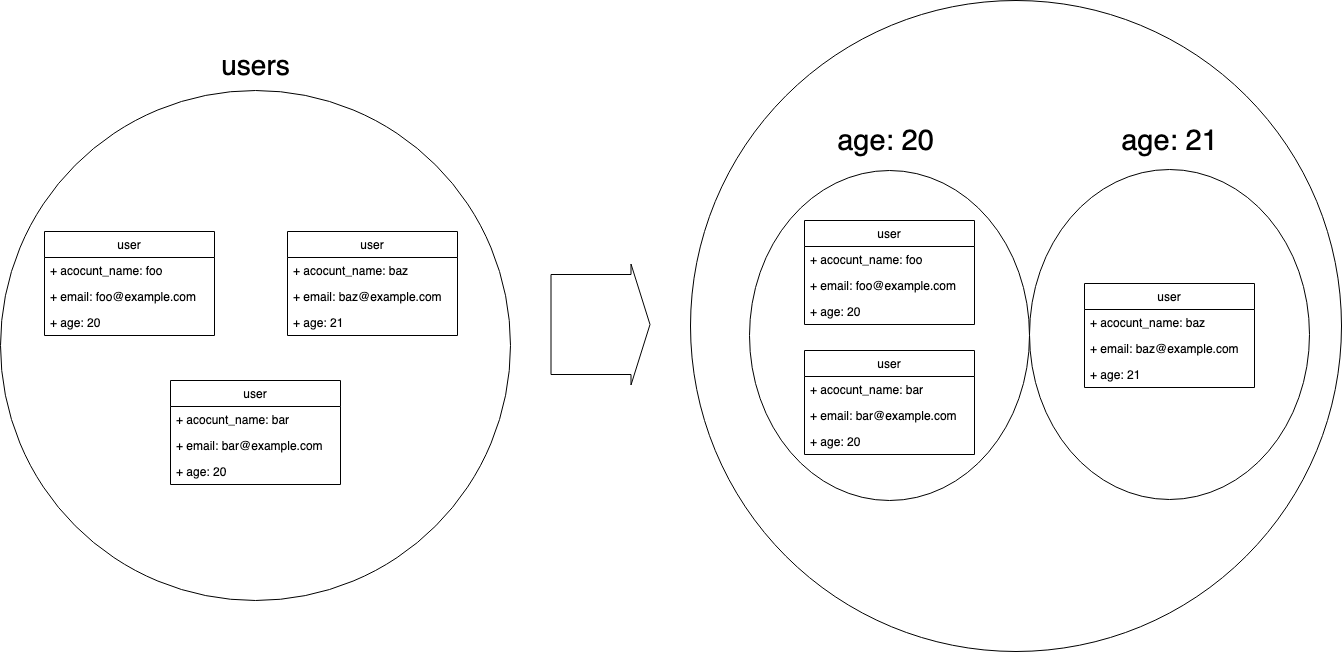
GROUP BYで指定したカラムはSELECT句に指定できますが、それ以外は、図から分かる通り、GROUP BYで集約された要素のうち、どの値を参照するかがわからないため、そのままでは指定することができません。COUNTなどの集計関数はGROUP BYによって作られた要素としての集合を数値に変換するものです。
結合
結合は、複数の集合に関係を持たせ、新しい要素の集合を作る変換です。SQLで一番重要な変換であり、RDBの名前の由来でもあります。
結合は、複数の集合(テーブル)を結合して、1つの集合に変換する処理です。
普段の生活の中で、何かを自分のものだと全ての人がわかるようにするために、どのようなことをしますか?おそらく自分の所有物に名前をつけたり、自分のものだと分かるように印をつけるのではないでしょうか。RDBも同じような考え方でテーブル同士に関係を持たせます。各テーブルに所有関係を持たせたい時、所有される側に所有者のidを保存します。このような所有されている側のidを「外部キー」と読んだりします。
関係には以下のような種類があります。
- 1 : N→あるテーブルの要素がある別のテーブルの複数の要素と関係がある
- 例: Qiitaのユーザーとそのユーザーが書いた記事
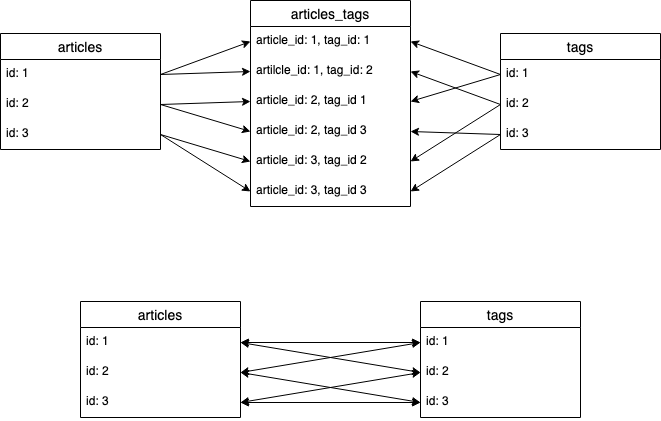
- N : N→二つのテーブルがお互いからみて1 : Nになるような関係
- 例: Qiitaの記事とタグ
- 記事は複数タグを持てるので 1 : N
- タグは複数の記事につけられるので 1 : N
- 例: Qiitaの記事とタグ
1 : Nの関係は、所有される側に外部キーを持たせるだけで表現できますが、N : Nの関係は「中間テーブル」というテクニックを用いる必要があります。中間テーブルとは「二つのテーブルの外部キーを持つテーブル」です。このようなテーブルを作ることで、各テーブルと中間テーブルの関係は1 : Nになります。この状態で、中間テーブルを無視すると、2つのテーブルはN : Nの関係になります。
結合の種類
結合には以下の三種類があります。
- 内部結合
- 左外部結合
- 右外部結合
書き方はほぼ同ですが、結果が異なります。
ここからの説明では、以下のようなテーブルを例にして説明を行なっていきます。
テーブル名: users
| id | account_name | |
|---|---|---|
| 1 | foo | foo@example.com |
| 2 | bar | bar@example.com |
| 3 | baz | baz@example.com |
テーブル名: articles
| id | title | user_id |
|---|---|---|
| 1 | foo | 1 |
| 2 | foo2 | 1 |
| 3 | bar | 2 |
| 4 | hoge | 4 |
内部結合
内部結合は、結合しようとしたテーブル先に関係のある要素がなかった要素が除外される
例:ユーザーとユーザーが書いた記事を結合する
SELECT users.account_name AS user_account_name, articles.title AS title
FROM users
INNER JOIN articles ON users.id = articles.user_id;
結果
| user_account_name | title |
|---|---|
| foo | foo |
| foo | foo2 |
| bar | bar |
内部結合では、記事を投稿していないユーザー(baz)は除外されます。
INNER JOINはFROMにかかっていいるので、FROMで指定している集合をINNER JOINで変換しているようなイメージを持っておくと
構文のイメージもつきやすいと思います。
例えば、WHERE 句などはINNER JOINの後に記述します。(INNER JOINを行なって結合したテーブルの絞り込みも行える)
左外部結合
左外部結合も、構文の書き方自体は内部結合と変わりません。ただ、左外部結合は結合元の要素に関連する要素がなくても、結合元のデータを残します。
SELECT users.account_name AS user_account_name, articles.title AS title
FROM users
LEFT OUTER JOIN articles ON users.id = articles.user_id;
結果
| user_account_name | title |
|---|---|
| foo | foo |
| foo | foo2 |
| bar | bar |
| baz | NULL |
左外部結合では、記事を投稿していないユーザーも表示されます(titleがNULLになる)
右外部結合
文字通り左外部結合の逆です。
SELECT users.account_name AS user_account_name, articles.title AS title
FROM users
RIGHT OUTER JOIN articles ON users.id = articles.user_id;
結果
| user_account_name | title |
|---|---|
| foo | foo |
| foo | foo2 |
| bar | bar |
| NULL | hoge |