はじめに
昔、Excel VBAやApache Strutsでフォームやロジックを組んでいた世代の皆さん、
いまやChatGPTやFaissといったAI関連のキーワードをよく耳にするのではないでしょうか。
本記事では、そんな最新技術を使ってエンジニア向けの“おみくじ診断”アプリを作る際に、
「どうやって回答内容から“意味”を取り出しているのか?」という仕組みを解説していきます。
さらに、記事の後半では、FastAPI + Faiss + o1-previewを連携させた具体的なコード例も示します。
「なぜ占い以上の説得力を生み出せるそう(に見えるのか)」といった理屈から、「どんなふうにコードを分割すればいいのか?」という実装レベルまで、ぜひ参考にしてみてください。
肝心のおみくじは、以下にあります。
https://omikuji.skillbridge.co.jp/
この記事では言及しませんが、アクセスカウンターや対応ブラウザなど、
おっさん世代(ジオシティー世代くらいの方が同年代です)の想いを沢山込めて、元旦と2日、正月からホリデープログラミングで作成しました。
1. アプリの概要と4つの質問
1-1. アプリ全体の流れ
-
1000問のエンジニアタイプを生成
- ChatGPT Proを使えば簡単
-
ユーザーがフォームに回答
- 今回は4つの質問(後述)で、フリーテキスト入力を受け付ける
-
テキストをEmbeddingしてベクトル化
- OpenAIのEmbeddingモデル(
text-embedding-3-large)で回答を数値化
- OpenAIのEmbeddingモデル(
-
Faissで上位K件の「アーキタイプ(エンジニアキャラ)」を検索
- 事前に用意した1000種類のアーキタイプと比較し、距離が近い順にTop K
-
Open AI API (o1-preview) へ渡して再解釈
- 「そのTop Kを、さらに5件に絞ってランキング&理由付けを面白く書いてね」と依頼
- ここで回答内容の具体的なキーワードとアーキタイプ特徴を関連づける
-
おみくじ(大吉・凶など)をランダムで混ぜて結果を表示
- 単に数値が近いだけでなく、「○○だから大吉です!」という言葉の説得力でユーザーを楽しませる
“アーキタイプ1000件” を ChatGPT Pro で生成
どうやって作ったか
ChatGPT Pro に対して、
カテゴリー A~L 各80件、M だけ40件で計1000件。
id, category, title, description(特徴とモットー) をJSONで出して
と依頼すると、すぐに以下のようなデータが整います。
[
{
"id": 1,
"category": "A",
"title": "ビッグオー信奉者",
"description": "特徴:定数倍の違いにも執着...\nモットー:「O(n^2)は甘え。」"
},
...
{
"id": 1000,
"category": "M",
"title": "なんでも興味津々トライアルマン",
"description": "特徴:使ったことない技術はとりあえず手を動かす...\nモットー:「好奇心こそ技術者の原動力。」"
}
]
昔ならCSVを手入力とかExcelマクロとかしていたと思うと、これは本当にラク。
これを .json に落として、Python のバッチスクリプトで DB に INSERT します。
4つの“汎用的な”質問
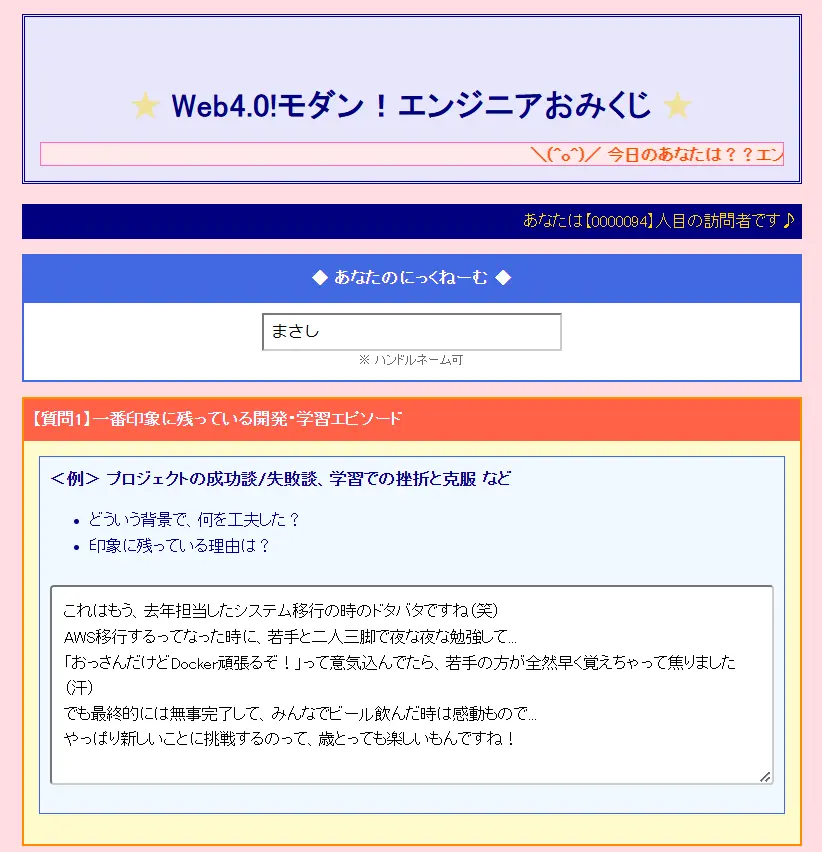
今回、ユーザーが入力するのは以下の4問です:
-
開発・学習エピソード
- 印象に残ったプロジェクトの成功談/失敗談、学習の挫折と克服など
- どんな背景があり、何を工夫したのか? どうして印象に残ったのか?
-
コミュニケーションスタイルが顕著に出た場面
- チーム開発や勉強会、新人サポートなどで「どんな行動」を取り、何を学んだか?
-
直近で興味がある技術・分野 or 身につけたいスキル
- AI/クラウド/データ分析/フロントエンドなど
- なぜ興味を持ち、どんなプロジェクトに活かしたいのか?
-
独自の仕事の進め方・モチベーション維持の工夫
- タスク管理や仕様変更、スケジュール調整、トラブル対応など
- 普段どんなふうにやる気を保ち、仕事を進めるのか?
「どれも一般的なQ&Aだし、無難な回答しか出てこないのでは?」と思うかもしれませんが、
実はこれら4つの切り口が、「"エンジニア個々人の“本質的な個性”」を浮き彫りにするカギになっています。
2. なぜ4つの質問から「意味」を取り出せるのか?
2-1. 多面的にエンジニア像を描く質問構成
- 開発・学習エピソード:成功/失敗体験や学習スタイルを見ることで、過去にどう行動してきたかを把握
- コミュニケーションスタイル:チームとどう連携し、どんなフィードバックを得たかで、他者との関係性や協調性を測る
- 興味のある技術:今後のキャリア志向や勉強意欲、最新トレンドへのアンテナの張り方が分かる
- 独自の仕事スタイル:タスク管理やモチベーション維持の方法、ストレス耐性や問題解決へのアプローチが出る
こうして行動面(過去)・コミュニケーション面・未来志向・自己管理の4軸を押さえるため、回答者ごとに顕著な違いが表れやすい構成になっています。
2-2. “一般的な質問”だからこそ、個性が際立つ
あえて汎用的なシナリオを聞くことで、回答者が「どのように語るか」という個性が大きく左右されます。
同じ「失敗談」でも、「失敗からどう学んだか」が人によって全然違う。
同じ「興味のある技術」でも、「何に興味を持ち、なぜか」が千差万別。
その差分こそが、回答者の本質的な指向や行動特性を示すヒントになるわけです。
3. ベクトル化 (Embeddings) が“占い”で終わらない理由
3-1. キーワードベースのリスク
もし昔ながらのキーワードマッチで「AI」「コミュニケーション」「モチベーション」といった単語を拾うだけなら、
「あなたはAIに興味あるんですね~」程度の占いチックな分析に留まりがち。
回答全体の“文脈”や“ニュアンス”を拾えないため、深い意味付けができません。
3-2. Embeddingsで文脈を高次元ベクトルとして扱う
OpenAIのEmbeddingモデル(例:text-embedding-3-large)を使うと、
回答文全体の意味を使用すると、テキスト全体の意味を数百から数千次元のベクトルにマッピングできます。
- 似たような文脈・ニュアンスの文章は距離が近い
- 単語が違っても「後輩をサポートしていた」「新人にドキュメントを作ってあげた」は、実質同じコミュニケーション特性を表す
こうして回答4つをまとめてEmbeddingすると、「どこに軸足があるエンジニアなのか」を大まかに把握できるわけです。
キーワード検索と違い、言葉の使い回しや細かな表現が違っても、文脈的には近い=ベクトル的にも近いと判定できるのが強み。
3-3. それでも数値だけでは説明にならない
ただし、ベクトル化は「距離が近い文章を見つける」ところまでは得意でも、「理由づけ」はしてくれません。
「なぜ距離が近いのか?」は数値の上では「ベクトル同士が似てるから」ですが、ユーザーにはピンときませんよね。
ここでGPTによる解釈が重要になります。
4. GPT(ChatGPT Pro)で“意味づけ”する
4-1. Faissで上位K件を絞る → GPTで再解釈
- ユーザー回答をEmbeddingし、Faiss検索で「似たアーキタイプ上位10」を得る
- GPTに「上位10のアーキタイプと回答文を見て、5つ選んで面白く解説して」と促す
- GPTは回答文中のキーワードや文脈を参照しながら、**「どのアーキタイプが、どの回答内容と似ているのか」**を言語化してくれる
4-2. 占いから“納得感”へ
- Faiss:単に「距離が小さいから近い」と返すだけ
-
GPT:ユーザー回答文とアーキタイプの特徴を突き合わせ、
「あなたは新人サポートのエピソードで『丁寧にドキュメントを整備する』と書いていますが、このアーキタイプも文書化を重視するので相性が良いです」
といった具体的な理由を付ける
これにより、ユーザーは「なるほど、確かに自分はそういう行動をとってきたから相性が良さそうだ」と納得できます。
ただ「似てます」と言われるだけではなく「具体的にどの回答のどの点が似ているか」を教えてくれるので、占い感が薄れるわけです。
5. 4つの質問×GPTが生む“リアリティ”
5-1. 質問1: 開発・学習エピソード
- ユーザーが語る成功談や失敗談の中にある「挑戦意欲」「リカバリー策」「学び方」をGPTが拾い、
アーキタイプ側の「スピード重視」「慎重派」「トライ&エラー型」などと結びつけることで、
「だからあなたは○○タイプなんですね」が説得力を伴う。
5-2. 質問2: コミュニケーションスタイル
- チーム開発での振る舞いや新人サポートの実体験を読み込ませれば、
「あなたの回答から見ると、リーダーシップを発揮して周囲を巻き込むタイプ」
などのラベルづけが自然にできる。 - GPTは回答文から具体例を引用しつつ「先輩の助けを丁寧に受け取った」や「自ら勉強会を開いた」などのフレーズを活用し、
「コミュニケーション重視なら××のアーキタイプがぴったり」と説明してくれる。
5-3. 質問3: 興味がある技術・分野
- たとえばユーザーが**「AIを駆使して効率化したい」**という回答をしていると、GPTは「AI系のアーキタイプ」を距離や内容から選び、
「あなたはプロジェクトでデータ分析に関心を持っているようですから、このAIアーキタイプと相性がいいですね」と提案する。 - 逆にクラウドインフラがメインなら、「AWSやGCPに強みを持つアーキタイプ」と結びつく流れが自然に生まれるという仕組みです。
5-4. 質問4: 独自の仕事スタイル・モチベーション維持
- スケジュール管理をこまめにするか、アドリブ的にやるか、障害対応で何を優先するか…
- GPTは回答文の中から「タスク分割が得意」「アジャイル思考」「突然のトラブルも楽しめるタイプ」などの要素を拾って、
アーキタイプの「柔軟性重視」「堅実性重視」などの特徴と紐づけて理由づけを行う。
6. 信憑性が高い診断ができる理由
-
ベクトル検索 (Faiss)
- 回答の“文脈”を高次元ベクトルで扱い、同義語や類似エピソードを含めて「近い」ものを正確にピックアップ
-
GPTの言語モデル
- 回答文を直接参照し、具体的なフレーズとアーキタイプの特徴を結びつけて解説
-
4つの質問が多面的である
- 過去の成功/失敗・コミュニケーション・技術志向・仕事スタイルを聞くことで、回答者の個性を複数の軸から捉える
- GPTがそれらを総合しやすい下地ができている
その結果、「なんとなく距離が近いね」という曖昧な占いではなく、「あなたのエピソードのここが、このタイプの特徴とマッチするから」と根拠を示せる。
ユーザーは「ああ、確かにそんな行動をとってたな」と納得しやすいため、信憑性の高い診断に感じられるわけです。
7. 仕組みを実装するためのコード例
ここからは、実際のコード構成を詳しめに紹介します。
7-1. ディレクトリ構成(サンプル)
omikuji_app/
├─ main.py
├─ database.py
├─ faiss_utils.py
├─ openai_utils.py
├─ routers/
│ └─ diagnosis.py
├─ batch/
│ ├─ insert_archetypes.py
│ └─ build_faiss_index.py
├─ templates/
│ ├─ result.html
│ └─ diagnosis_form.html
└─ requirements.txt
-
main.py: FastAPIアプリのエントリポイント -
database.py: DB接続&SQLAlchemyモデル定義(例:Diagnosisテーブルなど) -
faiss_utils.py: Faiss関連のヘルパー関数(インデックス検索など) -
openai_utils.py: OpenAI EmbeddingsやGPT呼び出し&おみくじ生成など -
routers/diagnosis.py: フォーム入力を受け取り、Faiss検索→GPT解説→結果表示まで -
batch/: コマンドライン実行のスクリプト(アーキタイプ初期登録やFaissインデックス構築) -
templates/: Jinja2テンプレート(result.html,diagnosis_form.htmlなど)
7-2. main.py - FastAPIエントリポイント
# main.py
from fastapi import FastAPI
from routers import diagnosis # ルーターの読み込み
app = FastAPI(
title="Engineer Omikuji App",
description="ChatGPT Pro × Faiss × FastAPIで作るエンジニア診断アプリ",
version="1.0.0",
)
# diagnosisルーターを登録
app.include_router(diagnosis.router, prefix="", tags=["Diagnosis"])
# ルート(トップページなど)簡易的に
@app.get("/")
def read_root():
return {"message": "Welcome to Engineer Omikuji App!"}
7-3. database.py - DB接続・テーブル定義
# database.py
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
DATABASE_URL = "postgresql://skillbridgedb:password@localhost:5432/freelance_engineer"
engine = create_engine(DATABASE_URL, echo=False)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
# ▼ 診断テーブルの例
class Diagnosis(Base):
__tablename__ = "diagnosis"
id = Column(Integer, primary_key=True, index=True)
user_answer = Column(Text)
gpt_comment = Column(Text)
omikuji = Column(String(50))
created_at = Column(DateTime, default=datetime.utcnow)
def init_db():
Base.metadata.create_all(bind=engine)
# セッションを取得するためのDepends
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
7-4. faiss_utils.py - Faissインデックス検索
# faiss_utils.py
import faiss
import numpy as np
from openai_utils import embed_text
# グローバルでインデックスを保持する例
index = None
archetype_meta = []
def load_faiss_index(index_path: str, archetypes: list):
global index, archetype_meta
index = faiss.read_index(index_path)
archetype_meta = archetypes # [{"id":..., "title":..., "description":...}, ...]
def search_top_archetypes(db, user_text: str, top_k=10):
"""ユーザー回答をEmbedding→Faiss検索→Top K返す"""
if not index:
raise ValueError("Faiss index not loaded.")
# 1) Embedding
user_vec = embed_text(user_text)
user_vec = np.array([user_vec], dtype='float32')
# 2) Faiss検索
D, I = index.search(user_vec, top_k)
results = []
for rank, idx in enumerate(I[0]):
distance = float(D[0][rank])
meta = archetype_meta[idx]
results.append({
"faiss_idx": idx,
"distance": distance,
"id": meta["id"],
"title": meta["title"],
"description": meta["description"],
})
return results
7-5. openai_utils.py - GPT呼び出し&Embedding・おみくじ
# openai_utils.py
import openai
import random
openai.api_key = "YOUR_OPENAI_API_KEY"
def embed_text(text: str):
"""OpenAI Embeddingsを使ってベクトル化"""
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=text
)
return response["data"][0]["embedding"]
def gpt_archetype_judgement(user_text: str, top_archetypes: list) -> str:
"""Faissで得た上位アーキタイプをGPTに投げて再解釈させる"""
archetype_info = "\n".join([
f"ID: {a['id']}, 距離: {a['distance']:.4f}, タイトル: {a['title']}\n説明: {a['description']}"
for a in top_archetypes
])
prompt = f"""
あなたはエンジニア向けの診断マシンです。
以下のユーザー回答と候補アーキタイプ情報をもとに、
上位5件をランキングし、なぜそのユーザーに合うのかを
具体的なエピソードを引用するように面白く解説してください。
[ユーザー回答]
{user_text}
[候補アーキタイプ (Top 10)]
{archetype_info}
必ずIDとタイトルを含めてランキングしてください。
距離が小さいほど似ていますが、回答の内容と紐付けた理由づけを重視してください。
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response["choices"][0]["message"]["content"]
def generate_omikuji():
"""大吉や凶などをランダムに選ぶ簡易実装"""
candidates = [
("大吉", "🎉"),
("中吉", "😄"),
("小吉", "😊"),
("末吉", "🤔"),
("凶", "😱"),
]
omikuji, emoji = random.choice(candidates)
return f"{omikuji} {emoji}"
7-6. routers/diagnosis.py - メインの診断フロー
# routers/diagnosis.py
from fastapi import APIRouter, Request, Depends, Form
from sqlalchemy.orm import Session
from database import get_db, Diagnosis
from faiss_utils import search_top_archetypes
from openai_utils import gpt_archetype_judgement, generate_omikuji
from fastapi.templating import Jinja2Templates
import datetime
router = APIRouter()
templates = Jinja2Templates(directory="templates")
@router.get("/diagnosis")
def show_diagnosis_form(request: Request):
"""診断フォーム表示(GET)"""
return templates.TemplateResponse("diagnosis_form.html", {"request": request})
@router.post("/diagnosis")
def do_diagnosis(
request: Request,
db: Session = Depends(get_db),
# 4つの質問をFormで受け取る例
q1: str = Form(...),
q2: str = Form(...),
q3: str = Form(...),
q4: str = Form(...)
):
"""ユーザー回答 → Faiss検索 → GPT解説 → おみくじ → 結果表示"""
# (1) ユーザー回答をまとめる
user_text = f"【Q1】{q1}\n【Q2】{q2}\n【Q3】{q3}\n【Q4】{q4}"
# (2) Faiss で上位10件を検索
top_archetypes = search_top_archetypes(db, user_text, top_k=10)
# (3) GPT-4でさらに5つを選び、面白く解説
gpt_judgement = gpt_archetype_judgement(user_text, top_archetypes)
# (4) おみくじ結果
omikuji_result = generate_omikuji()
# (5) DBへ保存
diag = Diagnosis(
user_answer=user_text,
gpt_comment=gpt_judgement,
omikuji=omikuji_result,
created_at=datetime.datetime.utcnow()
)
db.add(diag)
db.commit()
# (6) 結果画面
return templates.TemplateResponse("result.html", {
"request": request,
"gpt_comment": gpt_judgement,
"omikuji": omikuji_result
})
7-7. バッチスクリプトの例
(1) insert_archetypes.py: GPTに大量生成させたアーキタイプをDBに取り込む
# batch/insert_archetypes.py
import csv
from database import SessionLocal, Base, engine
# from models import Archetype # アーキタイプモデルを定義してある想定
def insert_archetypes(csv_file: str):
db = SessionLocal()
with open(csv_file, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
# rowにはtitle, description, category等が入っている想定
arch = Archetype(
title=row["title"],
description=row["description"],
category=row["category"]
)
db.add(arch)
db.commit()
db.close()
if __name__ == "__main__":
Base.metadata.create_all(engine)
insert_archetypes("archetypes.csv")
(2) build_faiss_index.py: DBデータ→Embedding→Faissインデックス
# batch/build_faiss_index.py
import faiss
import numpy as np
from database import SessionLocal
from openai_utils import embed_text
# from models import Archetype
def build_index(output_index_path: str):
db = SessionLocal()
archetypes = db.query(Archetype).all()
vectors = []
meta_list = []
for arch in archetypes:
vec = embed_text(f"{arch.title} {arch.description}")
vectors.append(vec)
meta_list.append({
"id": arch.id,
"title": arch.title,
"description": arch.description
})
vectors_np = np.array(vectors, dtype='float32')
dimension = vectors_np.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(vectors_np)
faiss.write_index(index, output_index_path)
# メタ情報をJSONに保存等(省略)
db.close()
if __name__ == "__main__":
build_index("archetypes.index")
7-8. テンプレート例: templates/result.html
<!-- templates/result.html -->
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>診断結果 - エンジニアおみくじ</title>
</head>
<body>
<h1>診断結果</h1>
<div>
<p>GPT解説:</p>
<pre>{{ gpt_comment | safe }}</pre>
</div>
<div>
<p>おみくじ結果:{{ omikuji }}</p>
</div>
<p><a href="/diagnosis">もう一度診断する</a></p>
</body>
</html>
- GPTのコメントはMarkdownになるので、クライアントサイドでMarkdownに対応します。今回はプラグインを使うには大げさなので、簡単なjsを書きました。
- 「おみくじ結果」はただのテキストでも十分ですが、好きなデザインを加えるとエンタメ要素が増します。
8. まとめ
ここまで、
- 4つの汎用的な質問から「なぜ意味が取り出せるのか」
- Embeddings(ベクトル化)とGPTによる“意味づけ”の流れ
- 「占い」では終わらず根拠ある診断になる理由
- 具体的なファイル構成&サンプルコードによる実装例
を一通りご紹介しました。
ベクトル検索(Faiss)だけでは抽象的になりがちですが、GPTで「回答内容とアーキタイプの対応関係」**を自然言語で説明させることで、本当に自分の回答を読み取っていると感じられる診断に仕上がります。
昔はExcel VBAで頑張って設問を組み合わせで作ったり、Apache Strutsで画面&ロジックを実装し、更に頑張ってユーザーに入力してもらった情報を解析する(文字の一致数で類似度作ってみたり...)なんてやっていましたが、
いまやEmbeddingsとGPTを組み合わせることで、データに基づくAI診断+ストーリーテリングが簡単に作れる時代。
「ただの占い」にとどまらず、回答内容に即した説得力を持った仕組みを作ってみたい方は、ぜひ参考にしてみてください。
おわりに
以上、4つの質問から“意味”をしっかり取り出せる理由と、それを支えるEmbeddings + GPT + Faiss + FastAPIのサンプルコードをお伝えしました。
「占い以上の精度」「納得感のあるストーリー」を両立させるには、
- ベクトル化で文脈を拾い
- GPTで理由づけを言語化し
- さらにおみくじで遊び心を加える
という流れがポイントです。
興味のある方は、ぜひ自分なりのアーキタイプデータを作ってみたり、データベース設計やテンプレートのUIを工夫したりしてみてください。
エンジニアとしては、こうした「遊び心×AI技術」のアプリを作るのはとても面白い体験になるはずです。
作るのが面倒な方はおみくじやってみてね!
長くなってしまいましたので、説明を省略しましたが、GPT APIと心理学を組み合わせた性格特性を検出する「詳細診断」も使えます!
これはまた別途記事にしようと思います!
https://omikuji.skillbridge.co.jp/