【追記:2019/9/17】
記事で誤りがあった部分を修正いたしました。
またサンプルも正しいものに修正しておりますので、是非ご確認ください。
【追記:2019/9/10】
コメントでもご指摘を頂いておりますが、一部誤った内容が含まれております。
すぐに修正に取り掛かりますが、内容の修正まで今しばらくお待ち頂けますようお願いいたします。🙇♂️
また、今回多くの方に誤った内容をお伝えしてしまったこと、深くお詫び致します。
(多くのいいねを頂いており、ストックに登録して頂いている方もいらっしゃると思いますので、非公開にせず修正又は内容の削除で対応致します。)
先日インターンでソシャゲ用のAPIを作った時に、サーバーサイド未経験ながらGolang&クリーンアーキテクチャ(的な)のAPIを構築しました。
特にインターンで用意されていた内容というわけではなく、個人の課題としてクリーンアーキテクチャに取り組んだのですが、勉強時間含めて**「4日」**でAPIに導入することができました🎉
この記事では、クリーンアーキテクチャの解説と、今回僕がGolang×クリーンアーキテクチャの学習で詰まった部分・理解しづらかった部分を書いていこうと思います。
- クリーンアーキテクチャをちゃんと実装したことがない
- クリーンアーキテクチャの概念(丸い図)は理解できるけど、どう実装に落とし込めばいいの?
- DIP(依存関係逆転の原則)?何それおいしいの?😇
という方はぜひ読んでみてください🙌
記事を読む前に(追記)
この記事の前提として、**「クリーンアーキテクチャに完全に則ったアプリケーションは構築できない」**ことをまずお話ししておきます。
クリーンアーキテクチャは、外→内への単方向の依存関係を常に保つという依存性ルールの元、「アプリケーションが外部エージェント(DBやFW)に依存しない」ということが成立するわけですが、実際のところ、真に外部エージェントに依存しないような依存関係を構築することは不可能です。
必ず外部エージェントとアプリを繋ぐ中継役(Interface層)がアプリと外部エージェントの両方を知っている必要があります。
これがクリーンアーキテクチャにおける「矛盾」です。
ちなみにこれを解決(解消?)する方法として、「DIP:依存性逆転の原則」で依存関係を逆転させ、直接的な依存関係を保たないようにするという方法が用いられますが、Interface層に関してはあくまでも「見かけ上直接依存してないだけ」であり、外部エージェントがどういう動作をしてくれるかを知った上で内部で使える形式に変換するので、実質依存することになります。
詳しくはこちらの記事で提唱されております。
鵜呑みにしないで! —— 書籍『クリーンアーキテクチャ』所感 ≪null 篇≫
なので実際には、クリーンアーキテクチャのサンプルなどには、真にクリーンアーキテクチャとして正しいものはないということを是非ご留意頂ければと思います。(僕も指摘を頂いて知りました...)
またこれからクリーンアーキテクチャを学ばれる方も、「アーキテクチャはあくまでも保守性の高いアプリケーションを構築することが目的であり、クリーンアーキテクチャはその中の一案に過ぎない(アプリ作りでクリーンアーキテクチャの実践が目的になってはいけない)」ということを踏まえて学んで頂けたら嬉しいです。
(もし誤っている部分等ありましたらコメントにてご指摘いただけると嬉しいです!)
クリーンアーキテクチャを導入した理由
今回僕はインターンで個人的にクリーンアーキテクチャを導入した理由としては、
- APIの全体的な設計を理解できる
- 後の機能追加・拡張がしやすくなる
- DBの変更やフレームワークの導入が楽になる
の3つが大きな採用理由です。
(後にクリーンアーキテクチャのメリットと併せて詳しく解説します!)
今回のインターンはソシャゲ用のAPIの基本機能を実装した後、各自課題を設定してAPIを拡張していくというもので、僕は基本機能の実装が完了した後、第一に上記の理由からクリーンアーキテクチャの導入を行いました。
結果的にはこれが功を奏し、DBにORMapperを導入した時にGoファイルを1つだけ変更するだけで済んでしまったので、クリーンアーキテクチャの良さを身に染みて感じることができました。
導入前のスキルセット
タイトルの通り僕自身サーバーサイドの実務経験は全くなく、個人の開発でもiOSをメインに開発していたので、きちんとサーバーサイドを実装したことがありませんでした。
一応過去にRubyで簡単なWebアプリを作ったことはありましたが、その時に身についたはずのバックエンドの知識は遥か彼方へ消えてしまっていました(遠い目)
- Swift
- Javascript
- HTML/CSS
- Python
- (Go)
Pythonに関しては競プロで使用していて、Goに関してはbitflyerのAPIを叩いてレート表示する程度の簡単なAPIを作った程度です(スキルと呼んでいいのか?)
ただ、インターンが開始してから事前学習と自己学習のお陰でメキメキとサーバーサイドの知識が身についていたので、クリーンアーキテクチャを実装する頃には、GitHubに転がっていたGo×クリーンアーキテクチャのサンプルAPIを読み解けるほどになっていました。
学習方法とかかった時間
学習方法
Goでクリーンアーキテクチャを実装するために取った学習方法ですが、やったことは2つだけです。(未学習の方が最速で理解するならおそらくコレがベストだと思います)
- GitHubでサンプルアプリをクローンして、Qiitaやブログの記事を読みながらコードを読み解く
- コメントをつけながらサンプルアプリを1から再現する
2つだけですがかなり効力がありました。
参考にした記事とサンプルはこちら。
こちら記事とサンプルがセットになってます。少し古いですが、一番分かりやすかったです!(他にも参考にした記事があるので、後ほど紹介します)
使ったことがない技術やパターンを勉強する時は、記事やサンプルアプリを手当たり次第読んだりクローンしたりするだけで終わりがちですが...
仕組みを理解してない内からたくさん記事やコードを読むだけでは実装に落とし込むまでに到達できない気がしています。(僕自身ずっとそういう浅い勉強をやっていたことに今回ようやく気付きました)
また、「Go クリーンアーキテクチャ」で調べて出てくるサンプルアプリは人によって細かい部分が違っているので、**「まずは1つ良さげなサンプルアプリのコードを、記事を参考にしながら徹底的に理解しつつ、サンプルを再現すること」**が近道になると思います。
かかった時間
かかった時間はタイトルでは4日と書いていますが、勉強開始から実装完了までは60時間~65時間ほどでした。
平日15時間×2日+土日30時間=約60時間ですね。デスマ臭がする
クリーンアーキテクチャの概念
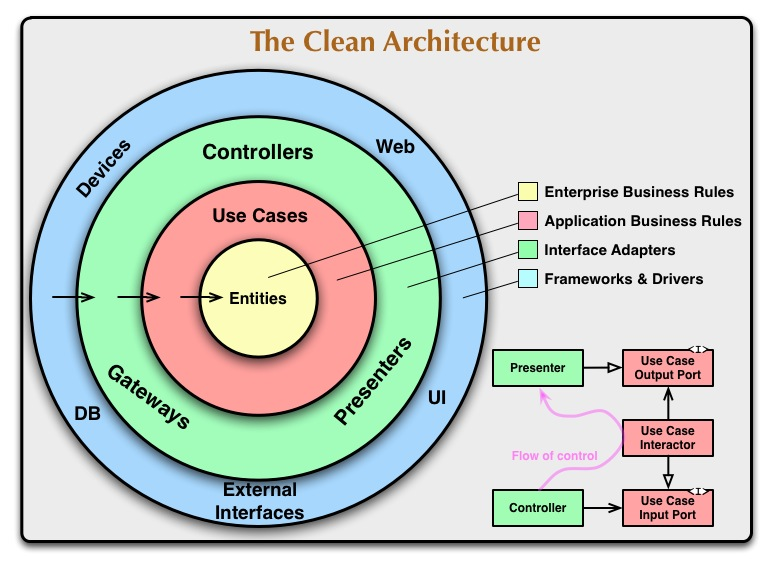
引用:https://blog.tai2.net/the_clean_architecture.html
さて、それでは早速ですがクリーンアーキテクチャの概念を解説していこうと思います。
クリーンアーキテクチャとは、ソフトウェアを「4つの層」に分離し、各層における依存関係を「外→内」への一方向に限定することで、外部のフレームワークやUI、DBや通信プロトコル等からアプリケーションを独立させることができるアーキテクチャパターンです。
DBやUI、フレームワークなどを一番外側の「Frameworks&Drivers層」に置くことで、仮にそれらに変更を加えることになっても、内部のビジネスルールは一切影響を受けることがありません。
↓↓こちら英語の記事ですが、クリーンアーキテクチャの仕組みについて詳しく解説されていますので、是非読んでみてください。
詳しくは各層の説明で解説していきます。
4層の役割
Entities
アプリケーションで必要なデータ構造・メソッドを持つオブジェクトをこのEntities層の中で定義します。
プロジェクトレベルの「高レベル」なビジネスロジックはこの層でカプセル化され、Usecaseでのデータの流れに組み込まれます。
今回紹介する「ユーザー作成・情報取得を行うAPI」のサンプルアプリでいうと、「User」モデルをStructで定義するのがこの層になります。
Usecases
Entitiesで定義しているデータ構造・メソッドを用いた「データの流れ」をこのUsecase層で組み立てます。
この層で処理を行った後、Interfaceへ処理結果が渡されます。
今回のサンプルでいうところの、「Interfaceから受け取ったユーザーネームとパスワードと併せてIDとTokenをUUIDで生成し、DBへと保存→Tokenを返す」という処理の流れをここで定義しています。
Interfaces
外部エージェントとアプリケーションを繋ぐ層、いわゆるアダプター(変換器)の役割を果たします。
外部エージェントからアプリケーションへの「入力」、アプリケーションから外部エージェントへの「出力」の出入り口となる層です。
Frameworks & Drivers
DBやUI、フレームワーク等の「外部エージェント」との接続と、RouterでのAPIリクエストの受付を行います。
サンプルでは、ここでMySQLとの接続、RouterによるAPIリクエストの受付・出力、HTTP通信の定義を行っています。
データフロー
さて、ここまでは他の記事でも解説されているんですが、図や説明を読んでも「データフロー」がどうなっているのかいまいちイメージできず苦しめられました。
この図で処理の流れは一応図解してあるんですが、コレを見ても全く理解できませんでした。
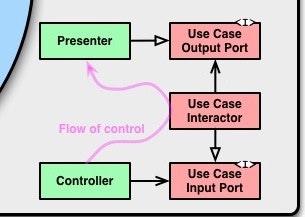
矢印が
Controller → Usecase → Presenter
で一方通行なら分かりますが、
「Controller ← Usecase → Presenterって何だ?」
「そもそも白矢印⇨と黒矢印→の違いは何?」
「Flow of controlって何やねん?」
と図の分かり難さに若干イライラしてました(笑)
クリーンアーキテクチャにおける全体のデータフローが分かりやすい図があったので紹介します。
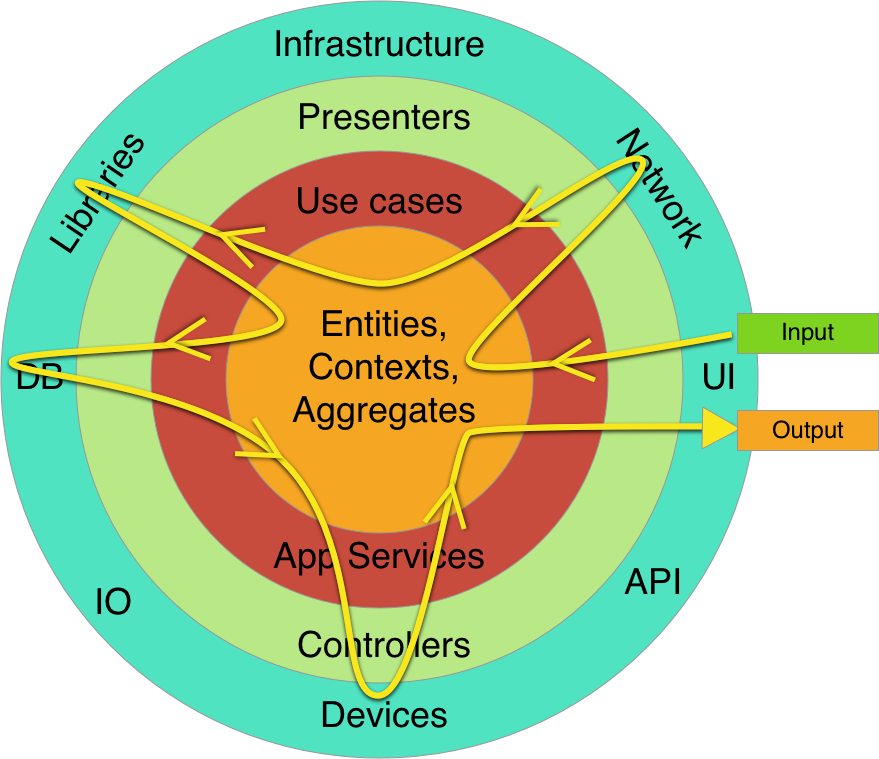
Frameworks&Drivers層からリクエストを受け付けた後、Interface(controller)を通ってUsecaseとEntitiesでアプリケーション固有のロジックを処理していくわけですが、その処理の過程でDBや外部フレームワークを使用するときは必ずInterfaceを経由し操作します。
そして最終的な処理結果をInterface(Presenter)を通してAPIのレスポンスとして返します。
この、**「EntitiesとUsecaseで定義しているアプリーケーションを中心に、Interfaceを通してそれぞれの外部エージェントを操作する」**というフローがクリーンアーキテクチャが同心円で例えられる所以だと思います。
上の「4層の役割」の部分でも説明していますが、「UIで入力を受け取った後、内部形式にデータを変換し、ビジネスロジックで処理、結果のデータを外部用に変換し、UIで出力する」というU字型の流れをイメージすると分かりやすいです。
クリーンアーキテクチャを導入するメリットは?
クリーンアーキテクチャを導入することで得られるメリットとしてよく書かれているのは以下5つ。
- フレームワークに依存しない
- テスト可能
- UIから独立している
- DBから独立している
- 外部機能から独立
個人的にクリーンアーキテクチャを実装してみて感じたメリットを挙げると、「外部の変更に強い」のと「テストがしやすい」というのが特に際立って良いなと思いました。
先にも書きましたが、クリーンアーキテクチャを導入した後でORMapperの導入がすごく楽になったり、依存関係が明示的にわかるのでコードの可読性も上がったり、MVCと比較するとかなり開発がやりやすかったです😊
クリーンアーキテクチャの実装(サンプル有)
というわけで長々と解説してきましたが、いよいよ実装していきます。
今回のサンプルアプリでは簡単に「ユーザー作成・情報取得を行うAPI」をクリーンアーキテクチャで作っています。↓↓↓
サンプルアプリ: https://github.com/maniCreate/GolangCleanArchitecture
エンドポイントはこんな感じです。
-
POST/auth/create... ユーザー登録 -
GET/user/get... ユーザー情報取得 -
POST/user/update... ユーザー情報更新
全部解説するのは骨が折れるので今回は/auth/craeteを解説していきます。
ディレクトリ構成
今回のサンプルアプリのディレクトリ構成はこちら。
.
├── README.md
├── cmd
│ └── main.go
├── config
│ └── config.go
├── db
│ └── setup.sql
├── domain
│ └── user.go
├── infrastructure
│ ├── datastore
│ │ └── db.go
│ ├── router
│ │ └── router.go
│ └── server
│ └── server.go
├── interface
│ ├── controllers
│ │ ├── app_controller.go
│ │ ├── auth_controller.go
│ │ ├── user_controller.go
│ │ └── middleware
│ │ └── auth.go
│ ├── database
│ │ ├── sql_repository.go
│ │ └── user_repository.go
│ ├── dcontext
│ │ └── dcontext.go
│ └── network
│ └── network.go
└── usecase
├── repository
│ └── user_repository.go
└── service
├── auth_service.go
└── user_service.go
本来ならInterface層のデータ変換は、SOLIDの原則に則り、
- Input担当 →
Controller - Output担当 →
Presenter
というように処理を分けるべきですが、今回は仕組みを理解しやすくするためにControllerで両方行います。(「出入り口」というイメージ)
レイヤー名とディレクトリ名の繋がりはこんな感じです↓↓↓
| レイヤー名 | ディレクトリ名 |
|---|---|
| Frameworks&Drivers層 | Infrastructure |
| Interface層 | Interface |
| Usecase層 | Usecase |
| Entities層 | Domain |
Infrastructrue
データの流れを見ながら解説していくためにまずはInfrastructureから解説していきます。
Interfaceでは、
- 外部エージェント(http, DB, Framework, UI, etc)の接続
- APIリクエストの受付(router)
を行います。
Infrastructure(Framework&Drivers層)は、その役割の通り、外部エージェントが存在する層です。
ここで接続した外部エージェントを、Interface層でアプリケーション内で使用する形式に変換します。
↓はMySQLへの接続を行っています。
import (
"database/sql"
"fmt"
"log"
"CleanArchitecture_SampleApp/config"
"CleanArchitecture_SampleApp/interface/database"
// blank import for MySQL driver
_ "github.com/go-sql-driver/mysql"
)
type ConnectedSql struct {
DB *sql.DB
}
//データベースの起動
func BootMysqlDB() *ConnectedSql {
//configからDBの読み取り
connectionCmd := fmt.Sprintf(
"%s:%s@tcp(%s:%s)/%s",
config.Conf.Database.User,
config.Conf.Database.Password,
config.Conf.Database.Host,
config.Conf.Database.Port,
config.Conf.Database.Db,
)
// 接続情報
var err error
DB, err := sql.Open("mysql", connectionCmd)
if err != nil {
log.Fatal(err)
}
//接続確認
err = DB.Ping()
if err != nil {
log.Fatal(err)
}
//外部のDBをConnectedSqlとして公開
conn := ConnectedSql{DB: DB}
return &conn
}
//interface層で使用可能なsqlのクエリ操作定義
func (conn *ConnectedSql) Exec(cmd string, args ...interface{}) (database.Result, error) {
result, err := conn.DB.Exec(cmd, args...)
if err != nil {
return nil, err
}
return &SqlResult{Result: result}, nil
}
//interface層で使用可能なsqlのクエリ操作定義
func (conn *ConnectedSql) Query(cmd string, args ...interface{}) (database.Rows, error) {
rows, err := conn.DB.Query(cmd, args...)
if err != nil {
return nil, err
}
return &SqlRows{Rows: rows}, nil
}
func (conn *ConnectedSql) QueryRow(cmd string, args ...interface{}) database.Row {
row := conn.DB.QueryRow(cmd, args...)
return &SqlRow{Row: row}
}
type SqlResult struct {
Result sql.Result
}
func (r *SqlResult) LastInsertId() (int64, error) {
return r.Result.LastInsertId()
}
func (r *SqlResult) RowsAffected() (int64, error) {
return r.Result.RowsAffected()
}
type SqlRows struct {
Rows *sql.Rows
}
func (r SqlRows) Scan(ctr ...interface{}) error {
return r.Rows.Scan(ctr...)
}
func (r SqlRows) Next() bool {
return r.Rows.Next()
}
func (r SqlRows) Close() error {
return r.Rows.Close()
}
type SqlRow struct {
Row *sql.Row
}
func (r SqlRow) Scan(ctr ...interface{}) error {
return r.Row.Scan(ctr...)
}
Interface
Interface層では、Infrastructure(Framework&Drivers層)で接続した外部エージェントを内部で使用できる形式へ変換、または内部で処理されたデータを外部エージェントで使用できる形式に変換する、「アダプター(変換器)」の役割を担います。
↓は/auth/createから呼び出されるハンドラを定義しています。
(「HTTPリクエスト→内部処理の起動」と、「処理結果→HTTPレスポンス」を担ってます)
func (ac *authController) CreateUser(ar network.ApiResponser) {
var authCreateRequest AuthCreateRequest
err := json.NewDecoder(ar.GetRequest().GetBody()).Decode(&authCreateRequest)
if err != nil {
log.Printf("%+v\n", err)
ar.BadRequest("Invalid Request")
return
}
authToken, err := ac.authService.CreateUser(&authCreateRequest.Name)
if err != nil {
return
}
authCreateResponse := AuthCreateResponse{
Token: *authToken,
}
ar.Success(authCreateResponse)
}
また、Infrastructure(Framework&Drivers層)で接続したDBを内部で使用する形として定義もしています。
ここで重要なのが、**「接続しているDBが何者なのかは、Interfaceは知る必要がある」**ということです。
この記事の冒頭でも話しておりますが、クリーンアーキテクチャの矛盾によりInterface層は、直接依存関係は持ちませんが、少なくとも外部エージェントを知っている必要があります。
↓ではuserRepositoryというstructが外部で接続しているDBをConnectedDBとして持っているのですが、このConnectedDBがリレーショナルDBなのか、インメモリDBなのかということを知った上で、内部で使用できるDBの操作を定義しています。
type userRepository struct {
db ConnectedDB
}
type UserRepository interface {
Store(user domain.User) error
FindByAuthToken(authToken string) (*domain.User, error)
FindByUserID(userID string) (*domain.User, error)
UpdateByUserID(userID string, name string) error
}
func NewUserRepository(db ConnectedDB) UserRepository {
return &userRepository{db}
}
// データベースにUserを登録する
func (userRepository *userRepository) Store(user domain.User) error {
_, err := userRepository.db.Exec("INSERT INTO user(user_id, auth_token, name) VALUES (?, ? ,?)", user.UserID, user.AuthToken, user.Name)
if err != nil {
log.Println(err)
return err
}
return nil
}
// AuthTokenを条件にレコードを取得する
func (userRepository *userRepository) FindByAuthToken(authToken string) (*domain.User, error) {
row := userRepository.db.QueryRow("SELECT * FROM user WHERE auth_token=?", authToken)
return ConvertToUser(row)
}
// UserIDを条件にレコードを取得する
func (userRepository *userRepository) FindByUserID(userID string) (*domain.User, error) {
row := userRepository.db.QueryRow("SELECT * FROM user WHERE user_id=?", userID)
return ConvertToUser(row)
}
// UserIDを条件にレコードを更新する
func (userRepository *userRepository) UpdateByUserID(userID string, name string) error {
_, err := userRepository.db.Exec("UPDATE user SET name=? WHERE user_id=?", name, userID)
if err != nil {
log.Println(err)
return err
}
return nil
}
// convertToUser rowデータをUserデータへ変換する
func ConvertToUser(row Row) (*domain.User, error) {
user := domain.User{}
err := row.Scan(&user.UserID, &user.AuthToken, &user.Name)
if err != nil {
log.Println(err)
return nil, err
}
return &user, nil
}
↓でInterfaceを定義しているように、DIP:依存関係逆転の原則により、直接依存関係を持たないようにすることでクリーンアーキテクチャの依存ルールを遵守することができるものの、**「見かけ上依存してないだけで実質依存している」**ということを覚えておいてください。
type ConnectedDB interface {
Exec(string, ...interface{}) (Result, error)
Query(string, ...interface{}) (Rows, error)
QueryRow(string, ...interface{}) Row
}
type Result interface {
LastInsertId() (int64, error)
RowsAffected() (int64, error)
}
type Rows interface {
Scan(...interface{}) error
Next() bool
Close() error
}
type Row interface {
Scan(...interface{}) error
}
Usecase
Interfaceから渡されたユーザー作成に必要な情報(Name)を元に、DBにユーザーを登録する処理をこのUsecaseで書いていきます。
func (authService *authService) CreateUser(userName *string) (*string, error) {
// UUIDでユーザIDを生成する
userID, err := uuid.NewRandom()
if err != nil {
log.Println(err)
return nil, err
}
userIDString := userID.String()
// UUIDで認証トークンを生成する
authToken, err := uuid.NewRandom()
if err != nil {
log.Println(err)
return nil, err
}
authTokenString := authToken.String()
user := domain.User{
UserID: userIDString,
AuthToken: authTokenString,
Name: *userName,
}
// データベースにユーザデータを登録する
err = authService.UserRepository.Store(user)
if err != nil {
log.Println(err)
return nil, err
}
return &authTokenString, nil
}
package repository
import (
"CleanArchitecture_SampleApp/domain"
)
//DIP(依存関係の逆転の原則)
type UserRepository interface {
Insert(user domain.User) error
SelectByAuthToken(authToken string) (*domain.User, error)
SelectByPrimaryKey(userID string) (*domain.User, error)
UpdateByPrimaryKey(userID string, name string) error
}
Domain
DomainでUserモデルを定義しています。
The CleanArchitectureでも書いてある通り、Entities層ではStructとしてビジネスオブジェクトを定義したり、ビジネスオブジェクトのメソッドとして一般的で高レベルなビジネスルールを定義したりします。
今回はメソッドで定義するビジネスルールはないので、ビジネスオブジェクトとしてUserだけ定義してます。
ちなみにリクエストで受け取るJSON形式やレスポンスとして返す時のJSON形式の定義は、「外⇄内の変換」を担うInterface層で行うべきなので、ここでは定義しません。
package domain
type User struct {
UserID string
AuthToken string
Name string
}
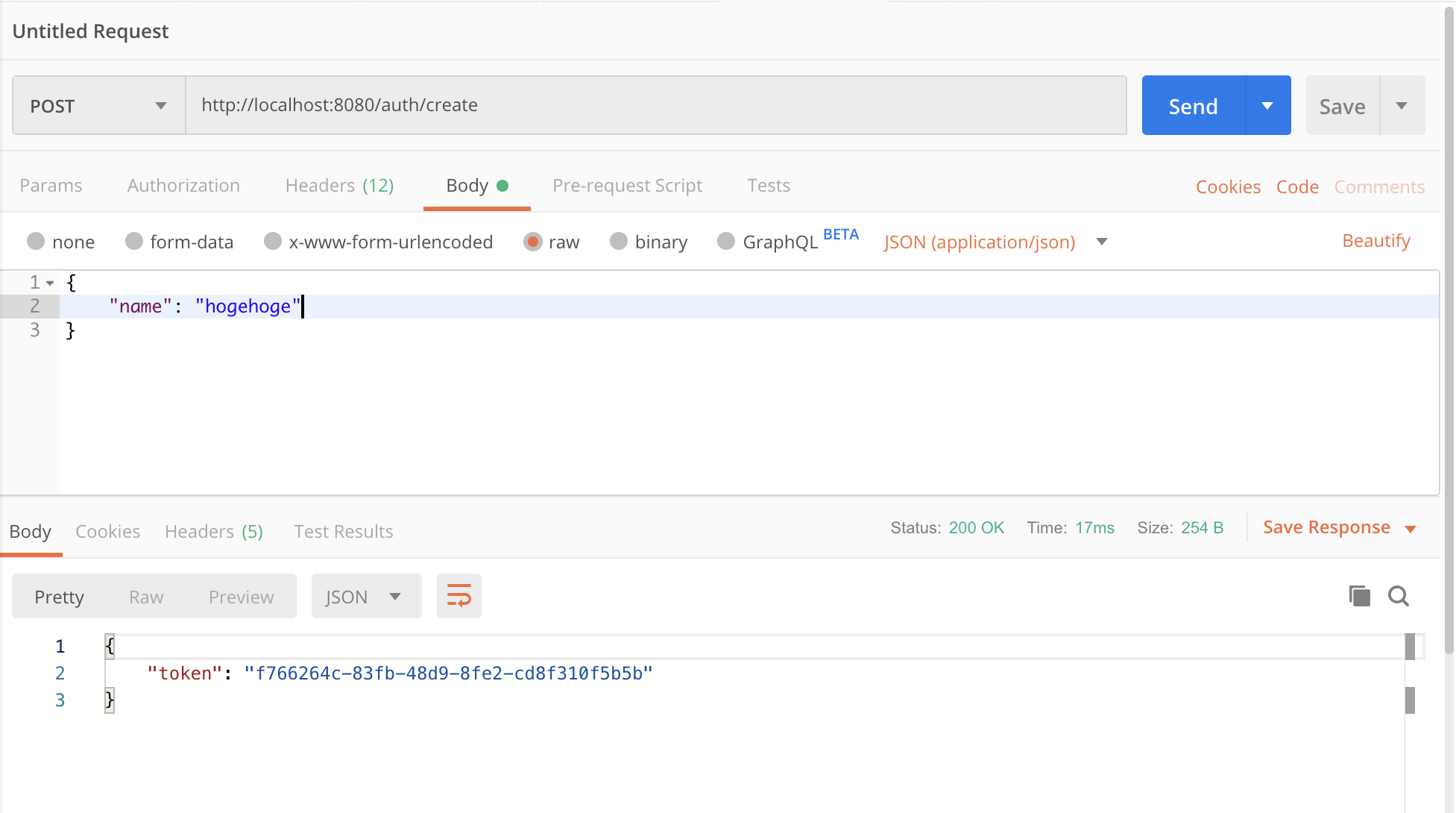
実行例
というわけでPostmanで/auth/createを叩いてみた場合こんな感じになります。tokenがちゃんと返ってきてますね🎉
実装中に詰まった所
DIPがどう作用してるのか?
クリーンアーキテクチャを勉強しているときに、InterfaceやUsecaseで、DBの実体を知ることなくDBを操作できることにめちゃめちゃ違和感を感じていました。
実行しているのはinterfaceなのに、なんでちゃんと動くのかと。
多分ここがクリーンアーキテクチャの初学者が最もつまづくポイントなのではないでしょうか?
これの答えとしては、Dependency Injection(依存性の注入)でinterfaceを満たしたDBが起動時に注入されているからです。
routerを設定する段階で各controllerを初期化しますが、その際に全てのcontrollerにDBを注入しています。
func NewAuthController(db database.ConnectedDB) AuthController {
return &authController{
authService: service.NewAuthService(
database.NewUserRepository(db),
),
}
}
ここで注入されているdbはConnectedSqlというstructで、sql_repositoryで定義したinterfaceのメソッドを全て満たしたものになります。
package database
type ConnectedDB interface {
Exec(string, ...interface{}) (Result, error)
Query(string, ...interface{}) (Rows, error)
QueryRow(string, ...interface{}) Row
}
↑↑↑
datastore.ConnectedSqlは、ちゃんとdatabase.ConnectedDBのinterfaceを満たしていますよね!
↓↓↓
package datastore
type ConnectedSql struct {
DB *sql.DB
}
//interface層で使用可能なsqlのクエリ操作定義
func (conn *ConnectedSql) Exec(cmd string, args ...interface{}) (database.Result, error) {
result, err := conn.DB.Exec(cmd, args...)
if err != nil {
return nil, err
}
return &SqlResult{Result: result}, nil
}
//interface層で使用可能なsqlのクエリ操作定義
func (conn *ConnectedSql) Query(cmd string, args ...interface{}) (database.Rows, error) {
rows, err := conn.DB.Query(cmd, args...)
if err != nil {
return nil, err
}
return &SqlRows{Rows: rows}, nil
}
func (conn *ConnectedSql) QueryRow(cmd string, args ...interface{}) database.Row {
row := conn.DB.QueryRow(cmd, args...)
return &SqlRow{Row: row}
}
まとめ
4日でクリーンアーキテクチャを理解するのはかなり大変でしたが、きちんと概念と仕組みを理解してコードを書くのは凄く楽しいですね!
実装に落とし込めるレベルまでにアーキテクチャの理解を深めるのは時間もかかりますし、目にも疲労が溜まって「あああああああ!!!!」ってなりますが、それを乗り越えてしっかり設計できた時には違う意味で「あああああああ!!!!」ってなり記事で書かれていることが一気にわかるようになります。
たった4日、されど4日でこんなに成長できるものなんだなと今回初めて気づかされました。
皆さんもぜひ今まで手が出せなかった技術の勉強に全力を注いでみてはいかがでしょうか😇
長くなりましたが、最後までお読み頂きありがとうございました!
お世話になった記事たち
最後にクリーンアーキテクチャの勉強でお世話になった記事を載せておきます。
(勧めて頂いた書籍も載せてます)
ありがとうございました!
【理解編】
- クリーンアーキテクチャ(The Clean Architecture翻訳)
- Clean Architecture : Part 2 – The Clean Architecture - crops.net
- 鵜呑みにしないで! —— 書籍『クリーンアーキテクチャ』所感 ≪null 篇≫
【実装編】
- Clean ArchitectureでAPI Serverを構築してみる - Qiita
- 【ボブおじさんのClean Architectureまとめ】オブジェクト指向 ~SOLIDの原則~ - Qiita
- Goで書くClean Architecture API - Qiita
- Go言語でダックタイピングをやってみる
【書籍】