こちらは機械学習で地方競馬を予測するの続編になります。
前回は予測にk-NNを使ったので、今回はランダムフォレストを使って予測してみました。
ランダムフォレストとは
ランダムフォレストとは決定木をたくさん作り予測する方法です。分類問題なら各決定木の予測クラスの多数決をとり、回帰問題なら平均を予測値とします。
バギングとはどう違うの?
複数の決定木を用いる手法にバギングというものがあります。
バギングはデータ集合から復元抽出を行いB組のデータ集合を作ります。
各データ集合に対してB個の決定木で学習させて予測します。
バギングでは各決定木の違いがデータの組み合わせによる違いだけなのに対して、ランダムフォレストではバギングに加えて各決定木で使用する特徴量を、ランダムに選択します。
実装
では前回のデータに対してscikit-learnのRandomForestClassifier()を用いて実装します。
・n_estimators
決定木の個数を決めるのがこのn_estimatorsというパラメーターです。
k-NNので最適なパラメータを求めたのと同様に以下のように実装します。
df = pd.read_csv(data_csv)
df = df.dropna(how="any")
train_X, test_X, train_y, test_y = train_test_split(
df.loc[:,'velocity1':'dhweight'], df.result, test_size=0.2)
accuracy = []
n_estimators = np.arange(1,50)
for n in n_estimators:
model = RandomForestClassifier(n_estimators=n, random_state=42)
model.fit(train_X, train_y) # モデル作成実行
pred_y = model.predict(test_X) # 予測実行
accuracy.append(accuracy_score(test_y, pred_y)) # 精度格納
plt.plot(n_estimators, accuracy)
plt.show()
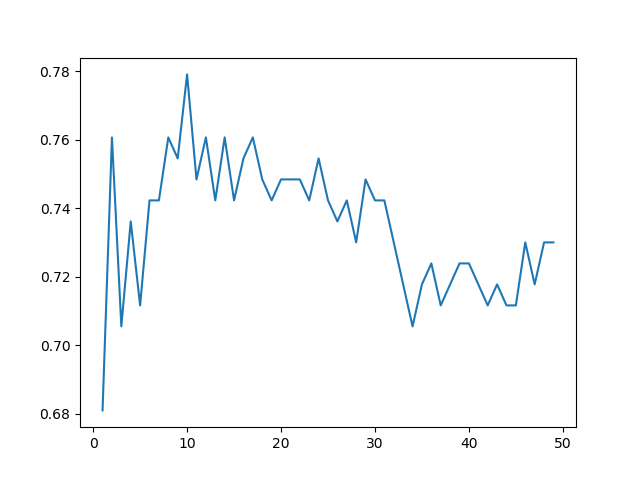
決定木の数が10個の時が最もよい精度が出ています。
他にも調整する必要があるパラメータがいくつかあるのですが、取りあえずn_estimators=10、他はデフォルト値を使って予測してみます。
||掛け金|払戻金|回収率|
|---|---|---|---|---|
|ランダムフォレスト|3000円|2340円|78%|
うーん、微妙ですね。どうやら手法を変える前に特徴量抽出をしっかりする必要がありそうですね。
次回は主成分分析を行います!