問題
| 伝票番号 | 決済日 |
|---|---|
| 1 | H01/09/30 |
| 2 | H31/09/30 |
| 3 | R01/09/30 |
| 4 | R20/09/30 |
| ・ | |
| ・ | |
| ・ | |
| と何万件も続くデータがあります。 | |
| この日付列の中にあるデータ、実は日付型ではなく、全部 文字型 です。 | |
| 当然、このままだと、日付での集計や抽出はできません。 |
そこで、文字型から日付型にしなければならないのですが、何万件もループを回すと遅くなってしまいます。ループを使わず、高速に置換できる方法は何かあるでしょうか?
初期データ.py
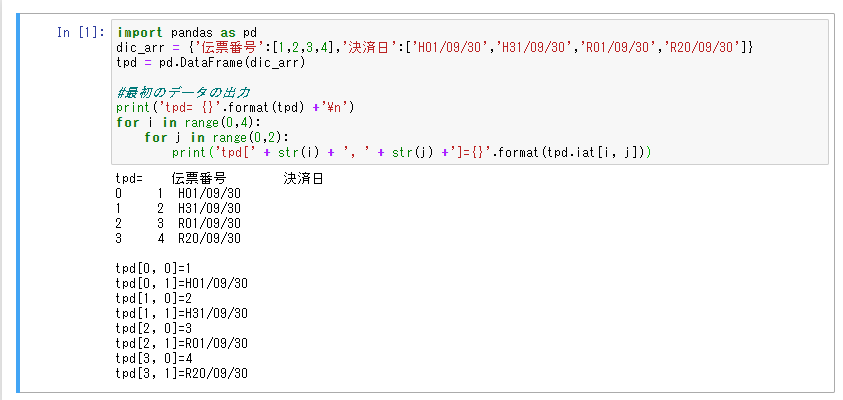
import pandas as pd
dic_arr = {'伝票番号':[1,2,3,4],'決済日':['H01/09/30','H31/09/30','R01/09/30','R20/09/30']}
tpd = pd.DataFrame(dic_arr)
# 最初のデータはこんな感じ
print('tpd= {}'.format(tpd) +'\n')
for i in range(0,4):
for j in range(0,2):
print('tpd[' + str(i) + ', ' + str(j) +']={}'.format(tpd.iat[i, j]))
mapを使った例解
map関数でデータ型を一気に塗り替える.py
import pandas as pd
from datetime import datetime
# 文字列になっている日付を、日付型に変換する関数
def convate(hiduke_text):
# デリミタ(/)で分ける
params = hiduke_text.split('/')
year = 0
if params[0][0] == 'S':
year += 1925
year += int(params[0][1:3])
elif params[0][0] == 'H':
year += 1988
year += int(params[0][1:3])
return datetime(year,int(params[1]),int(params[2]))
elif params[0][0] == 'R':
year += 2018
year += int(params[0][1:3])
return datetime(year,int(params[1]),int(params[2]))
else:
return hiduke_text
dic_arr = {'伝票番号':[1,2,3,4],'決済日':['H01/09/30','H31/09/30','R01/09/30','R20/09/30']}
print('dic_arr= {}'.format(dic_arr))
# ここでワン・クッション入れないと日付型として出てくれなかったため、冗長ながらlistを噛ませました。
tpd = pd.DataFrame(dic_arr)
iterable = map(convate, tpd['決済日'])
tpd['決済日'] = list(iterable)
# 最終出力結果
print('tpd= {}'.format(tpd) +'\n')
for i in range(0,4):
for j in range(0,2):
print('tpd[' + str(i) + ', ' + str(j) +']={}'.format(tpd.iat[i, j]))
実行結果はこうなりました。

自分はこのように答えを出しましたが、もっといいやり方はあるのだろうなと予測しています。
もし、もっといいやり方、スマートな解法がありましたら、ちょっと教えていただけましたら幸いに思います。
(というか、実際この問題に直面したから、今必死に答えを出したわけでして・・・)