はじめに
仕事が終わった後、友達とゲームを楽しむ時間は自分にとって至福のひとときです。対戦ゲームで試合に勝つことも大切ですが、どうせなら友達と楽しく遊びたいですよね。ふと自分の発言がみんなの雰囲気を悪くしていないか、めちゃくちゃ興味が湧きました。
そんな疑問を解決すべく自分の音声を録音し、それをS3バケットにアップロードするだけで発言に対する感情分析を行う処理をAWSで作ってみました!TranscribeとComprehendの機能を学んだ時から、これはやるしかないと思っていました。これにより自分の発言に含まれている感情を検出し、ネガティブな雰囲気を作っていないか確認することができるのです。
作ったもの
テストデータとして以下の文章を読み上げ、その音声を録音しました。
今回は、あえてネガティブな発言を多く含めてみました。
敵が強くて全然勝てない。自分が弱すぎてマジで勝てない。本当、みんなに迷惑かけてしまって申し訳ない
録音した音声ファイル(MP3)を音声保管用のS3バケットにいれると自動的に感情分析が行われます。感情分析の結果が保存されているS3バケットを確認すると、自分の意図通りネガティブのSentimentScoreが最も高く判定されました。後述しますが、今回は一度Amazon Transcribeを用いて音声ファイルをテキストデータ化した後に感情分析を行っています。ハキハキと喋ったからかもしれませんが、こちらも高い精度で認識してくれました。
{"File": "extract_for_sentiment_20241224142222.txt", "Line": 0, "Sentiment": "NEGATIVE", "SentimentScore": {
"Mixed": 4.521481241681613e-05,
"Negative": 0.9772326350212097,
"Neutral": 0.018661685287952423,
"Positive": 0.0040604970417916775
}}
敵が強くて全然勝てない。自分が弱すぎて街で勝てない。本当、みんなに迷惑かけてしまって申し訳ない
またタイトルにもあるように実際の対戦ゲーム中の自分の発言を録音した音声ファイルを入れてみました。結果、混在している割合が多かったものの、よく見るとPositiveよりもNegativeのほうが圧倒的にSentimentScoreは高かったので、もっとポジティブなことを言おうと改めるきっかけになりました。ちなみに大敗しているときに録音したものです。
{"File": "extract_for_sentiment_20241224170112.txt", "Line": 0, "Sentiment": "MIXED", "SentimentScore": {
"Mixed": 0.7946255803108215,
"Negative": 0.16967645287513733,
"Neutral": 0.021081753075122833,
"Positive": 0.014616201631724834
}}
構成図
この処理は大きく3つの要素で構成されています。
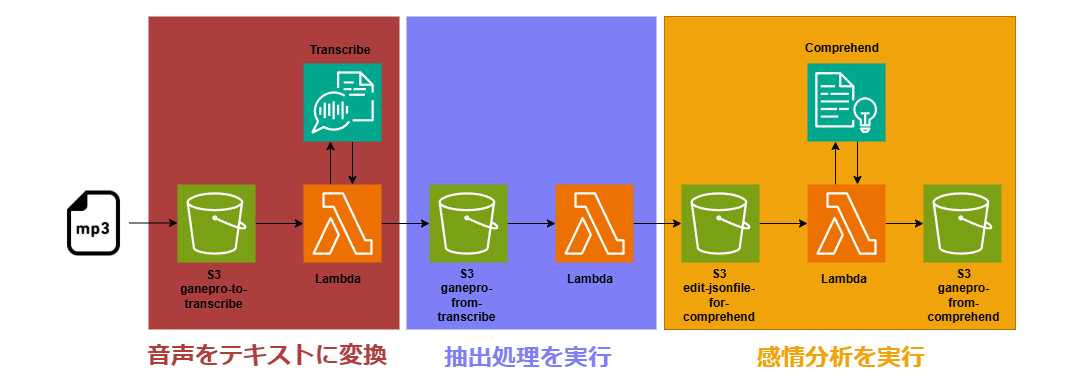
①音声をテキストに変換する
感情分析を実施するAmazon Comprehend(以後Comprehend)は音声データを扱うことは出来ないため一度テキストデータ化する必要があります。そのためAmazon Transcribe(以後Transcribe)を利用して音声データをテキストデータに変換します。ここでは特定のS3バケットに音声ファイルをアップロードすると、Transcribeを呼んでテキストデータに変換後、別のS3バケットに保存するLambdaが起動するようにします。
②テキストデータから分析に必要な箇所のみを抽出する
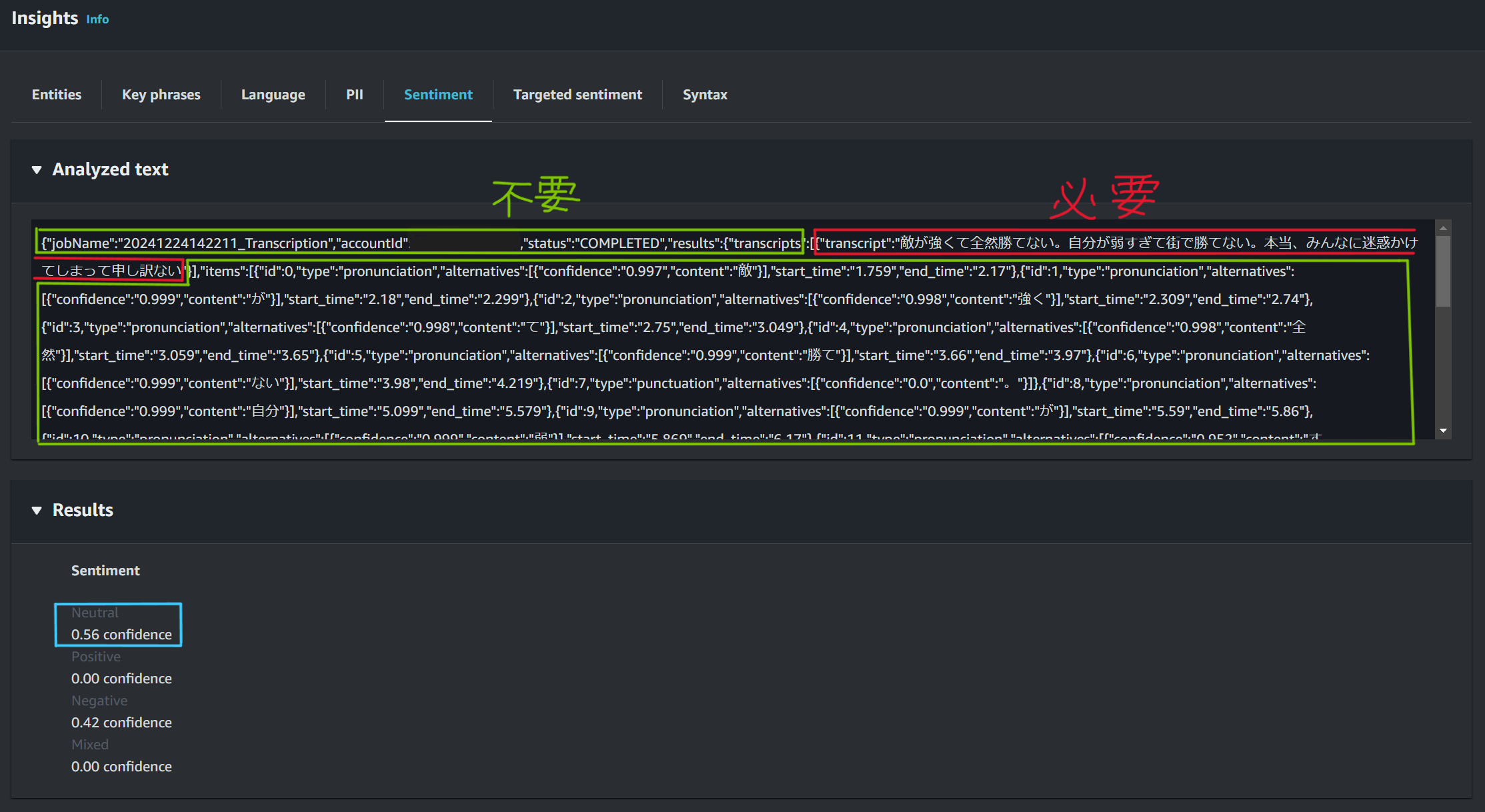
Transcribeで音声データをテキストデータに変換後、出力された結果をComprehendでそのまま感情分析に利用すると、正しい結果を取得できない可能性があります。なぜならTranscribe実行後に出力されるJSONファイルには実際に発言した内容を文字に起こしたtranscript以外にも、文字に含まれる単語やフレーズ、開始時間や終了時間を記録したItemという関連属性なども含まれているからです。ComprehendのReal-time analysisにて出力結果すべてを感情分析に利用した場合と、出力結果のうち発言内容を文字に起こしたtranscriptのみを感情分析に利用した場合とで感情分析の結果に大きな違いが出ることを確認できます。
Transcribeからの出力内容すべてを、感情分析に利用する
中立的を意味するNeutralのスコアが0.56と最も高くなる。
発言内容を文字に起こしたtranscriptのみを、感情分析に利用する
否定的を意味するNegativeのスコアが0.97と最も高くなる。
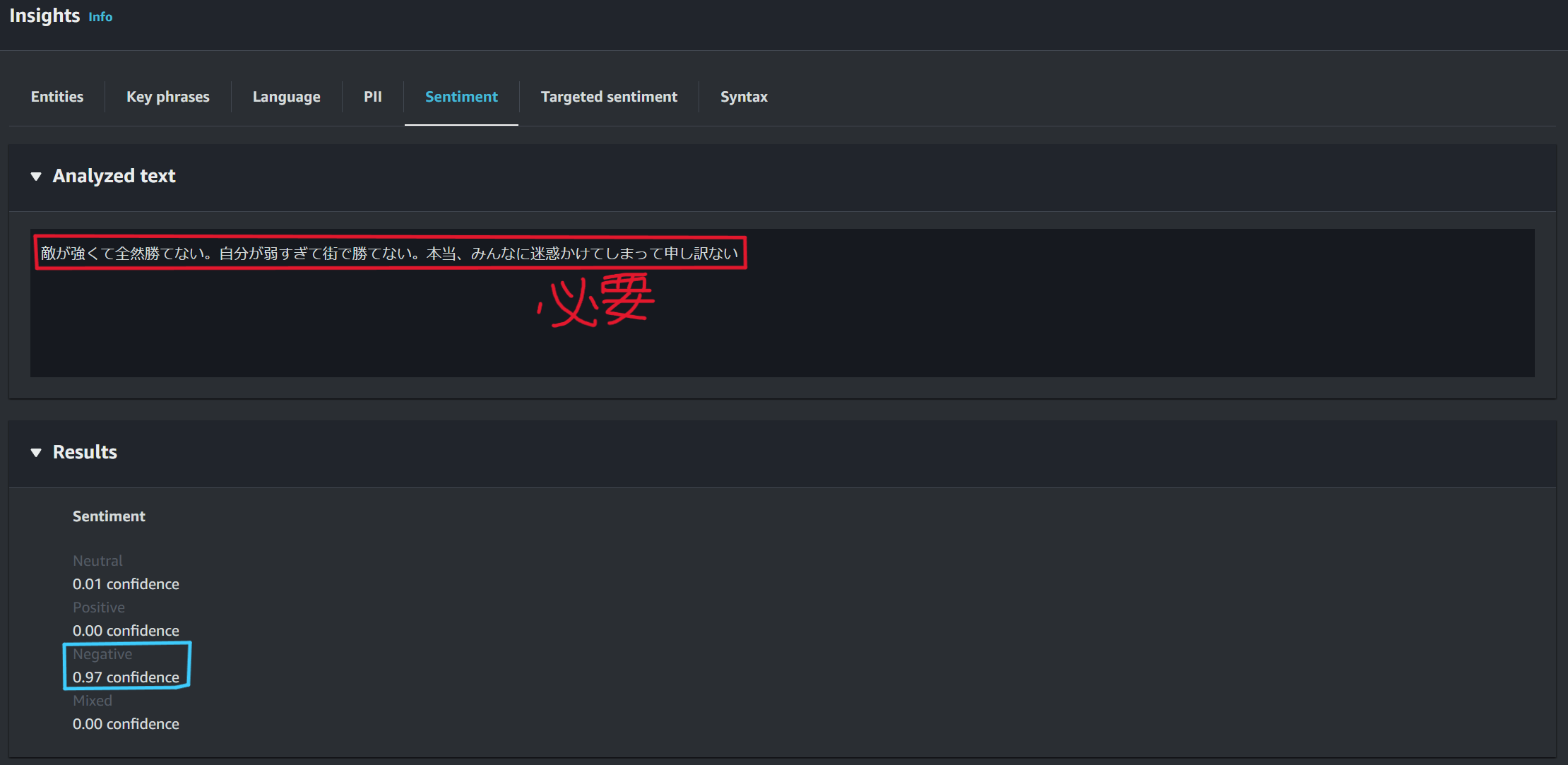
この結果から、自分の発言を正確に感情分析するには、音声データをTranscribeでテキストデータ化したJSONファイルの中からtranscriptのみを抽出する作業が必要となります。ここではTranscribe実行後に出力されるJSONファイルがS3に保存されるとtranscriptのみを抽出して別のS3バケットへ保存するLambdaが起動するようにします。
③感情分析を実行する
今回作りたかった仕組みのメイン処理部分です。ここではtranscriptのみが抽出されたテキストデータが特定のS3バケットに保存されると、Comprehendによる感情分析を行いその結果を別のS3バケットへ保存するLambdaが起動するようにします。
詳細
①音声をテキストに変換する
面倒な議事録をAWS Transcribeを利用した自動文字起こしの構築
Lambda・Transcribeを利用してS3にアップロードした音声ファイルをテキストデータに変換する方法はこの記事が分かりやすいです。この記事を参考に自分は、ganepro-to-transcribeバケットに音声ファイルをアップロードすると、結果がganepro-from-transcribeバケットに保存されるようLambdaのコードやトリガーを設定をしました。CloudWatchのログストリームから作成したLambdaのログは確認可能なので、うまくいかない場合はエラーメッセージを確認しましょう。以下のキャプチャのように音声ファイルをアップロードしてから少しして、出力先のバケットにJSONファイルが生成されたら成功です。
音声ファイルを保存する ganepro-to-transcribeバケット
Transcribeで変換処理後、保存される ganepro-from-transcribeバケット
{
"jobName": "20241224142211_Transcription",
"accountId": "{自身のアカウントID}",
"status": "COMPLETED",
"results": {
"transcripts": [
{
"transcript": "敵が強くて全然勝てない。自分が弱すぎて街で勝てない。本当、みんなに迷惑かけてしまって申し訳ない"
}
],
"items": [
{
"id": 0,
"type": "pronunciation",
"alternatives": [
{
"confidence": "0.997",
"content": "敵"
}
],
警告
Transcribeの無料枠は3600秒のため、テストする際にアップロードする音声ファイルの容量には注意してください。自分は誤って録音時間の長いファイルをアップロードし続けて、無料枠を使い切ってしまいました。
②テキストデータから分析に必要な箇所のみを抽出する
【AWS;Lambda入門】第二弾;jsonファイルから文章抽出してS3保存♬
PythonでJSON 読み込み
前述したようにComprehendの感情分析では、実際に発言した内容を文字に起こしたtranscriptのみを利用したい為、ganepro-from-transcribeバケットにアップロードされたJSONファイルに対して抽出処理が必要です。上の記事を参考にganepro-from-transcribeバケットのオブジェクト生成イベントをトリガーとして、JSONファイルからtranscriptのみを抽出し、結果をedit-jsonfile-for-comprehendバケットへ保存するようLambdaのコードを設定しました。結果が保存されているS3バケットを確認すると、transcriptに記載されている内容のみが抽出されていることが確認できます。
感情分析で利用するデータを保存する edit-jsonfile-for-comprehendバケット
音声ファイルをテキストデータにして、感情分析に必要なデータのみを抽出したもの

③Comprehendで感情分析を実行する
①と②によって自分の発言を文字起こしした結果のみがedit-jsonfile-for-comprehendバケットに保存されます。この内容を利用した感情分析を行えば目的が達成できるので、edit-jsonfile-for-comprehendバケットのオブジェクト生成イベントをトリガーとして、文字起こしした内容を利用した感情検出ジョブを実行し、結果をganepro-from-comprehendバケットに保存するようなLambdaのコードを設定しました。類似事例が見つけられなかった為、Boto3ドキュメントを参考にLambdaのコードを書いてみました。
import json
import urllib.parse
import boto3
import datetime
print('Loading function')
s3 = boto3.client('s3')
comprehend = boto3.client('comprehend')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
comprehend.start_sentiment_detection_job(
InputDataConfig={
'S3Uri': 's3://' + bucket + '/' + key,
},
OutputDataConfig={
'S3Uri': 's3://ganepro-from-comprehend',
},
DataAccessRoleArn='{入力データへの Amazon Comprehend の読み取りアクセスを許可する IAM ロールの Amazon リソースネーム (ARN)}',
JobName= datetime.datetime.now().strftime('%Y%m%d%H%M%S') + '_Comprehend',
LanguageCode='ja'
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
ComprehendのAnalysis jobs画面から、実行したジョブの詳細を確認すると感情分析の入力データとして①②を経て抽出されたデータを利用していることと、出力データとしてLambdaで指定したバケットに保存されていることが分かります。該当ファイルをダウンロードすると、感情分析の結果が確認できるようになります。
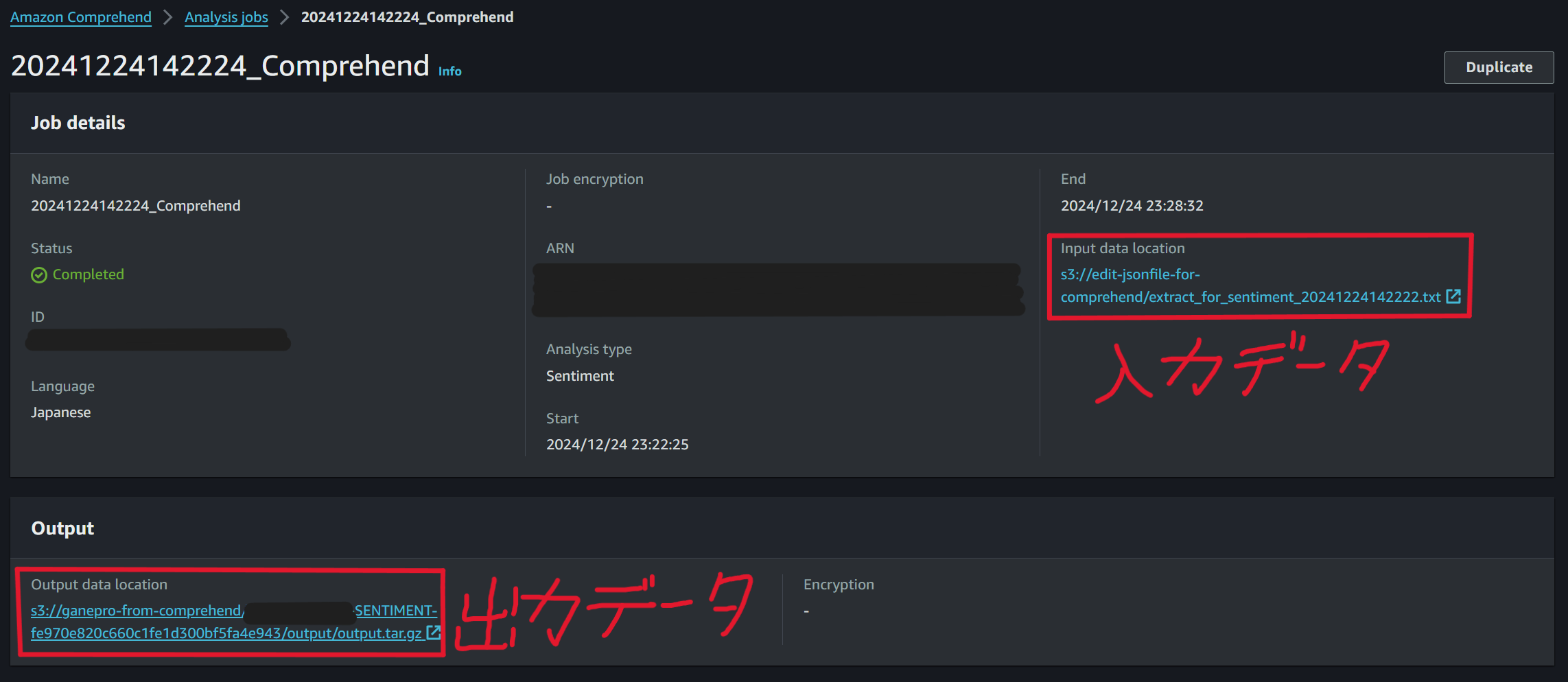
感情分析の結果を保存する ganepro-from-comprehendバケット
{"File": "extract_for_sentiment_20241224142222.txt", "Line": 0, "Sentiment": "NEGATIVE", "SentimentScore": {
"Mixed": 4.521481241681613e-05,
"Negative": 0.9772326350212097,
"Neutral": 0.018661685287952423,
"Positive": 0.0040604970417916775
}}
以上で、S3バケットに音声ファイルをアップロードすると発言に対する感情分析を行う一連の処理を作成することが出来ました。類似事例も多く初めての開発としては非常に助かりました。改善点としてLambdaに付与するIAMロールについては、エラーログが表示されてからその場で付与するというケースが多く、今後に向けてあらかじめどういう権限が必要なのかを自分で判断してから最低限かつ漏れなく付与できるようになりたいと思いました。
学び
今回、開発してみて学んだことは以下の2つです。
- 創作意欲は経験によるスキルを超越することもある
- ふとした疑問にも真剣に向き合うために多くの知識を身につけることの重要性
実はAWSの複数のサービスを組み合わせて何かを作るという経験は初めてでした。AWSはまだ知識も十分ではないし、コードもほとんど書いた経験がなかったのでできるのかなと不安になりながら、最初は作っていました。しかしQiitaに積み上がったエンジニアの知恵やいろいろなサイトをめちゃくちゃ調べながら、作りたいものが実現できた時はとても嬉しく達成感を感じました!1週間ぐらい飽きずに仕事終わりも開発に熱中できたのは間違いなく創作意欲が爆発したからだと思っています。
どうすればまた創作意欲が爆発するんだろうと思ったときにいろいろな疑問に対して答えられる知識が今の自分にあることが重要だと考えました。今回はゲーム中の自分の発言の傾向という、ふとした疑問に対するアンサーとしてたまたま学んでいたAWSの知識が活かせるのではないかと当時気づたからこそ、自分でやってみるしかない!と創作意欲が爆発したのではないかと考えています。自分は新しい知識を取り入れることが好きなので、なおさら嬉しい発見でした。
この経験を大切に、今後も遊び心のある開発を続けて行きたいなと思いました。
記事が良かった・参考になったと思ったらいいね!を付けてくれると嬉しいです!