導入の経緯
観点別評価という面倒なものが導入されたので,観点別に配点を計算するようにプログラムを改良
環境
PCというかOS
macOS 14.4.1 ←動作確認済
(pythonやOpen CVが使えれば何でもいい)
python
python 3.8.1
スキャナー
canonの自動送り(中古で2,3万?)
スキャナーソフト
CaptureOnTouch
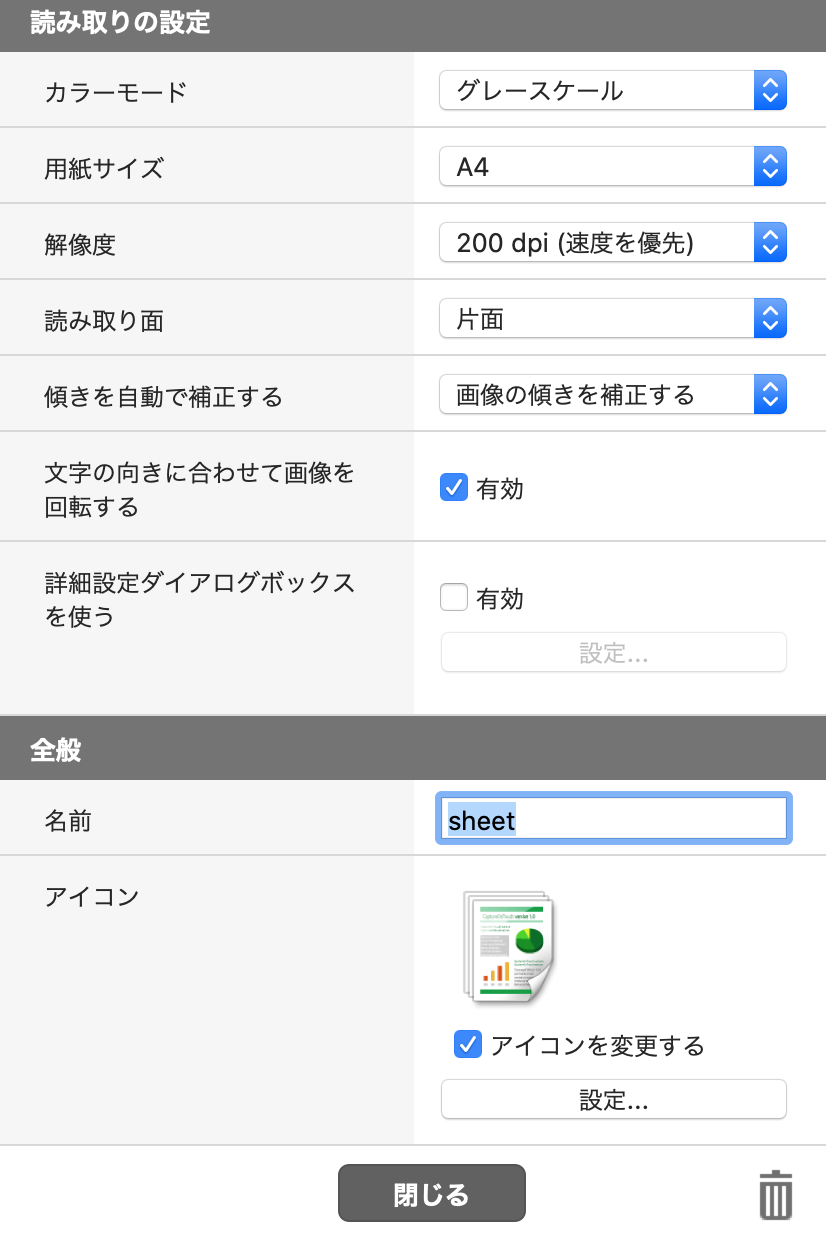
設定
・グレースケール
・200dpi
・jpeg
・3標準

詳細設定で連番にするのを忘れずに
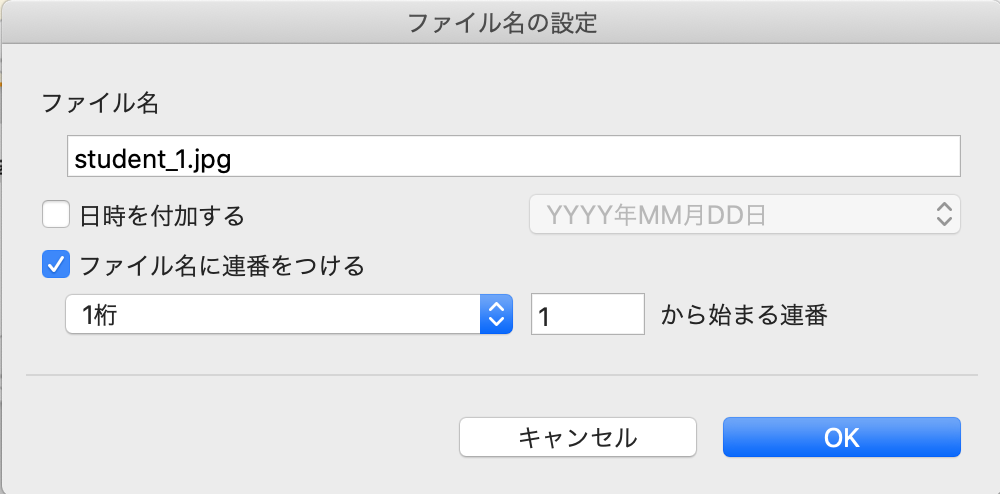
この名前の付け方がおかしいと
プログラムをまわしたとき,エラーになります.
その他細かい設定
読み取ったやつ

必要なライブラリ
cv2
numpy
statistics
glob
もしなければ
$ pip install cv2
で適宜インストール
必要なもの
・記入済みマークシート用紙を含むディレクトリ(student)
・マーカー(maker.jpg)
(スキャナで読み取ったマークシートの黒四角を切り抜いたもの)
・プログラム(mark35.py)
・空のディレクトリ(result)

これを同一ディレクトリ(上の図の場合l2)に入れて実行
$ python mark35.py
エラーがなければ,
結果出力用のディレクトリ(result)に
答案用紙が作成される.
あとはこれらをまとめてコピーして配布
プログラムソースコード
mark35.py
#ライブラリを取得
import numpy as np
import cv2
import statistics
import glob
#正解,配点記入欄
number = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35] #番号
eanswer = [3, 7, 5, 4, 4, 6, 3, 6, 9, 3, 8, 3, 2, 3, 4, 4, 4, 6, 2, 2, 3, 6, 6, 2, 4, 7, 8, 1, 4, 2, 2, 2, 8, 6, 5] #正解
allo = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 3, 3, 3, 3] #配点
kant = [2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 1, 1, 2, 2] #観点1知識技能2思考判断
#観点合計計算
model_kan1 = []
model_kan2 = []
for al, ka in zip(allo, kant):
if str(ka) == str(1):
model_kan1.append(al)
elif str(ka) == str(2):
model_kan2.append(al)
model_total_kan1 = round(sum(model_kan1),1) #観点1の合計
model_total_kan2 = round(sum(model_kan2),1) #観点2の合計
#正解は1,不正解は2
T = "1"
F = "0"
E = "20" #マークミスエラー用
#画像認識の閾値
threshold1 = 0.5 #閾値
threshold2 = 255*500 #閾値
#マークシートの形式
n_col = 11 # マークの列数(左黒四角の左辺〜右黒四角の左辺)
n_row = 40 # マークの行数(マークする番号の開始〜終了までの行数)
margin_top = 3 # 上余白行数(上黒四角の上辺〜組番号までの行数)
margin_bottom = 0 # 下余白行数(下黒四角の上辺〜最後の問までの行数)
start = 5 #出席番号の分の列#百の位〜解答欄までの列の総計
n_row_total = n_row + margin_top + margin_bottom #行数(マーク行 + 上余白 + 下余白)
#グレースケール (mode = 0)でファイルを読み込む
marker=cv2.imread('marker.jpg',0)
#ここまでは自分で調節
########################################################################
#スキャナーで読み取ったシートのファイル数を取得
jpgcount = len(glob.glob1('student','*.jpg'))
print('読み込みファイル数',jpgcount)
matrix = [] #生徒x問題x各項目(正誤,正答率等)のリスト作成
studentnamelist = [] #出席番号のリスト
studentnamelist3 = [] #数字のみのリスト
#######################################
#ここから各生徒の回答を読み込むループ
for k in range(jpgcount):
print('####################')
#スキャン画像を読み込む
img = cv2.imread('student/student_%s.jpg' %str(k+1), 0)
#マーカー検出
res = cv2.matchTemplate(img, marker, cv2.TM_CCOEFF_NORMED)
loc = np.where( res >= threshold1)
#cv2.imwrite('resimg.jpg',img)
#マークシート部分の切り抜き
mark_area={}
mark_area['top_x']= min(loc[1])
mark_area['top_y']= min(loc[0])
mark_area['bottom_x']= max(loc[1])
mark_area['bottom_y']= max(loc[0])
img = img[mark_area['top_y']:mark_area['bottom_y'],\
mark_area['top_x']:mark_area['bottom_x']]
#cv2.imwrite('kiri.jpg',img)
#リサイズ
#Answer = cv2.imread('kiri.jpg', 0)
Answer_Resize = cv2.resize(img, (n_col*100, n_row_total*100))
#cv2.imwrite('kiri.jpg', Answer_Resize)
#ぼかし
Answer_Blur = cv2.GaussianBlur(Answer_Resize, (5,5), 0)
#cv2.imwrite('Answer_Blur.jpg',Answer_Blur)
#2値化
RetVal, Answer_Binarization = \
cv2.threshold(Answer_Blur, 50, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
#cv2.imwrite('Answer_Binarization.jpg',Answer_Binarization)
#白黒反転
Answer_Reverse = 255 - Answer_Binarization
#cv2.imwrite('Answer_Reverse.jpg',Answer_Reverse)
#行と列に分解して各場所の階調の合計値を計算
Result = []
for row in range(margin_top+1, margin_top+1+n_row):
tmp_Answer = Answer_Reverse [(row-1)*100:row*100,]#
cv2.imwrite("PNG/Answer_Tmp%d.png" % row, tmp_Answer)#
tmp_Answer = Answer_Reverse [(row-1)*100:row*100,]
Area_sum = []
for col in range(n_col):
Area_sum.append(np.sum(tmp_Answer[:,col*100:(col+1)*100]))
Result.append(Area_sum > np.median(threshold2))#閾値
#ここから番号の読み取り#########
#組番号の読み取り
cl = np.where(Result[0]==True)[0]#+1
if len(cl)>1:
print("ダブルマーク")
print("組番号読取失敗x")
continue
elif len(cl)==1:
cla = str(cl[0])
else:
print("ノーマーク")
print("組番号読取失敗x")
continue
#出席番号の読み取り
num = []
#一桁目読み取り
re = np.where(Result[1]==True)[0]#+1
if len(re)>1:
print("ダブルマーク")
print("出席番号読取失敗x")
continue
elif len(re)==1:
num.append(int(re))
else:
print("ノーマーク")
print("出席番号読取失敗x")
continue
#二桁目読み取り
re = np.where(Result[2]==True)[0]#+1
if len(re)>1:
print("ダブルマーク")
print("出席番号読取失敗x")
continue
elif len(re)==1:
num.append(int(re))
else:
print("ノーマーク")
print("出席番号読取失敗x")
continue
#出席番号読み取り成功後
nu = str(num[0])+ str(num[1])
code = str(cla) + str(nu)
#ターミナルに表示
print('出席番号%s' % code)
#各生徒の空の配列をつくる
exec_hako = 'student_' + str(code) + '=[]'
exec(exec_hako)
#出力ファイル作成(生徒に配るやつ)##################################
#回答番号の読み取り
answer = []
for x in range(start,len(Result)):
res = np.where(Result[x]==True)[0]#+1
if len(res)>1:
res = 20
print("問%sダブルマーク" % (x-start+1))
answer.append(res)
elif len(res)==1:
answer.append(int(res[0]))#リスト化
else:
res = 20
print("問%sノーマーク" % (x-start+1))
answer.append(res)#リスト化
s_answer=[]
r_or_w = []
kant1 = []
kant2 = []
for nu, an, ea, al, ka in zip(number, answer, eanswer, allo, kant):
if str(an) == str(20):
s_answer.append(int(E))
r_or_w.append(int(F))
kant1.append(int(F))
kant2.append(int(F))
elif str(an) == str(ea):
s_answer.append(an)
r_or_w.append(int(T))
if str(ka) == str(1):
kant1.append(int(T))#
kant2.append(int(F))#
else:
kant1.append(int(F))#
kant2.append(int(T))#
else:
s_answer.append(an)
r_or_w.append(int(F))
kant1.append(int(F))
kant2.append(int(F))
exec_append = 'student_' + str(code) + '.append(number)'#matrix0
exec(exec_append)
exec_append = 'student_' + str(code) + '.append(eanswer)'#1
exec(exec_append)
exec_append = 'student_' + str(code) + '.append(s_answer)'#2
exec(exec_append)
exec_append = 'student_' + str(code) + '.append(r_or_w)'#3
exec(exec_append)
exec_append = 'student_' + str(code) + '.append(allo)'#4
exec(exec_append)
#観点別
exec_append = 'student_' + str(code) + '.append(kant1)'#matrix5
exec(exec_append)
exec_append = 'student_' + str(code) + '.append(kant2)'#matrix6
exec(exec_append)
#観点別合計
exec_append = 'student_' + str(code) + '.append(kant)'#matrix7
exec(exec_append)
print("読取完了o")
#リスト作成
studentnamelist.append('%s.txt' % code)
studentnamelist3.append(code)
#おわり
#正答率などの計算#####################
#各生徒の問題x各項目(二次元)を連結して生徒x問題x各項目(三次元)
for i in range(len(studentnamelist)):
exec_append = 'matrix.append(student_' + str(studentnamelist3[i]) + ')'
exec(exec_append)
#合計点
total=[]
totalkan1=[]
totalkan2=[]
#生徒方向のループ
for i in range(len(studentnamelist)):
#配列の作成
exec_append = 'qu' + str(i+1) + '=[]'
exec(exec_append)
#配列の作成観点1
exec_append = 'k1' + str(i+1) + '=[]'
exec(exec_append)
#配列の作成観点2
exec_append = 'k2' + str(i+1) + '=[]'
exec(exec_append)
#問方向のループ
for j in range(len(matrix[0][0])):
exec_append = 'qu' + str(i+1) + '.append((matrix['+ str(i) + '][3][' + str(j) + '])\
*(matrix[' + str(i) + '][4][' + str(j) + ']))'
exec(exec_append)
#観点1
exec_append = 'k1' + str(i+1) + '.append((matrix['+ str(i) + '][5][' + str(j) + '])\
*(matrix[' + str(i) + '][4][' + str(j) + ']))'
exec(exec_append)
#観点2
exec_append = 'k2' + str(i+1) + '.append((matrix['+ str(i) + '][6][' + str(j) + '])\
*(matrix[' + str(i) + '][4][' + str(j) + ']))'
exec(exec_append)
#合計計算
exec_append = 'total.append(sum(qu' + str(i+1) + '))'
exec(exec_append)
#観点合計計算
exec_append = 'totalkan1.append(sum(k1' + str(i+1) + '))'
exec(exec_append)
exec_append = 'totalkan2.append(sum(k2' + str(i+1) + '))'
exec(exec_append)
#平均点
av = sum(total)/len(studentnamelist)
#観点1平均
av_kan1 = sum(totalkan1)/len(studentnamelist)
#観点2平均
av_kan2 = sum(totalkan2)/len(studentnamelist)
#標準偏差
std = statistics.stdev(total)
#中央値
med = statistics.median(total)
#偏差値
dv = []
for i in range(len(studentnamelist)):
dvi = round(50 + ((total[i]-av)/std)*10,1)
dv.append(dvi)
#度数分布
f00_04 = 0
f05_09 = 0
f10_14 = 0
f15_19 = 0
f20_24 = 0
f25_29 = 0
f30_34 = 0
f35_39 = 0
f40_44 = 0
f45_49 = 0
f50_54 = 0
f55_59 = 0
f60_64 = 0
f65_69 = 0
f70_74 = 0
f75_79 = 0
f80_84 = 0
f85_89 = 0
f90_94 = 0
f95_99 = 0
f100 = 0
for i in range(len(total)):
if total[i] >= 0 and total[i] < 5:
f00_04 = f00_04 + 1
elif total[i] >= 5 and total[i] < 10:
f05_09 = f05_09 + 1
elif total[i] >= 10 and total[i] < 15:
f10_14 = f10_14 + 1
elif total[i] >= 15 and total[i] < 20:
f15_19 = f15_19 + 1
elif total[i] >= 20 and total[i] < 25:
f20_24 = f20_24 + 1
elif total[i] >= 25 and total[i] < 30:
f25_29 = f25_29 + 1
elif total[i] >= 30 and total[i] < 35:
f30_34 = f30_34 + 1
elif total[i] >= 35 and total[i] < 40:
f35_39 = f35_39 + 1
elif total[i] >= 40 and total[i] < 45:
f40_44 = f40_44 + 1
elif total[i] >= 45 and total[i] < 50:
f45_49 = f45_49 + 1
elif total[i] >= 50 and total[i] < 55:
f50_54 = f50_54 + 1
elif total[i] >= 55 and total[i] < 60:
f55_59 = f55_59 + 1
elif total[i] >= 60 and total[i] < 65:
f60_64 = f60_64 + 1
elif total[i] >= 65 and total[i] < 70:
f65_69 = f65_69 + 1
elif total[i] >= 70 and total[i] < 75:
f70_74 = f70_74 + 1
elif total[i] >= 75 and total[i] < 80:
f75_79 = f75_79 + 1
elif total[i] >= 80 and total[i] < 85:
f80_84 = f80_84 + 1
elif total[i] >= 85 and total[i] < 90:
f85_89 = f85_89 + 1
elif total[i] >= 90 and total[i] < 95:
f90_94 = f90_94 + 1
elif total[i] >= 95 and total[i] < 100:
f95_99 = f95_99 + 1
elif total[i] == 100:
f100 = f100 + 1
#正答率の計算
#matrixからの切り出しright and wrong(raw)
for i in range(len(matrix[0][0])):
exec_append = 'raw' + str(i+1) + '=[]'
exec(exec_append)
#生徒方向へのループ
for i in range(len(studentnamelist)):
#問題方向へのループ
for j in range(len(matrix[0][0])):
exec_append2 = 'raw' + str(j+1) + '.append(matrix[' + str(i) + \
'][3][' + str(j) + '])'#[3]は正答率を書き込む列によって変更
exec(exec_append2)
#Correct answer rate(car)
car = []
for i in range(len(matrix[0][0])):
exec_append = 'car.append(sum(raw' + str(i+1) + ')/len(raw' + str(i+1) + ')*100)'#正答率
exec(exec_append)
#少数第二位まで四捨五入
car = [round(car[n], 1) for n in range(len(car))]
#正答率をmatrixの列の端っこにくっつける
#つまり正答率はmatrix8
for row in matrix:
row.append(car)
#正誤をoとxに置き換え
for i in range(len(studentnamelist)):
matrix[i][3] = ['o' if j == 1 else j for j in matrix[i][3]]
matrix[i][3] = ['x' if j == 0 else j for j in matrix[i][3]]
matrix[i][2] = ['?' if j == 20 else j for j in matrix[i][2]]
#観点別の方も置き換え
matrix[i][7] = ['基' if j == 1 else j for j in matrix[i][7]]
matrix[i][7] = ['応' if j == 2 else j for j in matrix[i][7]]
#平均,標準偏差を四捨五入
av = round(av,1)
av_kan1 = round(av_kan1,1)
av_kan2 = round(av_kan2,1)
std = round(std,1)
for i in range(len(studentnamelist)):
temp = 0
temp = 'result/' + str(studentnamelist[i])
with open(temp, 'w') as f:
print('出席番号%s' % (studentnamelist[i])[0:3], file=f)
print('\n番号'.rjust(2),'正解'.rjust(2),'回答'.rjust(2),'正誤'.rjust(2),'配点'.rjust(2),'正答率'.rjust(2),'観点'.rjust(2),file=f)
for j in range(len(matrix[0][0])):
print(str(matrix[i][0][j]).rjust(4),str(matrix[i][1][j]).rjust(4),\
str(matrix[i][2][j]).rjust(4),str(matrix[i][3][j]).rjust(4),\
str(matrix[i][4][j]).rjust(4),' ',str(matrix[i][8][j]).rjust(4),str(matrix[i][7][j]).rjust(4),file=f)
print('\n合計点',str(total[i]).rjust(3),' 偏差値',str(dv[i]).rjust(3),file=f)
print('(基',str(totalkan1[i]).rjust(3) ,' 応',str(totalkan2[i]).rjust(3),')',file=f)
print('------------------------------',file=f)
print('平均点',str(av).rjust(3),' 標準偏差',str(std).rjust(3),file=f)
print('(基',str(av_kan1).rjust(3),' 応',str(av_kan2).rjust(3),')',file=f)
print('\n度数分布',file=f)
print('100 ',str(f100).rjust(2), ' | ' ,file=f)
print('95 ~ 99 ',str(f95_99).rjust(2),' | 45 ~ 49 ',str(f45_49).rjust(2),file=f)
print('90 ~ 94 ',str(f90_94).rjust(2),' | 40 ~ 44 ',str(f40_44).rjust(2),file=f)
print('85 ~ 89 ',str(f85_89).rjust(2),' | 35 ~ 39 ',str(f35_39).rjust(2),file=f)
print('80 ~ 84 ',str(f80_84).rjust(2),' | 30 ~ 34 ',str(f30_34).rjust(2),file=f)
print('75 ~ 79 ',str(f75_79).rjust(2),' | 25 ~ 29 ',str(f25_29).rjust(2),file=f)
print('70 ~ 74 ',str(f70_74).rjust(2),' | 20 ~ 24 ',str(f20_24).rjust(2),file=f)
print('65 ~ 99 ',str(f65_69).rjust(2),' | 15 ~ 19 ',str(f15_19).rjust(2),file=f)
print('60 ~ 64 ',str(f60_64).rjust(2),' | 10 ~ 14 ',str(f10_14).rjust(2),file=f)
print('55 ~ 59 ',str(f55_59).rjust(2),' | 5 ~ 9 ',str(f05_09).rjust(2),file=f)
print('50 ~ 54 ',str(f50_54).rjust(2),' | 0 ~ 4 ',str(f00_04).rjust(2),file=f)
#模範解答作成
model_dv = round(50 + ((sum(matrix[0][4])-av)/std)*10,1)#偏差値
model_total = round(sum(matrix[0][4]),1)
with open('result/model_answer.txt', 'w') as f:
print('模範解答', file=f)
print('\n番号'.rjust(2),'正解'.rjust(2),'回答'.rjust(2),'正誤'.rjust(2),'配点'.rjust(2),'正答率'.rjust(2),'観点'.rjust(2),file=f)
for j in range(len(matrix[0][0])):
print(str(matrix[i][0][j]).rjust(4),str(matrix[i][1][j]).rjust(4),str(matrix[i][1][j]).rjust(4),'o'.rjust(4),\
str(matrix[i][4][j]).rjust(4),' ',str(matrix[i][8][j]).rjust(4),str(matrix[i][7][j]).rjust(4),file=f)
print('\n合計点',str(model_total).rjust(3),' 偏差値',str(model_dv).rjust(3),file=f)
print('(基',str(model_total_kan1).rjust(3) ,' 応',str(model_total_kan2).rjust(3),')',file=f)
print('------------------------------',file=f)
print('平均点',str(av).rjust(3),' 標準偏差',str(std).rjust(3),file=f)
print('(基',str(av_kan1).rjust(3),' 応',str(av_kan2).rjust(3),')',file=f)
print('\n度数分布',file=f)
print('100 ',str(f100).rjust(2), ' | ' ,file=f)
print('95 ~ 99 ',str(f95_99).rjust(2),' | 45 ~ 49 ',str(f45_49).rjust(2),file=f)
print('90 ~ 94 ',str(f90_94).rjust(2),' | 40 ~ 44 ',str(f40_44).rjust(2),file=f)
print('85 ~ 89 ',str(f85_89).rjust(2),' | 35 ~ 39 ',str(f35_39).rjust(2),file=f)
print('80 ~ 84 ',str(f80_84).rjust(2),' | 30 ~ 34 ',str(f30_34).rjust(2),file=f)
print('75 ~ 79 ',str(f75_79).rjust(2),' | 25 ~ 29 ',str(f25_29).rjust(2),file=f)
print('70 ~ 74 ',str(f70_74).rjust(2),' | 20 ~ 24 ',str(f20_24).rjust(2),file=f)
print('65 ~ 99 ',str(f65_69).rjust(2),' | 15 ~ 19 ',str(f15_19).rjust(2),file=f)
print('60 ~ 64 ',str(f60_64).rjust(2),' | 10 ~ 14 ',str(f10_14).rjust(2),file=f)
print('55 ~ 59 ',str(f55_59).rjust(2),' | 5 ~ 9 ',str(f05_09).rjust(2),file=f)
print('50 ~ 54 ',str(f50_54).rjust(2),' | 0 ~ 4 ',str(f00_04).rjust(2),file=f)
print('####################')
print('読み込みファイル数',jpgcount)
print('正常に読み込めた人数',len(studentnamelist))