1. はじめに
この記事では、「ゼロから作るDeep Leaning 4 強化学習編」をもとに、GymnasiumのCartPole-v1に深層強化学習のDQNをPytorchで実装してみた内容を簡単にまとめました。書籍内では、OpenAI gymのCartPole-v0が取り上げられていますが、本記事では現在のGymnasiumバージョンとなりますので、ご参考ください。詳しい理論を知りたい場合は、ぜひ本書籍をご覧になってください。
2. 環境準備
- Python 3.12.7
- Numpy 1.26.4
- Pytorch 2.6.0+cu126 ※今回はCUDA無しで使用します。
- Gymnasium 1.0.0
3. CartPoleとは
CartPoleとは、ポール(棒)が倒れないように、カートを左右に動かしてバランスを保つゲームとなります。

行動(action)
プレイヤーが取れる行動は2つだけで、
- 左にカートを動かす。(actionとして0を入力する)
- 右にカートを動かす。(actionとして1を入力する)
状態(state)
現在の状況は4つの値で表現されます:
- カートの位置
- カートの速度
- ポールの角度
- ポールの角速度
報酬(Reward)
- 各ステップでポールが倒れずに立っていれば「報酬1」を獲得
- ポールが一定以上傾く、もしくはカートが画面の範囲外に出るとゲーム終了
つまり、長い時間ポールを倒さずに持っていればトータル報酬が多くなっていきます。
終了条件
- ポールが垂直から±12度以上傾く。
- カートがトラックの端(±2.4の範囲)を超える。
- または、最大500ステップまで経過するとエピソードが終了。(v0だと最大200ステップ)
4. 実装
実装するにあたってのDQNの基本的な構成要素は次の通りです。
- Q-networkとTD-network
- Q-network: 状態を入力とし、各行動のQ値(累積報酬の期待値)を出力するニューラルネットワーク。
- TD-network: Q-networkのコピーで、一定間隔で更新されます。学習の安定性を保つために使用します。
- 経験再生バッファ
- Replay Buffer: 過去の経験(状態、行動、報酬、次の状態、終了フラグ)を格納します。
- ランダムに経験をサンプリングしてネットワークを学習させることで、データの相関を減らし、効率的な学習を実現します。
- エージェントクラス
- エージェントクラスは行動選択や学習処理を統括します。
- 学習のループ
- ニューラルネットワークから次のアクションを決定、記録、更新、状態の取得といった一連のループを作成します。
Q-networkとTD-network
Q-networkとTD-networkを作成します。2つとも同じ構造で、Q-networkの重みとバイアスを定期的にコピーしてTD-networkに適応させます。
import copy
from collections import deque
import random
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class QNet(nn.Module):
def __init__(self, action_size):
super().__init__()
self.l1 = nn.Linear(4, 128)
self.l2 = nn.Linear(128, 128)
self.l3 = nn.Linear(128, action_size)
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.l3(x)
return x
ニューラルネットワークの層構成は以下の図の通りとなっております。inputでカートの位置,カートの速度,ポールの角度,ポールの角速度の4つを入力し、途中に128個のニューロンを持つ層を2つ挟み、最終的にアクション数分(今回は2つ)のQ値が出力される構成となっております。
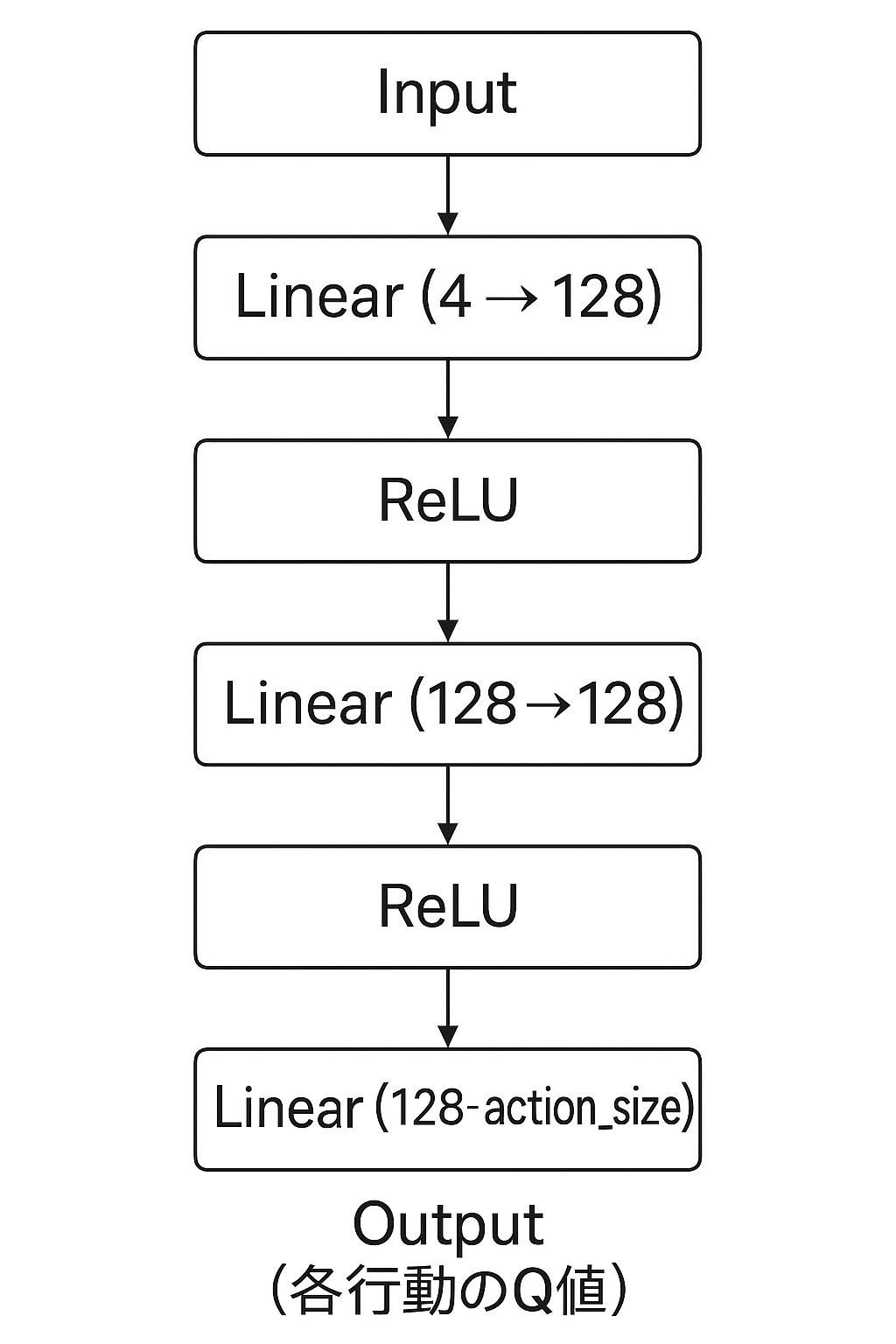
活性化関数としてはReLUを使っています。シンプルで勾配消失問題を緩和できるので、深層学習ではよく使われます。
$$ReLU(x)=max(0,x)$$
経験再生バッファ
class ReplayBuffer:
def __init__(self, buffer_size, batch_size):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
return len(self.buffer)
def get_batch(self):
data = random.sample(self.buffer, self.batch_size)
state = torch.tensor(np.stack([x[0] for x in data]))
action = torch.tensor(np.array([x[1] for x in data]).astype(np.int64))
reward = torch.tensor(np.array([x[2] for x in data]).astype(np.float32))
next_state = torch.tensor(np.stack([x[3] for x in data]))
done = torch.tensor(np.array([x[4] for x in data]).astype(np.int32))
return state, action, reward, next_state, done
こちらは過去の経験をためておけるバッファで、各ステップごとのstate, action, reward, next_state, doneを蓄積することができます。そしてget_batchでバッチサイズ分だけランダムに取り出すことができるクラスです。
エージェントクラス
class DQNAgent:
def __init__(self):
self.gamma = 0.98
self.lr = 0.0005
self.epsilon = 0.1
self.buffer_size = 10000
self.batch_size = 32
self.action_size = 2
self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size)
self.qnet = QNet(self.action_size)
self.qnet_target = QNet(self.action_size)
self.optimizer = optim.Adam(self.qnet.parameters(), lr=self.lr) #最適化アルゴリズムとしてAdamを使用
def get_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.choice(self.action_size)
else:
state = torch.tensor(state[np.newaxis, :])
qs = self.qnet(state)
return qs.argmax().item() #Q値の高いほうのインデックスを返す
def update(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
if len(self.replay_buffer) < self.batch_size:
return
state, action, reward, next_state, done = self.replay_buffer.get_batch()
qs = self.qnet(state)
q = qs[np.arange(len(action)), action]
next_qs = self.qnet_target(next_state)
next_q = next_qs.max(1)[0]
next_q.detach()
target = reward + (1 - done) * self.gamma * next_q
loss_fn = nn.MSELoss() #損失関数として平均二乗誤差を使用
loss = loss_fn(q, target) #Q値とターゲットQ値の誤差を計算
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def sync_qnet(self):
self.qnet_target.load_state_dict(self.qnet.state_dict())
get_actionで次のアクションを推論します。ε-greedyにより、今回は10%の確率でランダムに探索を行います。順伝搬で入力するstateの形ですがtorch.Size([バッチサイズ, stateの次元数])となっていますので、整形します。(データの整形に結構苦労します泣)
updateでは、経験再生バッファを使って学習を行います。流れは、Q-networkで現在の状態での推論したQ値とTD-networkで推論したターゲットQ値を求めて、この2つの誤差を最小にするというのがDQNの学習の流れです。誤差を小さくしていくことで、トータルの報酬が大きくなります。
ハイパーパラメーターは次の通りです。
| HP | 値 | 備考 |
|---|---|---|
| 学習率(lr) | 0.0005 | ネットワークの重みをどれだけ更新するかを決定するパラメータ |
| 割引率(gamma) | 0.98 | 割引率は将来の報酬をどれだけ重視するかを決める値 |
| epsilon | 0.1 | どれくらいの確率で探索を行うか |
| 経験再生バッファサイズ | 10000 | |
| バッチサイズ | 32 | バッチサイズは経験リプレイバッファから何件のサンプルを使ってネットワークを更新するか |
| 同期タイミング(sync_interval) | 20 | Q-networkとTD-networkの同期インターバル |
それぞれのパラメータは学習に大きく影響するので、調整が必要です。
学習のループ
episodes = 300
sync_interval = 20
env = gym.make('CartPole-v1')
agent = DQNAgent()
reward_history = []
for episode in range(episodes):
state, _ = env.reset()
done = False
total_reward = 0
while not done:
action = agent.get_action(state)
next_state, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
done = True
agent.update(state, action, reward, next_state, done)
state = next_state
total_reward += reward
if episode % sync_interval == 0:
agent.sync_qnet()
reward_history.append(total_reward)
今回は300エピソード学習を行いました。
5. 学習結果
学習結果を合計報酬の20回の移動平均としてグラフとしました。

120エピソードあたりから急激に学習が進み、後半下がり気味ですが、トータル良い結果となりました!
学習初期段階↓

初期段階はカクカクしていますが、これは一瞬でゲームオーバーとなってしまい、ゲームを繰り返している様子です。
300回学習後の結果↓

学習後は、長い時間持ちこたえているようです。強化学習がうまくいっている様子が見えました!
6. まとめ
今回はDQNをCart-Poleに適応させてみました。ハイパーパラメータやネットワークの構成、強化学習のアルゴリズムなど、いろいろといじってみるのも面白そうですね。
DQNは強化学習における大きな一歩をもたらしましたが、・自動運転などの連続的なアクションに対応できない ・Q値を過大評価してしまい学習が不安定になる ・ε-greedyの探索は非効率などといった課題があります。これらを解決する手法は既に提案されていますので、今後試したものを記事にできたらと思います!
参考
ゼロから作るDeep Learning 4 ―強化学習編 (斎藤 康毅, 2022)