4x4リバーシのPythonプログラムのプログラムを利用し、Q Learningによる強化学習を試してみます。
Q学習の実装
ライブラリーのロード
import numpy as np
定数の定義
学習率、最大試行数の設定で学習の進み方が変わってきます。
# 定数の設定
GAMMA = 0.99 # 時間割引率
ETA = 0.5 # 学習係数
MAX_STEPS = 200 # 1試行のstep数
NUM_EPISODES = 30000 # 最大試行回数
Agentクラスの実装
class Agent:
def __init__(self):
self.brain = Brain()
def update_Q_function(self, observation, action, reward, observation_next):
'''Q関数の更新'''
self.brain.update_Q_table(observation, action, reward, observation_next)
def get_action(self, observation, step):
'''行動の決定'''
action = self.brain.decide_action(observation, step)
return action
Brainクラスの実装
epsilonを初期値と減少率を適切に設定しないと学習が進みません。
先手後手の報酬の与え方、理解しきれていないのですが、取りあえず、実装してあります。
class Brain:
def __init__(self):
self.q_table = {}
self.epsilon = 1
def update_Q_table(self, state, action, reward, state_next):
'''QテーブルをQ学習により更新"'''
qs = self.get_q(state)
qs_next = self.get_q(state_next)
if len(qs_next) == 0:
qs_next = qs
# print('qs:{}, qs_next:{}'.format(qs, qs_next))
# Max_Q_next = max(qs_next, key=qs_next.get)
if state[2] == BLACK:
Max_Q_next = max(qs_next.values())
self.q_table[state][action] = self.q_table[state][action] + \
ETA * (reward + GAMMA * Max_Q_next - self.q_table[state][action])
else:
Max_Q_next = min(qs_next.values()) * -1
q = -1 * self.q_table[state][action]
reward *= -1
self.q_table[state][action] = -1 * (q + ETA * (reward + GAMMA * Max_Q_next - q))
# print('Max_Q_next:{}, state:{}, action:{}'.format(Max_Q_next, state, action))
def decide_action(self, state, episode):
'''ε-greedy法で徐々に最適行動のみを採用する。'''
if self.epsilon > 0.01:
self.epsilon -= 1 / 30000
if self.epsilon <= np.random.uniform(0, 1):
qs = self.get_q(state)
if state[2] == BLACK:
action = max(qs, key=qs.get)
else:
action = min(qs, key=qs.get)
# print('action:{}, qs:{}'.format(action, qs))
else:
board = Board([state[0], state[1]], state[2])
action = np.random.choice(board.movable_pos_array())
# print('action:{}, movable_pos:{}'.format(action, board.movable_pos_array()))
return action
def get_q(self, state):
if self.q_table.get(state) is None:
board = Board([state[0], state[1]], state[2])
self.q_table[state] = dict([(act, 0) for act in board.movable_pos_array()])
return self.q_table[state]
Environmentクラスの実装
Q学習を行うPlayerQをエピソードごと、手番を変えながら学習を行います。
先手の勝利に報酬+1を後手の勝利に報酬-1を与えるようにしています。
後手番の場合は、評価値が低い手を選択するよう実装しています。
class Environment:
'''4x4リバーシを実行する環境のクラス'''
def __init__(self):
self.win_rate_history = []
def run(self):
'''実行'''
win_episodes = 0 # 勝利した試行数
players = [
PlayerQ(BLACK),
PlayerRandom(WHITE),
]
for episode in range(NUM_EPISODES): # 試行回数分繰り返す。
board = Board()
turn = BLACK
# print(board.to_string())
while not board.is_game_over():
state = board.state()
action = players[turn].act(board, episode)
# print(board.to_string())
if board.is_game_over():
if board.winner() == BLACK:
reward = 1
players[BLACK].win += 1.0
players[WHITE].lose += 1.0
elif board.winner() == WHITE:
reward = -1
players[BLACK].lose += 1.0
players[WHITE].win += 1.0
else:
reward = 0
players[BLACK].draw += 1.0
players[WHITE].draw += 1.0
else:
reward = 0
if action != 0:
players[turn].update_Q_function(state, action, reward, board.state())
players[turn ^ 1].update_Q_function(state, action, reward, board.state())
turn ^= 1
# print('winner:{}'.format(board.winner()))
# print(players[1].agent.brain.q_table)
players.reverse()
if (episode + 1) % 1000 == 0:
win_rate = players[BLACK].win / (players[BLACK].win + players[BLACK].lose + players[BLACK].draw)
print('episode:{}, win:{}, lose:{}, draw:{}, win rate:{}'.format(
episode + 1, players[BLACK].win, players[BLACK].lose, players[BLACK].draw, win_rate))
players[BLACK].win, players[BLACK].lose, players[BLACK].draw = 0.0, 0.0, 0.0
players[WHITE].win, players[WHITE].lose, players[WHITE].draw = 0.0, 0.0, 0.0
self.win_rate_history.append([episode + 1, win_rate])
# print(self.agent.brain.q_table)
学習実行
# main
env = Environment()
env.run()
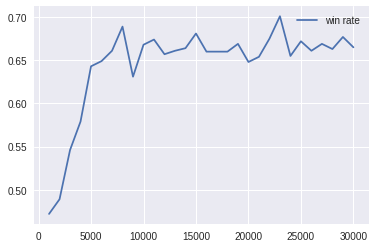
episode:1000, win:472.0, lose:438.0, draw:90.0, win rate:0.472
episode:2000, win:489.0, lose:393.0, draw:118.0, win rate:0.489
episode:3000, win:546.0, lose:361.0, draw:93.0, win rate:0.546
episode:4000, win:579.0, lose:341.0, draw:80.0, win rate:0.579
episode:5000, win:643.0, lose:312.0, draw:45.0, win rate:0.643
episode:6000, win:649.0, lose:316.0, draw:35.0, win rate:0.649
episode:7000, win:661.0, lose:307.0, draw:32.0, win rate:0.661
episode:8000, win:689.0, lose:270.0, draw:41.0, win rate:0.689
episode:9000, win:631.0, lose:328.0, draw:41.0, win rate:0.631
episode:10000, win:668.0, lose:300.0, draw:32.0, win rate:0.668
episode:11000, win:674.0, lose:287.0, draw:39.0, win rate:0.674
episode:12000, win:657.0, lose:300.0, draw:43.0, win rate:0.657
episode:13000, win:661.0, lose:293.0, draw:46.0, win rate:0.661
episode:14000, win:664.0, lose:290.0, draw:46.0, win rate:0.664
episode:15000, win:681.0, lose:277.0, draw:42.0, win rate:0.681
episode:16000, win:660.0, lose:294.0, draw:46.0, win rate:0.66
episode:17000, win:660.0, lose:299.0, draw:41.0, win rate:0.66
episode:18000, win:660.0, lose:304.0, draw:36.0, win rate:0.66
episode:19000, win:669.0, lose:288.0, draw:43.0, win rate:0.669
episode:20000, win:648.0, lose:301.0, draw:51.0, win rate:0.648
episode:21000, win:654.0, lose:300.0, draw:46.0, win rate:0.654
episode:22000, win:675.0, lose:277.0, draw:48.0, win rate:0.675
episode:23000, win:701.0, lose:263.0, draw:36.0, win rate:0.701
episode:24000, win:655.0, lose:289.0, draw:56.0, win rate:0.655
episode:25000, win:672.0, lose:290.0, draw:38.0, win rate:0.672
episode:26000, win:661.0, lose:286.0, draw:53.0, win rate:0.661
episode:27000, win:669.0, lose:283.0, draw:48.0, win rate:0.669
episode:28000, win:663.0, lose:284.0, draw:53.0, win rate:0.663
episode:29000, win:677.0, lose:271.0, draw:52.0, win rate:0.677
episode:30000, win:665.0, lose:294.0, draw:41.0, win rate:0.665
勝率曲線
さらにエピソードを増やして学習していくと、なぜか勝率が下がっていってしまいます。
今後の検討課題です。
%matplotlib inline
import matplotlib.pyplot as plt
x = np.array(env.win_rate_history)[:, 0]
y = np.array(env.win_rate_history)[:, 1]
plt.plot(x, y, label="win rate")
plt.legend()
plt.show()