はじめに
かれこれ1年以上前のことになりますが、今の開発組織でデータベースに接続するJunitを使ったIntegrationTest1 を開発者のPCとCIで実行できる仕組みを作りました。
- トライしたきっかけと想い
- 仕組みの設計・導入をする時に気を付けたこと
- 具体的な実現方法
- トライしてみて感じたこと
を記載します。
トライしたきっかけと想い
私が保守開発を担当しているプロダクトは20年近く運用されているWebアプリケーションです。(サーバーサイドはJava)
単体テストの仕組みと文化が無いまま長期間運用されており、大半のコードがレガシーコードという状態でした。
一部テストが書かれている箇所もありましたが、CIでの実行の仕組みはなく腐ってしまっているものも多い状態でした。
そこに @autotaker1984 さんがCIでの単体テスト実行の仕組みを作ってくれて、単体テストを書くべきというマインドの布教も行ってくれました。(その時の取り組みはこちらの記事をご参照ください)
この取り組みの後、私はレガシーコードに単体テストを書くことに夢中でした。
カバレッジを100%にしたクラスをリファクタリングする気持ちよさにエンジニアとしての悦びを感じていました。
しかしCIでの実行にはデータベースに接続するテストは含まれておらず、Dao層のクラスにテストを書いても継続的な実行はされない状態でした。
Dao層のクラスはできる限りシンプルな実装にするのが望ましいと考えていますが、データの絞り込み処理など仕様が集約される重要なロジックも存在します。
そのためDao層のクラスにもテストを積み上げていける状態を作りたい、と思ったことがきっかけです。
仕組みの設計・導入をする時に気を付けたこと
データベースに接続しないテストとするテストを区別できる仕組みにする
- (当然ながら)データベースに接続するテストはデータベースの準備が必要
- データベースに接続するテストは接続しないテストよりも実行に時間がかかる
- 将来的にテストの実行数が増えて並列実行をする際に、データベースに接続するテストは並列数分のデータベースを用意する必要がある2
上記のような違いがあるため、データベースに接続しないテストとするテストは区別できるような仕組みにしました。
テストクラスとテストデータの距離を近く保つ仕組みにする
データベースに接続するテストはデータベースの状態に依存したテストとなります。
テストを実行する前にあらかじめ必要なデータを投入しておくこともできますが、そうするとテストクラスとテストデータが分離された状態になります。
分離された状態になるとテストの数が増えた際に、どのデータがどのテストの実行に必要なのかを管理することが難しくなっていきます。
そのため出荷データとして存在するテーブル定義やデータ以外の必要なデータはテストクラスのセットアップで投入する仕組みとしました。
実装者にテストのサイジングを意識してもらう
テストの実行をうまく行うためには、小さなサイズのテストの数を多くすることが重要です。
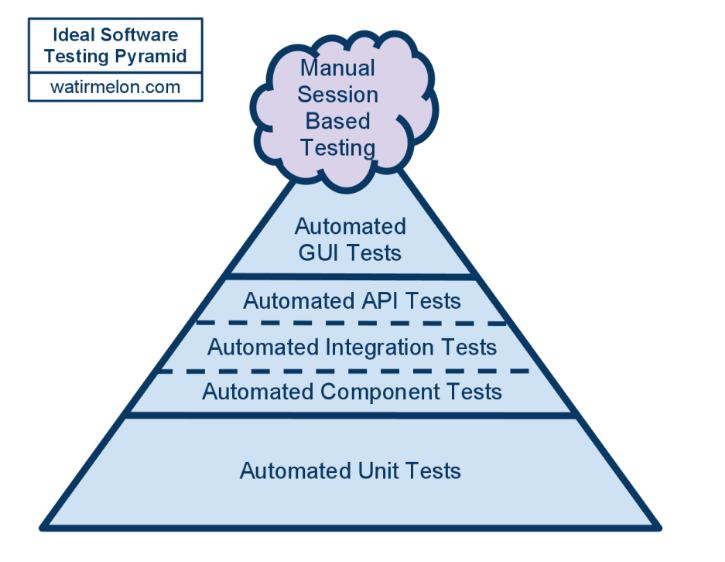
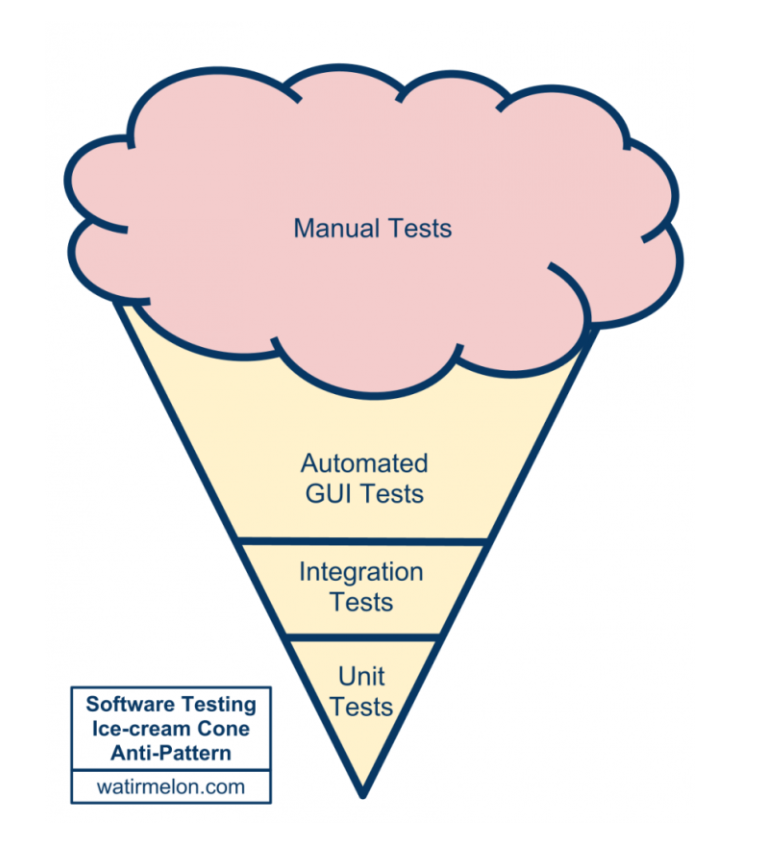
参考
The Software Testing Ice Cream Cone
テストのサイズが大きくなると実行コストが大きくなり、安定性が下がります。
また単体テストを書ける状態にすることによる内部品質の向上の効果も得られなくなります。
データベースに接続するということはそれだけでサイズの大きなテストになります。
そのため今回用意した仕組みはE2Eなどのたくさんのクラスを結合するテストでの利用はサポートしないことを明示し、(クラスの結合の数としては)小さなテストを書くために利用してもらうようにしました。
具体的な実現方法
取り組み前にあった仕組み
テスト作成のための仕組み
- JUnit5、Mockitoを利用してテストを書くことができる状態
CIのテスト実行の仕組み
- pre-mergeのpipelineで修正されたクラスのテスティングペアのテストクラスのUnitTestを実行する仕組み(Gradle + GitLabCI)
- 日次ですべてのUnitTestを実行する仕組み
開発用データベースの仕組み
これらを活用しながら新しい仕組みを作っていきました。
開発者のPCで実行する仕組み
開発者のPCでは評価環境のデータをコピーしたDockerImageを動かせる状態でした。
そのため以下の対応を行って、Dockerで動作させてデータベースに接続しテストを行えるようにしました。
- IntegrationTestコード専用のフォルダの準備
- テスト時に利用するConnectionやDataSourceを作成するUtilityクラスの作成5
- データベースに接続するテスト専用のアノテーションの作成6
- データの投入はDBUnitを利用しcsvファイルで用意したデータをsetUpで投入できるようにする
- お手本にしてもらえるようなサンプルのテストを作成して他の開発者に共有
CIで実行する仕組み
- IntegrationTestコード専用のフォルダ内にある専用のアノテーションがついたテストを実行するGradle Taskの作成
- 作成したGradle Taskをpipelineで実行する
Taskを実行する前に- Servicesで評価環境のDockerImageを起動する
- shellでConnectionの接続先をServicesのhost名に書き換える
- 修正差分に限定したテスト実行は既存の仕組みを踏襲
GitLabCI,Gradle,DockerなどCIの作成に必要な知識がかなり不足していたため、
@autotaker1984 さんにはたくさん助けていただきました。
ありがとうございます!
トライしてみて感じたこと
- CIにしっかり手を入れたのが初めてで、新しい仕組みを知れて楽しかった
- 自分が作った仕組みを開発者が使ってくれる、喜んでくれる幸せを感じた
- 自分がテストを書けるコードが増えて、カバレッジを上げられて気持ちが良い
昨年12月27日に @t_wada さんと一緒に実施した社内のワークショップでも、このデータベースに接続するテストを題材に使ってもらいました。
当日の様子は以下をご参照ください。
@flyaway さんが書いたワークショップ制作のポイントをまとめた記事
おわり。
追記
この後しばらく運用してみての反省記事を書きました。
この時点で考慮が足りていなかった点について書いています。
もしよろしければこちらもご覧ください。
-
ここでのIntegrationTestは複数のクラスを結合したテストではなく、クラス単体のテストをデータベースに接続するという意味での結合としてIntegrationTestと記載しています。 ↩
-
残念ながらまだ並列実行が必要になるほどのテストケースは作成されていませんが、同一のテーブルを利用するテストが同時に実行されると失敗する可能性があるため、将来的にそういったことも考える必要があると考えていました。 ↩
-
担当プロダクトは複雑な業務システムです。
打鍵テストを実行するためには多くの設定やデータを作成する必要があります。
そのためスムーズに評価を行えるように、あらかじめよく使われるデータが投入された評価環境を用意しています。
また評価をする際に作成されたデータがゴミとして残らないように、テストが終わった際にデータをクリーンアップする運用となっています。 ↩ -
評価環境のデータを元にDockerImageを作成しており、開発者が必要な時に自分のPCですぐに動かせるようになっています。 ↩
-
デフォルトではlocalhostに接続するような内容の設定ファイルを作成し、そこで指定されたhostに接続する実装としました。 ↩
-
ローカルでの実行時に関しては
@Testアノテーションで問題ありませんでしたがデータベースに接続するテストを判別し、CIで実行する際に分けるため専用のアノテーションを作成して使ってもらうようにしました。 ↩