はじめに
本記事のコードは以下のnotebookに記載されています。
外部データなど不要ですので、とりあえずGANを動かしてみたいという方は是非触ってみてください。
https://colab.research.google.com/drive/1TQWMTNDbqLQ0dWo4-rFz1mbY80hLIQNo?usp=sharing
GANとは
GANはGenerative Adversarial Networkの略であり、敵対的生成ネットワークの邦訳が与えられています。
GANはディープラーニングを利用した生成モデルの一種であり、生成器と識別器という2つのネットワークを持ちます。
これら2つのネットワークが互いに競い合うように学習することが、Adversarial(敵対的)の由来となります。
GANは近年、実在しない高精度の画像を生成することに成功しており、非常に注目されている技術です。
加えてGANの本質は2つのネットワークが競い合うように学習する点にあるため、画像生成以外にも多様なタスクに応用が可能です
そこで今回はGANに対する理解を深める為、Pytorchを用いてMNISTのGANを実装しました。
以下が今回実装するGANの構造になります。
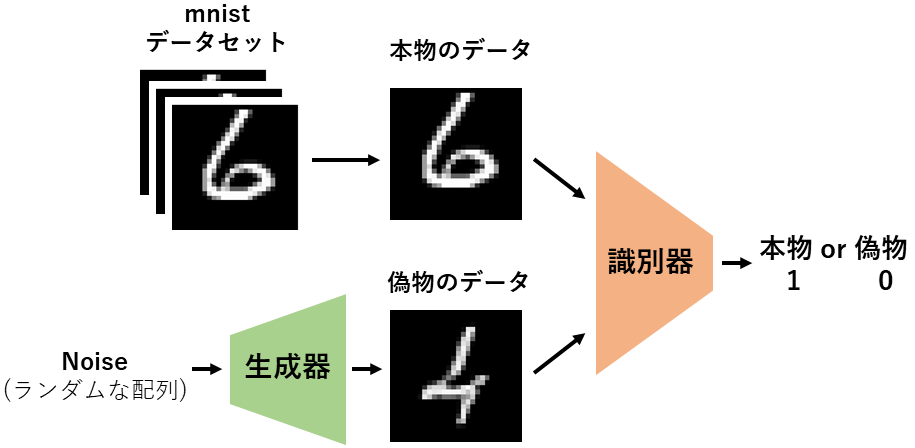
GANの学習について
1エポックにおけるGANの学習について説明します。
GANの学習は「識別器の学習」と「生成器の学習」のフェーズに分かれます。
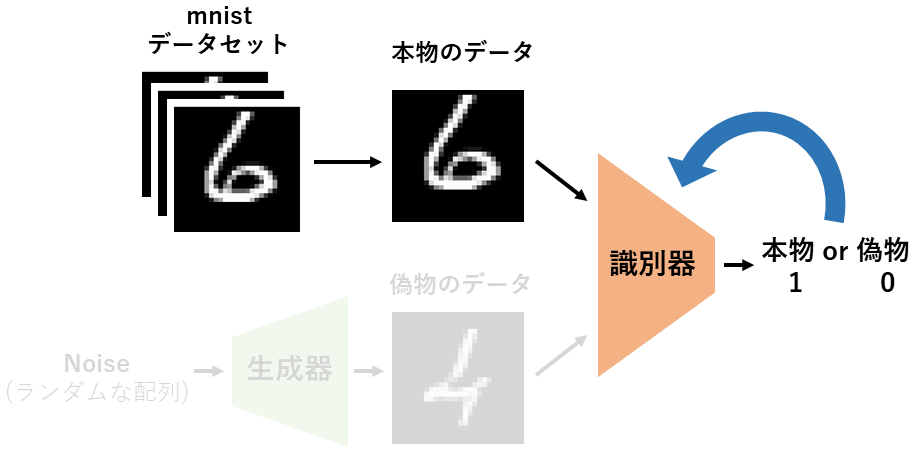
識別器の学習(1)
「識別器の学習」ではまずMNISTデータセットから本物のデータを識別器に流し込みます。
このデータを本物と判別できるように識別器が学習します。
下図の例では1(本物)と出力できるように1のラベルを使用して学習します。
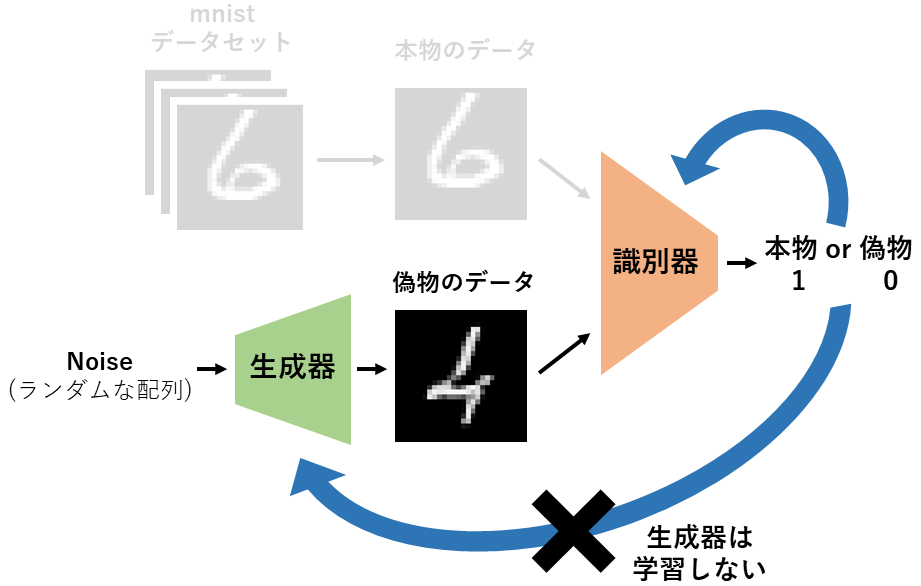
識別器の学習(2)
次も「識別器の学習」を行います。
今回は偽物のデータを偽物と判別できるように学習します。
下図の例では0(偽物)と出力できるよう0のラベルを使用してに学習します。
この時生成器は学習しないように、Tensor.detach()を使用して計算グラフを切り離します。
上述の説明からは(1)と(2)ごとに重みの更新を行うように読み取れますが、実際は(1)と(2)の損失を足し合わせて一度に学習を行います。
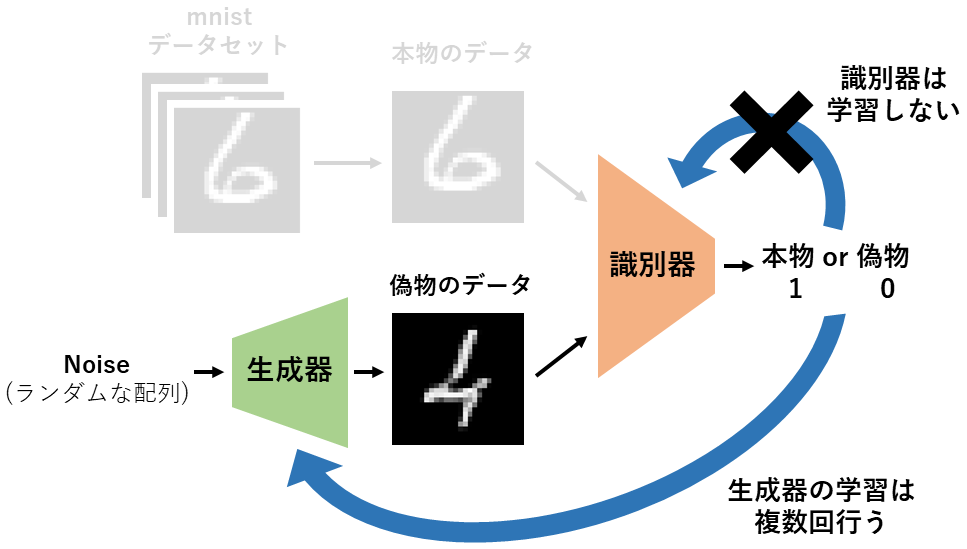
生成器の学習
最後に「生成器の学習」を行います。
ランダムな配列を生成し、生成器に流し込み偽物のデータを出力します。
下図の例ではこの偽物のデータを1(本物)と出力してもらえるように、1のラベルを使用して学習します。
この時、識別器は学習しません。
GANは識別器の学習が進みやすいため、生成器の学習を複数回繰り返してバランスを取ります。
データセット
みんな大好きMNISTを使用します。
MNISTは手書き数字(1~9)の画像とラベル(画像がどの数字であるか)がセットになったデータセットです。
環境
- Google Colaboratory Pro
コード
モジュールのimport
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
データセットの作成
pytorchのmnistデータセットを使用します。
BATCH_SIZE = 16
train_data = MNIST("./data",
train=True,
download=True,
transform=transforms.ToTensor())
train_loader = DataLoader(train_data,
batch_size=BATCH_SIZE,
shuffle=True)
print("train data size: ",len(train_data)) #train data size: 60000
print("train iteration number: ",len(train_data)//BATCH_SIZE) #train iteration number: 3750
データの内容は以下の通りです。
images, labels = next(iter(train_loader))
print("images_size:",images.size()) #images_size: torch.Size([16, 1, 28, 28])
print("label:",labels) #label: tensor([7, 3, 0, 3, 7, 2, 5, 3, 2, 0, 8, 7, 4, 9, 5, 7])
image_numpy = images.detach().numpy().copy()
plt.imshow(image_numpy[0,0,:,:], cmap='gray')
識別器と生成器を作成します。
class TwoConvBlock_2D(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size = 3, padding="same")
self.bn1 = nn.BatchNorm2d(out_channels)
self.rl = nn.LeakyReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size = 3, padding="same")
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.rl(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.rl(x)
return x
class Discriminator(nn.Module): #識別器
def __init__(self):
super().__init__()
self.conv1 = TwoConvBlock_2D(1,64)
self.conv2 = TwoConvBlock_2D(64, 128)
self.conv3 = TwoConvBlock_2D(128, 256)
self.maxpool_2D = nn.AvgPool2d(2, stride = 2)
self.l1 = nn.Linear(2304, 100)
self.l2 = nn.Linear(100, 1)
self.relu = nn.LeakyReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool_2D(x)
x = self.conv2(x)
x = self.maxpool_2D(x)
x = self.conv3(x)
x = self.maxpool_2D(x)
x = x.view(-1, 2304)
x = self.dropout(x)
x = self.l1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.l2(x)
x = torch.sigmoid(x)
return x
class Generator(nn.Module): #生成器
def __init__(self):
super().__init__()
self.TCB1 = TwoConvBlock_2D(1,64)
self.TCB2 = TwoConvBlock_2D(64,128)
self.TCB3 = TwoConvBlock_2D(128,256)
self.UC1 = nn.ConvTranspose2d(64, 64, kernel_size =2, stride = 2)
self.UC2 = nn.ConvTranspose2d(128, 128, kernel_size =2, stride = 2)
self.conv1 = nn.Conv2d(256, 1, kernel_size = 2, padding="same")
def forward(self, x):
x = self.TCB1(x)
x = self.UC1(x)
x = self.TCB2(x)
x = self.UC2(x)
x = self.TCB3(x)
x = self.conv1(x)
x = torch.sigmoid(x)
return x
学習を行います。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_D = Discriminator().to(device)
model_G = Generator().to(device)
one_labels = torch.ones(BATCH_SIZE).reshape(BATCH_SIZE, 1).to(device)
zero_labels = torch.zeros(BATCH_SIZE).reshape(BATCH_SIZE, 1).to(device)
criterion = nn.BCELoss()
optimizer_D = optim.Adam(model_D.parameters(), lr=0.00001) #GANの学習率は低いことが多いです
optimizer_G = optim.Adam(model_G.parameters(), lr=0.00001)
epoch_num = 30
print_coef = 10
G_train_ratio = 2 #1epoch当たり何回生成器の学習を行うか
train_length = len(train_data)
history = {"train_loss_D": [], "train_loss_G": []}
n = 0
for epoch in range(epoch_num):
train_loss_D = 0
train_loss_G = 0
model_D.train()
model_G.train()
for i, data in enumerate(train_loader):
#識別器の学習(1)
optimizer_D.zero_grad()
inputs = data[0].to(device)
outputs = model_D(inputs)
loss_real = criterion(outputs, one_labels) #本物のデータは1(本物)と判定してほしいので1のラベルを使用します
#識別器の学習(2)
noise = torch.randn((BATCH_SIZE, 1, 7, 7), dtype=torch.float32).to(device) #ランダム配列の生成
inputs_fake = model_G(noise) #偽物データの生成
outputs_fake = model_D(inputs_fake.detach()) #.detach()を使用して生成器が学習しないようにします
loss_fake = criterion(outputs_fake, zero_labels) #偽物のデータは0(偽物)と判定してほしいので0のラベルを使用します
loss_D = loss_real + loss_fake #識別器の学習(1)と(2)の損失を合算
loss_D.backward()
optimizer_D.step()
#生成器の学習
for _ in range(G_train_ratio):
optimizer_G.zero_grad()
noise = torch.randn((BATCH_SIZE, 1, 7, 7), dtype=torch.float32).to(device) #ランダム配列の生成
inputs_fake = model_G(noise)
outputs_fake = model_D(inputs_fake)
loss_G = criterion(outputs_fake, one_labels) #偽物のデータを1(本物)と判定する方向に学習したいので1のラベルを使用します
loss_G.backward()
optimizer_G.step()
#学習経過の保存
train_loss_D += loss_D.item()
train_loss_G += loss_G.item()
n += 1
history["train_loss_D"].append(loss_D.item())
history["train_loss_G"].append(loss_G.item())
if i % ((train_length//BATCH_SIZE)//print_coef) == (train_length//BATCH_SIZE)//print_coef - 1:
print(f"epoch:{epoch+1} index:{i+1} train_loss_D:{train_loss_D/n:.10f} train_loss_G:{train_loss_G/(n*BATCH_SIZE):.10f}")
n = 0
train_loss_D = 0
train_loss_G = 0
print("finish training")
学習経過をプロットします。
plt.figure()
plt.plot(history["train_loss_D"])
plt.xlabel('batch')
plt.ylabel('train_loss_D')
plt.figure()
plt.plot(history["train_loss_G"])
plt.xlabel('batch')
plt.ylabel('train_loss_G')
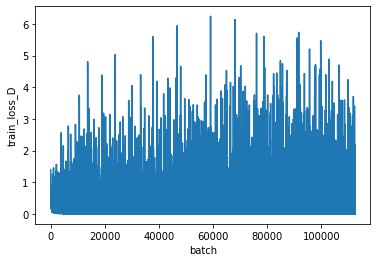
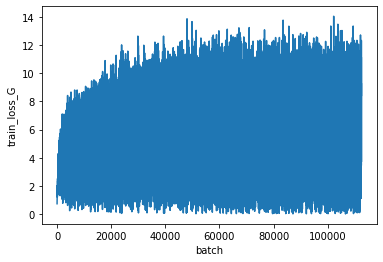
上が識別器、下が生成器の損失を表します。
GANの学習は損失が一方向に低下するのではなく、振動する特徴があります。
生成画像をプロットします。
model_G.to("cpu")
with torch.no_grad():
noise = torch.randn((BATCH_SIZE, 1, 7, 7), dtype=torch.float32)
syn_image = model(noise)
plt.figure()
fig, ax = plt.subplots(BATCH_SIZE, 1, figsize=(15,3))
for i in range(BATCH_SIZE):
ax[i,1].imshow(syn_image.detach().numpy().copy()[i,0,:,:], cmap='gray')
ax[i,1].axis("off")
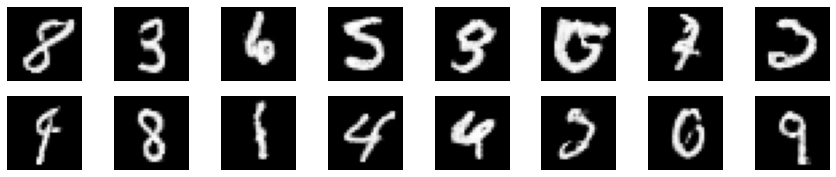
MNISTらしい画像が生成されていますが、何の数字かわからないものもあります。
epoch数の増加あるいは学習率の減衰を行うことで改善できるかもしれません。
また、本モデルでは特定の数字を狙って画像生成することはできませんが、
Conditional GANと呼ばれるモデルは特定の数字の画像を生成することが可能です。
こちらの記事も後日あげたいと思います。