みなさん、こんにちは!
NTTドコモ クロステック開発部の片山です!
今年入社の新入社員です。
コロナ禍真っ只中の入社となってしまい、自分だけでなく周囲もてんやわんやで気づけば2020年も終わろうとしています。本当に早かった(笑)
仕事もコロナの影響で在宅勤務にシフトしつつあるので、オンラインでのコミュニケーションが中心になり、同じ部署の同期ですらあまりコミュニケーションが取れていないのが現状です。
そんな今だからこそ、同期でチームを組んで何かに取り組むことで、スキルの向上はさることながら、お互いの繋がりを深められるのではというモチベーションでPWS Cupに参加しました!
本記事では、PWS Cupというデータに対する匿名化と攻撃の技術を競うコンテストへの参加記を紹介します!
特に、本コンテストで猛威を振るったメタヒューリスティクスの活用は幅広い場面での応用が考えられると思います。
参加メンバーと投稿内容(目次)を以下に記載します。
参加メンバー
NTTドコモ クロステック開発部
・片山 源太郎
・北井 宏昌
・酒井 亮勢
・野澤 一真
・三枝 健吾
目次
1. PWS Cupの概要
PWS Cupは今年で6回目となる、**データに対する匿名化と攻撃の技術を競うコンテストです。
各参加チームは、
➀与えられたデータを攻撃されないよう匿名化するタスク
➁他の参加チームが匿名化したデータを攻撃するタスク
を行います。
今回のコンテストの特徴は、安全性の指標にメンバシップ推定攻撃(Membership Inference Attacks)**を使用していることです。
メンバーシップ推定攻撃
メンバシップ推定攻撃は、匿名化されたデータに誰のデータが含まれているかを推定する攻撃です。
この攻撃は機械学習分野で注目されている疑似データ生成を含む、多くの匿名化手法の安全性指標として利用できると言われています。
実際、NeurIPS 2020 のコンテストhide-and-seek privacy challengeでも同様の攻撃が取り上げられました。
また、昨今の新型コロナウイルス感染者のデータ分析など、学習データに含まれるコロナウイルス罹患者である個人の存在を示す情報が機微となる場合にも関係する攻撃です。
2. PWS Cupのルール
コンテストルールの概要を以下の図に示します。
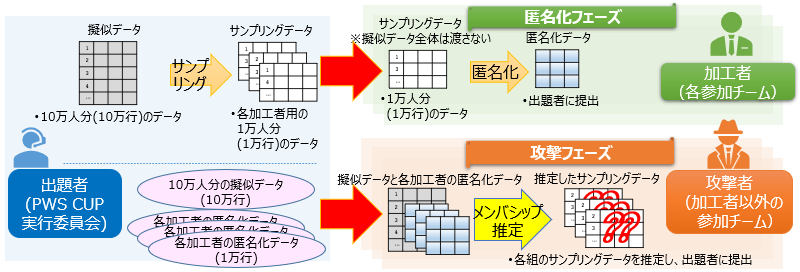
(引用:PWSカップ2020ルール詳細資料)
図に示す通り、コンテストは匿名化フェーズと攻撃フェーズから成ります。
匿名化フェーズでは、与えられたデータに対する攻撃手法を予想してデータの匿名化を行います。
攻撃フェーズでは、匿名化フェーズで各チームが匿名化したデータを攻撃します。
匿名化フェーズ
匿名化とは、ある情報をデータから知ることができないようにデータを加工する手法一般のことを言います。
例えば、以下のような処理も匿名化と言えます。
- 年齢の正確な値を漏洩させないために、誤差を加える
- メールアドレスを漏洩させないために、メールアドレスのカラムを削除
上記のいずれの処理も、データから知られたくない情報があって、それを隠すような処理をしているという点で共通です。
勘の良い方ならお分かりの通り、最強の匿名化はデータを削除することです。
しかし、安易にデータを削除するといった匿名化をした場合、安全性は高まりますが、データの有用性は著しく低下します。
なので、匿名化を行う際には、安全性指標と有用性指標を定義し、両者をバランスするような処理を考える必要があります。
このため、今回のコンテストでも安全性指標と有用性指標が定義されています。
安全性指標
今回のコンテストにおける安全性指標には、相手チームによる攻撃の達成度合いの最大値を利用します。
つまり、最も攻撃を達成されてしまった場合において、どの程度情報を守ることができたのか?を定量化しています。
安全性 = 1 - \max(全チームの攻撃達成度合い)
具体的な「全チームの攻撃達成度合い」の定義については、攻撃フェーズのセクションで説明します。
有用性指標
今回のコンテストにおける有用性指標は、4つの有用性指標を使用します。
いずれの有用性も匿名化前のデータと匿名化後のデータを比較することで算出されます。
| 有用性指標 | 説明 | 閾値 |
|---|---|---|
| ヒストグラム指標 | 匿名化前後のデータのヒストグラムの誤差を定量化 | 0.97 |
| 相関係数指標 | 匿名化前後のデータの相関係数の誤差を定量化 | 0.90 |
| 決定木指標1 | 匿名化前後のデータからそれぞれあるデータを予測する決定木を学習し、出力の誤差を定量化 | 0.95 |
| 決定木指標2 | 同上(別の予測タスク) | 0.95 |
有用性指標には閾値があり、提出する匿名化データは有用性指標が閾値以上の有用性を持つ必要があります。
匿名化の具体的手順
方針1. 有用性指標を閾値以上にする
方針2. メンバーシップ推定攻撃を防ぐような匿名化をする
各チームは疑似データ(10万人分)からランダムサンプリングされたサンプリングデータ(1万人分)を上記方針に沿って匿名化し、匿名化データを作成・運営に提出します。
攻撃フェーズ
(匿名化と対の意味での)攻撃とは、ある情報をデータから得るために最大限の工夫を行う手法のことを言います。
今回は上述の通り、メンバシップ推定攻撃を行うため与えられた匿名化データ中の特定個人の存在有無を得るような攻撃を行います。
特に今回は、攻撃者が任意に選択可能な特定の100人に対して攻撃を行います。この選んだ100人のうち、真に匿名化データ中に含まれていた人数が攻撃達成度合い(正解率)となります。
参照可能な情報は、疑似データ(元データ)と匿名化データです。(サンプリングデータは当然参照できません)
攻撃の具体的手順
- 各チームは自チーム以外の匿名化データが運営から配布
- 各匿名化データを攻撃 : 疑似データ10万人のうち匿名化データに含まれていそうな100人のリストを作成・提出
3. 匿名化手法の解説
本章では、多くのチームが使用していた焼きなまし法による匿名化について説明します。
予想される攻撃と対策
原始的な攻撃手法として、匿名化データと疑似データ(元データ)のレコード間のユークリッド距離を計算し、匿名化データの各レコードに対し、最もユークリッド距離が小さい疑似データ(元データ)を探索するという攻撃(距離攻撃)があります。(サンプルコードとしても運営から提供されています)
この攻撃への対策としては、匿名化データとサンプリングデータ(匿名化前のデータ)の距離を離すような誤差を加えることが考えられます。誤差を加えるにあたり、有用性指標が閾値を満たす必要があるため、有用性指標が閾値に近いような匿名化データを生成することが求められます。
ここで、有用性指標が閾値に近い匿名化データを生成する方法は2通り考えられます。
1つ目は、サンプリングデータ(匿名化前)のデータへの誤差を調整することによって、有用性を閾値まで下げる方法
2つ目は、疑似データを生成方法を工夫し、生成後のデータ(匿名化データ)の有用性指標を閾値まで上げる方法
1つ目はボトムアップアプローチ、2つ目はトップダウンアプローチなどとプライバシー保護の領域において呼ばれる考え方に近いです。
※有用性を下げる⇔安全性を上げる であり、セキュリティでは安全性が主語であることが多いため1つ目はボトムアップという表現になります。
今回のコンテストでは、マクロな指標(データ全体に対しての指標)を満たせば良く、つまり各レコードに関する有用性指標が存在しないことから、トップダウンアプローチ(2つ目の方法)の方がより攻撃が難しい匿名化データを生成できることが期待されます。
実際、コンテストでもトップダウンアプローチによる匿名化が席捲し、上位チームの多くは個別のアルゴリズムは異なれど、トップダウンアプローチを採用していました。
特に、サンプルで与えられた疑似データ生成アルゴリズムとメタヒューリスティックな手法(焼きなまし法や遺伝的アルゴリズム等)を組み合わせた手法を使っているチームが多くありました。
本記事では、特に複数の上位チームが使用していた焼きなまし法と疑似データ生成を組み合わせた匿名化手法について紹介します。
焼きなまし法による匿名化
擬似データ生成
匿名化手法として、岡田らの擬似データ生成アルゴリズム1の実装コードがサンプルコードとして提供されています。
| ヒストグラム指標 | 相関係数指標 | 決定木指標1 | 決定木指標2 | |
|---|---|---|---|---|
| 生成されたデータの有用性指標 | 0.934 | 0.800 | 0.843 | 0.964 |
| (閾値) | 0.970 | 0.900 | 0.950 | 0.950 |
| 有用性の基準を満足しているか? | × | × | × | 〇 |
結果を見ると、岡田らの疑似データ生成アルゴリズムの特徴である元データのヒストグラムや属性間の相関係数を継承する特徴が活き、匿名化前後のヒストグラムや相関係数がある程度維持されていることがわかります。
しかし、上述のように有用性指標が閾値を超える指標は決定木分析2のみであり、それ以外の有用性指標は閾値を満たしていません。
つまり、有用性指標を高めるためのその他の戦略を考える必要があるということになります。
有用性指標を向上させる戦略
トップダウンアプローチから有用性指標を向上させるための戦略は以下の3つがあります。
- 有用性指標が閾値を上回るまで、データ生成を繰り返す(岡田らの疑似データ生成アルゴリズムは確率的アルゴリズムです)
- 生成されたデータに対し、有用性を高めるような処理をする
- より厳格にヒストグラムや相関係数が一致するデータを生成するように岡田らのアルゴリズムを改良する
今回のゴールは有用性指標が閾値を上回る匿名化データを生成することなので、どの戦略を取っても問題ありません。
ただ、上記戦略は1.から3.の順番で手法としては単純だと思われるので、1.で済むなら1.の戦略を取りたいという気持ちになります。
なので、まずは1.有用性指標が閾値を上回るまで、データ生成を繰り返すという戦略を考えていきます。
とはいえ、当然独立に100万回疑似データ生成アルゴリズムを実行すれば解決するという問題ではありません。
実際、手元で約1000万回疑似データ生成を行いましたが、有用性指標の閾値を上回るデータが生成されることはありませんでした。
そこで、岡田らのアルゴリズムを道具として使いつつ、メタヒューリスティクスを導入して、効率よく有用性指標が閾値を上回るような匿名化データを生成するという方法が考えられます。メタヒューリスティクスは、特定の問題に依存せず解を探索できるようなアルゴリズムの総称です。
実際、多くの上位チームはこうした考えの下(実態は知りませんが)、メタヒューリスティクスを匿名化に導入していました。
上位チームが使用していたメタヒューリスティクスとしては、焼きなまし法や遺伝的アルゴリズムがありました。
いずれのアルゴリズムであっても、有用性指標が閾値を上回る匿名化データを生成できれば良いので、どのアルゴリズムを用いても良いのですが、今回は多くのチームが用いていた焼きなまし法についての解説と再実装をした結果についてご説明をします。
焼きなまし法(Simulated Annealing)
焼きなまし法は、ヒューリスティックスの一つで、アルゴリズムは以下のようになります。
- 変更する変数をランダムに選び、いずれかの方向にずらす
- 変更前と変更後でコストを計算し、両者を比較する
- 変更後のコストの方が小さければ採用する。変更後のコストの方が大きければ確率的に採用する。確率は反復回数に応じて更新する。
- 反復回数だけ1から3を繰り返す。
焼きなまし法では、変更後のコストが大きい場合でも確率的に採用するため、局所最小解を回避することができる点が大きな特徴です。
本記事では、焼きなまし法を用いて、有用性指標が閾値を上回る疑似データを生成することを考えていきます。
有用性指標からコストを計算するコスト関数を
E(x) = \sum_{ m \in 4つの有用性指標 } min(0, x_m - x_{m,threshold})
と定義します。$x_{m}$は各有用性指標の値、$x_{m,threshold}$は有用性指標の閾値を表します。
焼きなまし法を導入した擬似データ生成アルゴリズムは以下に示す通りです。
- 岡田らのアルゴリズムを用いて10,000レコードの疑似データを生成し、これを初期の匿名化データとする。
- 岡田らのアルゴリズムを用いて10,000レコードの疑似データを生成する。このデータと匿名化データの一部を交換することで焼きなまし法の手順1を実装する。
- 匿名化データのうち$m$レコードを擬似データと交換し、$E(x)$がそれまでの最小値より小さい場合、そのデータを匿名化データとして採用する。大きい場合も、確率$p$でそのデータを匿名化データとして採用する
- 3.を有用性指標が閾値を上回る匿名化データが生成されるまで行う
焼きなまし法の結果
焼きなまし法を用いることで、有用性指標を閾値に近い匿名化データを生成することができた。
最終的な結果は以下の通りとなった。
| ヒストグラム指標 | 相関係数指標 | 決定木指標1 | 決定木指標2 | |
|---|---|---|---|---|
| (閾値) | 0.970 | 0.900 | 0.950 | 0.950 |
| 焼きなまし法(初期値) | 0.908 | 0.779 | 0.8623 | 0.964 |
| 焼きなまし法(37700回目) | 0.946 | 0.901 | 0.976 | 0.968 |
| 有用性の基準を満足しているか? | × | 〇 | 〇 | 〇 |
今回の実験では結果として、ヒストグラム指標を超えるまでには至らなかったが、もっとも有用性が高いデータは更新され続けており、更に回数を重ねることで有用性指標の閾値を上回る匿名化データが生成できると考えられます。
また、焼きなまし法である程度有用性指標を高めてから、別途ルールベースなデータ処理を行うことで有用性を向上させることもできます。
以上から、焼きなまし法を用いてトップダウンアプローチで有用性指標を上回る匿名化データを生成し得ることがわかります。
また、各メタヒューリスティクスに得意不得意はあれど、ヒューリスティクスであるという点では同じことから、その他のメタヒューリスティクス(例えば遺伝的アルゴリズム)であっても、同様のことが達成でき得ると言えると思います。
4. 攻撃手法の解説
本章では、クラスタリング手法を用いた攻撃と機械学習を用いた攻撃の2つについて紹介します。
ただ、結果的に本コンテストの結果、最も優秀な匿名化を行ったチームへの有効な攻撃は無い(見つからない)という結論となりました。
(どの攻撃アルゴリズムも匿名化データを見ずに乱択するアルゴリズムと有意な差がありませんでした)
(1)クラスタリング手法を用いた攻撃
方針
次にクラスタリング手法を用いた攻撃手法を説明します。擬似データと匿名化データをOne-Hotエンコーディングし、ベクトル空間で表現すると位置が擬似データと匿名化データで異なります。匿名前と匿名後のベクトル空間での差が大きくなれば、匿名化データから擬似データを推定することが難しくなります。
この問題を解決するために、**擬似データと匿名化データをクラスタリングして、双方のクラスタの重心からの距離を使用した推定方法を試しました。**One-Hotエンコーディング後の擬似データと匿名化データの位置は大きく異なっていても、匿名化データのクラスタの重心からの距離は匿名加工前の擬似データと変化が少ないと予想し、クラスタリングを使用しました。今回、クラスタリング手法はよく使われているk-means法を使用しました。
クラスタリング後に擬似データと匿名化データのクラスタの特徴が似ているものだけで推定することも考えられます。しかし、完全にクラスタで分けてしまうと選択したクラスタに擬似データと匿名化データが含まれていない場合に推定ができないと考え、クラスターの重心からの距離概念を使用して、擬似データと匿名化データがクラスタが異なっていても、推定が可能な方式を目指しました。
手順
k-means法を使用したクラスタリング手法による推定の手順は下記の通りです。
1.擬似データと匿名化データをそれぞれOne-Hotエンコーディングを用いて、数値化
2.One-Hotエンコーディング後の擬似データと匿名化データをk-means法を用いて、双方をクラスタリング
3.擬似データと匿名化データを各クラスターの重心との距離で表現されるk次元の距離空間に変換(kについてはチューニングを実施)
4.3の距離空間で擬似データから匿名化データを推定(今回はユークリッド距離による推定を実施)
5.距離でソートし、上位100個を選出
今回はPWSカップで配布されたサンプルデータと予備選の匿名化データに対して、上記のクラスタリングによる攻撃手法を実施しました。また、クラスタリングによる攻撃手法の有効性を確認するためにk-means法をせずにユーグリッド距離のみで推定する手法を安全性で比較しました。
結果と考察
PWSカップで配布されたサンプルデータと予備選の匿名化データを攻撃したときの安全性の結果です。安全性が高い程、攻撃に成功したことを意味しています。
| サンプルデータ | 予備選データ | |
|---|---|---|
| ユーグリッド距離のみ | 0.37 | 0.44 |
| k-means法+ユーグリッド距離 | 0.41 | 0.47 |
上記より、ユーグリット距離のみの手法よりもk-means法を取り入れ、クラスターの重心からの距離を参考にして、攻撃した方が安全性が高い(より攻撃が成功した)結果となりました。しかし、大幅に推定結果が向上したわけではないので、さらなる改善が必要だと考えられます。さらに安全性が高い攻撃手法にするためには、k-means法以外のクラスタリング手法で試すことやクラスタリング後のユーグリット距離による推定を異なる推定方法を試すことが考えられます。
(2) 機械学習を活用した攻撃
やりたかった理想(アイデア)
今回のタスクでは、10万の元データから各チームに1万のサンプルデータが提供され、各チームはそれを匿名化する(匿名化フェーズ)とともに、他チームの匿名化データからどのユーザがサンプリングされたかを推定する(攻撃フェーズ)ものでした。
本取り組みは攻撃フェーズへ焦点を当てたものです。
考え方はシンプルで属性情報(性別や年齢等)を説明変数、ユーザ名(10万の元データのインデックス)を目的変数として分類のためのモデリングを行い、匿名化データの分類を行います。利用データのイメージは下記の表の通りです。
| ユーザ(インデックス) | age | sex | ... |
|---|---|---|---|
| 1 | 25 | male | ... |
| ... | ... | ... | ... |
| 100000 | 17 | male | ... |
サンプリングデータに対して様々な匿名化手法を適用することで学習データにバリエーションを持たせることができます。
学習データ取得までの具体的な流れは以下の通りです(画像見た方が早いかもしれません)。
- 10万の元データから複数の1万人分のサンプリングデータを取得
- 各サンプリングデータ(1万人分)へ様々な匿名化手法を適用し、匿名化データを取得
- その際、元のインデックスを保持したまま任意の人数の匿名化データを出力**(複数可)**
- 全てのアウトプットを結合
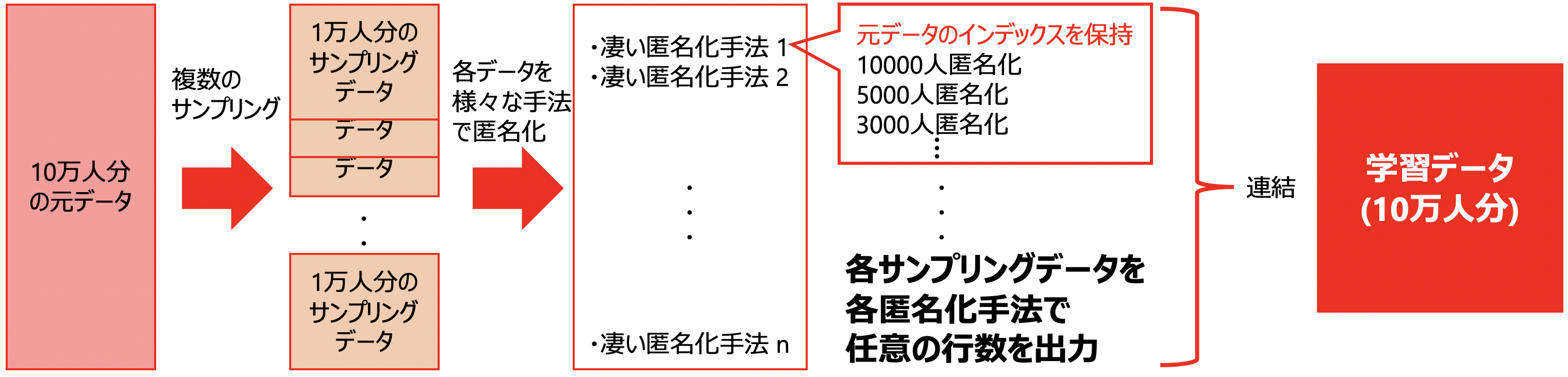
学習データを用いて各インデックスを識別するように学習させます。
学習モデルに匿名化データを入力してどのインデックスに尤も当てはまるかを推定します。一人のユーザに対してインデックスが1から100000までの予測確率(類似度)を算出します。10万の予測のうち、確率の最も高いインデックスを予測ラベルとします。なお、下図の数字はイメージです。

なお、コンテストにおける実際のタスクは1万人分の予測のうち、最も自身のある100人をアウトプットとするというものでした。そのため、本手法では1万ユーザのインデックスを予測した際の確率(類似度)が高い100件を予測ユーザとします。
「凄いモデル」と記載した部分に関しては、まずはLightGBMを想定していますが、分類タスクなので何でもOKで、複数試してアンサンブル的なことをするのがよいと思います。
現実(問題点)
お気づきの方も多いと思いますが、上記の方法はいくつかの問題を抱えています。
匿名化手法の問題
匿名化後のデータが匿名化前のデータのインデックスを保持している前提でした。実際のほとんどの匿名化手法は、1レコードに対応した匿名化データ1レコードをアウトプットするわけではなく、あくまで全体の特徴を保持した「集団」の匿名化データとなっております。そのため、実際に実現するためには、同時に匿名化手法を検討する必要があります。
とはいえ、匿名化前と匿名化後で何らかの共通の特徴量を持っていると考えられます。そのため、匿名化前のデータを学習したモデルであっても、匿名化後のデータを識別できる可能性はあります。
例えば、インデックス"000000"を含む計100のレコードから50レコードの匿名化データを生成したとします。この匿名化データは"000000"の情報をもとに作られているため、"000000"と予測する確率はある程度高くなると言えます。
データ量の問題
仮に上記で言及した匿名化手法を複数用意することができたとして、データのサイズは膨大になります。
例えば、サンプリング回数100回(1回あたり10000人サンプリング)、匿名化手法10種適用した場合、1000万レコードのデータとなります。
この解決方法は下記を想定しております。
- 次元圧縮をする
- マシンパワーで頑張る
クラス数の問題
理想論の中で最もネックなのがクラス数の問題です。
前項目でデータサイズの話をしましたが多少多いくらいでは動くので、下記の通り一度試してみました。
1万人のサンプリングを200回、匿名化手法は1種で各1万件出力、すなわち、200万レコードの学習データを生成しました。
前処理を行い、いざ学習を行おうとしましたが、学習は回らずカーネルは落ちました。
思考停止で10万クラス分類は無謀だったようです。
そこで、この超多クラス分類を解くために以下を議論・検討しました。
-
AnnexMLの利用
数万から数百万クラスの超多クラス分類を高速かつ高精度に行える分類機です。
10万のラベルを分類しようとしていた本タスクには妥当な気がしますが、時間的かつ環境的な都合から実装・実験には至っておりません。 -
2値分類を10万回
10万クラス分類の代替として2クラス分類を10万回行うということが考えられます。
すなわち、あるラベルがついたデータとそれ以外の99999クラス分のデータに分けて学習を行います。
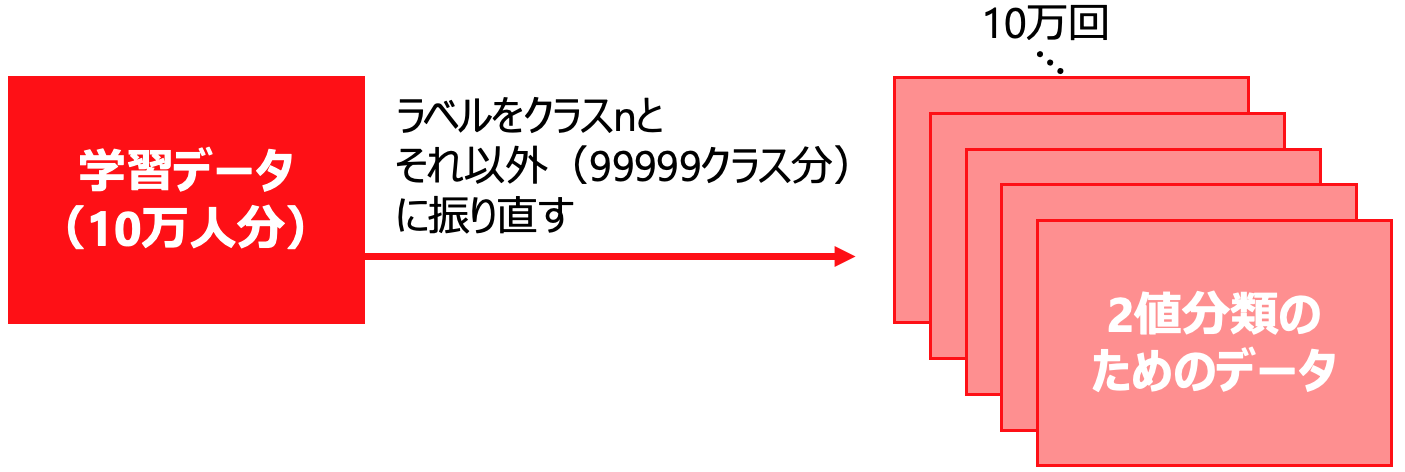
例えば、ある匿名化データが入力された時、10万個のモデルを用いて分類を行います。各ラベルに該当するかどうかの2値分類を行い、該当するものの中で最も確率(類似度)の高いラベルに分類します。
しかし、この手法で動くとしても、膨大な計算時間がかかります。
数百万件のデータの学習モデルを10万個作るため、この部分がネックとなります。
また、1ユーザの識別1つとっても10万のモデルで予測値を取り最大をとって...というように、時間がかかりすぎて気軽にできるものではありませんでした。
そこで、次節のような小実験を行い、クラス分類によるメンバシップ推定の実現可能性を検討をしたいと思います。
実現可能性を探るための仮説及び小実験
【仮説】特定のユーザかどうかを判定する分類器に無関係なデータを入力するより、該当ユーザの匿名化データを入れた方が予測確率(類似度)が高い→機械学習のモデリングにより、匿名化データに反応する特徴を捉えられたと言える。
※例えば、ユーザIDが1かそれ以外かの二値分類を行う分類器にユーザIDが1の匿名化データを入力するとその予測確率は高くなります。一方でユーザIDが1以外の匿名化データを入力してもユーザIDが1と分類する確率は高くないと言えます。
上記の仮説を検証するために、下記の手順で小実験を行いました。
【匿名化データに含まれるユーザのモデリングのためのデータ作成】
- 10万人のデータから1万人をサンプリング
- サンプリングデータに含まれる1人のユーザデータを抽出
- 抽出したユーザを何らかの方法で任意の数(今回は100)水増し(今回は単純に複製)
- 10万人の元データのうちサンプリング以外のデータ(計9万人)から100人抽出
- 3と4を連結し、A_1とする(計200レコード)
- 2〜5を繰り返し、A_1〜A_100を作成する。
【匿名化データに含まれないユーザのモデリングのためのデータ作成】
7. 10万人の元データのうちサンプリング以外のデータ(計9万人)から1人のユーザデータを抽出
8. 抽出したユーザを何らかの方法で任意の数(今回は100)水増し(今回は単純に複製)
9. 10万人の元データのうちサンプリング以外のデータ(計9万人)から7以外のユーザを100人抽出
10. 5,6同様にB_1〜B_100を作成する
【検証について】
11. 各データ(A_1〜A_100, B_1〜B_100)で対象ユーザとそれ以外かの2値分類をするように学習(モデルは計200)
12. 1の匿名化データを各モデルへ入力する
13. Aから作られたモデルの出力とBから作成されたモデルの出力の違いを確認する
※なお、利用したデータはPWS Cup2020のサンプルで、10万の元データがtrial_syntheticdata.csv, 1万のサンプリングデータがtrial_samplingdata.csv, 匿名化データがtrial_anonymizeddata{n}.csv(使用された匿名化手法は4つでnは1-4)となります。
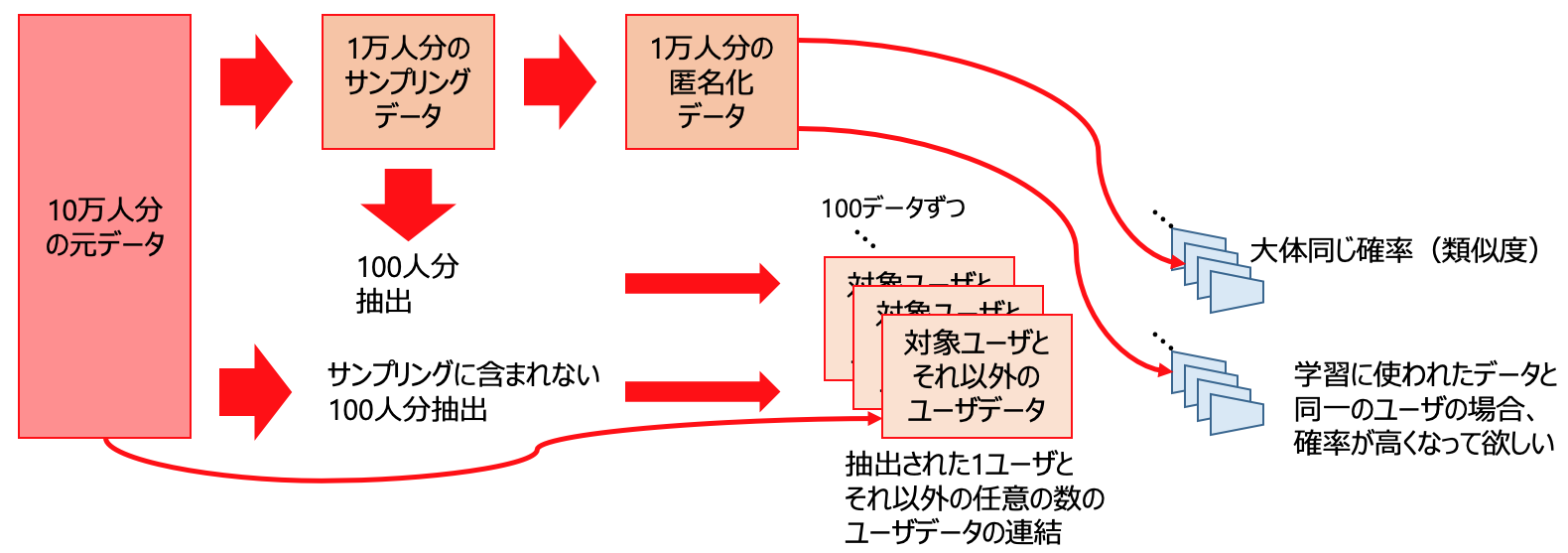
上記の小実験の肝は、Aデータには検証時のユーザが1人含まれており、Bデータには含まれていないということです。
例えば、Aデータの1つがユーザインデックスが"000000"とそれ以外だったとします。このデータからユーザ"000000"とそれ以外の2クラス分類をするように学習するため、"000000"のデータ(あるいは"000000"を強く反映した匿名化データ)の入力があった際は高い確率が出力されると考えられます。
"000000"は入力の匿名化データに含まれているため、関連するレコードは高い確率が出力され、他の行は高くはない確率が取得されるものと予想します。
すなわち、「1万行の入力に対する出力の最大値を取るとそれなりに高い値が得られる」という考えの基、上記の実験を行います。
一方で、Bデータで仮に"100000"とそれ以外に分類するようにモデルを作成したとして、検証データには"100000"が含まれていないため、全ての入力が高くはない値を出力すると想定しております。つまり、1万行の入力に対する最大をとっても高いスコアにはならないと言えます。
上記の(Aから作成されたモデルの出力の最大がBよりも高いという)仮説が正しければ、学習時に匿名化データを識別するための何らかの特徴量を抽出することができており、10万のデータにラベル付けして分類を行うことができるという可能性を示唆することができると考えます。
実験結果
実際に実験を行ってみました。
手法はLightGBMで5分割交差検証を行いました。
表のスコアは、Aデータから作られたモデル100個、Bデータから作られたモデル100個に各匿名化データを入力し、各出力の最大値を平均したもの(±標準偏差)です。
| 学習データ\入力データ(匿名化) | 匿名化1 | 匿名化2 | 匿名化3 | 匿名化4 |
|---|---|---|---|---|
| Aデータ | 0.774±0.343 | 0.919±0.198 | 0.897±0.201 | 0.612±0.401 |
| Bデータ | 0.787±0.344 | 0.939±0.153 | 0.903±0.204 | 0.711±0.378 |
Aデータがサンプリングに含まれるユーザで学習をし、Bが含まれないユーザのモデルであるため、結果は想定したものとは異なりました。ランダムにユーザ選択をする際のシード値を変更して同様の実験を行いましたが、同様の結果が得られました。
また、最大値のみではなく、予測値の高い順で入力の1%(100個)の平均をとり、上記と同様の結果を下記の通り出力しましたが、同様の結果となりました。
| 学習データ\入力データ(匿名化) | 匿名化1 | 匿名化2 | 匿名化3 | 匿名化4 |
|---|---|---|---|---|
| Aデータ | 0.417±0.354 | 0.654±0.328 | 0.516±0.356 | 0.125±0.156 |
| Bデータ | 0.516±0.372 | 0.725±0.309 | 0.580±0.358 | 0.180±0.199 |
考察
想定と真逆の結果となった要因として、以下の2点が考えられます。
-
学習データの質
学習というのは通常、類似の複数のデータにラベルがつけられそこからパターンを発見していくものですが、本実験における対象ユーザのデータは諸々の理由から単純なコピーで補いました。それにより、過学習ないし適切な学習が行えていない可能性が高いと言えます。言い換えると、メンバシップ推定を行うにあたり高精度な分類器を生成できておりません。 -
匿名化手法の性能
今回の実験結果における、Aのモデルでスコアが低くなることは「匿名化されたデータから元のデータを推定しづらい」状態を意味しています。一方、Bのモデルでスコアが高くなることは「匿名化データから本来サンプリングデータに含まれないユーザを推定している」状態を意味しています。
この2点から言えることは、匿名化というフィルタは、本来偽装したいデータを秘匿し、無関係なデータと誤認識させるような本来の匿名化の役割を果たしているということです。
つまり、匿名化が本来の役割を果たしているため、今回の無関係なデータと認識しやすいという結果となったと考察します。
ただし、今回の実験結果及び考察により分類タスクによるメンバシップ推定が有効な手段ではないと断言することはできません。考察で述べた通り、学習データ(モデル)の質が低く、匿名化手法の質が高いため、今回の結果となったと言えます。
つまり、学習データ(モデル)の精度 > 匿名化の性能 が成り立つ場合に、分類タスクで匿名化データから元ユーザを推定できるようになると考えております。
そのためには、学習データの単純な複製ではない水増しや、インデックスを保持したまま匿名化できる様々な手法でデータを生成することにより、匿名化というフィルタに対して頑健なモデルの生成が可能になると考えます。
(2)機械学習を用いた攻撃についてのまとめ
匿名化データに含まれる元のデータを予測するために、分類タスクに落とし込み、10万クラス分類を検討しました。単純に10万クラス分類を行うことが難しかったため、2クラス分類を10万回行うという代替案を出したものの計算時間の都合上こちらも現実的ではありませんでした。
そこで、上記の実現可能性を確認するために、サンプリングデータに含まれるユーザの特徴量を捉えられるかの小実験を実施しました。
今回は、
学習データ(モデル)の精度 < 匿名化の性能
となったため、仮説の実証はできませんでした。
コンペは終了しましたが、後学のために仮説を実証したいと考えており、以下の観点で改めて検討・実験していきたいと思います。
- 今回の実験結果を改めて考察
- ノイズを加える等で学習データの水増し
- インデックスを保持したまま匿名化できる手法の検討
- 上記2点で本実験と同様のものを実施
- 実際に2値分類を10万回行いメンバシップ推定
- 超多クラス分類手法で10万クラス分類の実施
参考文献
- 数えきれないほどの分類を行うExtreme Classification
- 【論文メモ】AnnexML: Approximate Nearest Neighbor Search for Extreme Multi-label Classification
4. まとめ
今回のPWS Cupを通じて、疑似データ生成が匿名化として活用し得るということを実感をもって知ることができました。
思ったような結果を残すことはできませんでしたが、この機会に改めてプライバシー保護について見つめなおす良い機会となりました。
私も普段の業務でお客様にまつわる様々なデータを取り扱うことが多いですが、お客さまにより良いサービスを届けるという使命とともに、プライバシーへの配慮を常に意識し続けています。
そうした中で、一般に極端なトレードオフ関係になりがちなお客さまのプライバシーとデータ分析業務について、技術による解決を図るプライバシー保護技術は今後データ社会になるにつれ、より一層重要性を増していくと改めて感じました。
今後もプライバシー保護技術の動向はしっかりとウォッチしていきたいと思います!
また、今回は新入社員の同期で挑戦した初めての取り組みでした。スケジュール管理、コンテストに使う時間の捻出、コーディングスキルなど様々な課題があり、解決できなかった部分も多くありました。今回の反省を生かして、弊社諸先輩方のように自社の名前を高められるような成果を収められるよう今後も修行を続けていきます!
超長文のポエムでしたが、最後までお付き合いいただきありがとうございました。
-
岡田、正木、長谷川、田中 「統計値を用いたプライバシ保護擬似データ生成手法」 CSS2017
この疑似データ生成アルゴリズムを匿名化に利用すると、匿名化前後のヒストグラムが類似してかつ、属性間の共分散が類似する擬似データを生成することができます。
しかし、今回のコンテストで設定された有用性指標の閾値を下回ってしまいます。岡田らの疑似データ生成アルゴリズムを匿名化に利用した場合の有用性指標と有用性指標の閾値を以下の表に示します。 ↩